









文章目录
二, HBase 进阶
2.1 Hbase 的物理架构
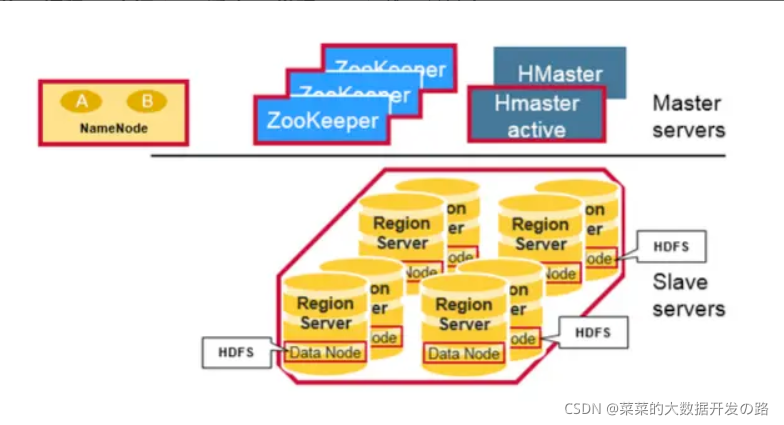
物理上, HBase是由三种类型的Server组成的主从式(master-slave)架构:
1. RegionServer (HRigionServer)
[概述]
在HDFS中, DataNode负责存储实际数据, RegionServer主要负责响应用户的请求, 向HDFS读写数据; 所以在分布式集群中, RegionServer一般运行在DataNode服务器上, 实现数据的本地性;
[功能总结]
RegionServer 维护Master分配给它的Region:1.直接处理Client对这些Region的IO请求;
2.刷写MemStore到HDFS中;
3.同时对在运行过程中变得很大的Region进行split操作;
4.负责对超过文件个数阈值的store文件进行Compact 操作;
2. HBase Mater(HMaster)
[概述]
- 在分布式集群中, HMaster服务器通常运行在 HDFS的NameNode上,
- HMaster 通过Zookeeper 来避免单点故障, 在集群中可以启动多个HMaster, Zookeeper的选举机制能够保证同时只有一个HMaster处于Active状态, 其他的HMaster处于热备份状态;
[功能总结]
HMaster 主要负责表和Region的管理工作
- 管理用户对表的
增删改查操作(DDL);- 管理
RegionServer的负载均衡, 平衡Region在分布式系统中的分布, 包括对Region的切片分配和移除;- 处理
RegionServer的故障转移;
扩展:

3. Zookeeper
[概述]
[功能总结]
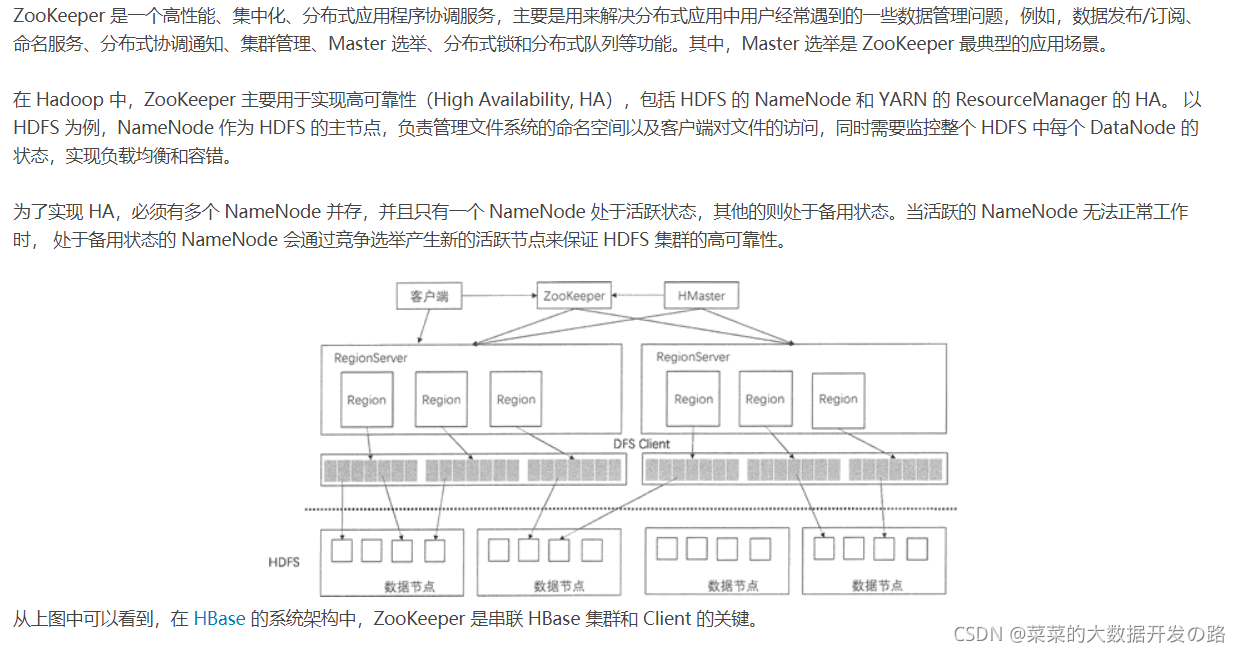
HBase利用ZooKeeper维护集群中服务器的状态并协调分布式系统的工作
- Master选举:
- 同HDFS的HA机制一样, HBase集群中也有多个HMaster共存, 通过竞争选举机制保证统一时刻只有一个HMaster 处于活跃状态, 一旦这个 HMaster无法使用, 则从备用master节点中选出一个顶上, 保证集群的高可用性(HA-hign avbility)
- 在第一个HMaster连接到ZooKeeper时会创建Ephemeral节点(默认:/hbasae/master)来表示Active的HMaster,其后加进来的HMaster则监听该Ephemeral节点
- 容错机制:
- 在HBase启动时, 每个RegionServer在加入集群时都需要在Zookeeper中进行注册, 创建一个状态节点, Zookeeper会时时监控每个RegionServer的状态, 同时HMaster 会监听这些注册的RegionServer;
- 当某个RegionServer 挂掉的时候, Zookeeper 会因为一段时间接收不到它的信条信息而删除该RegionServer 对应的状态节点, 并且会给HMaster 发送节点删除的通知, 这时HMaster获知集群中某个节点断开, 会立即调度其他节点开启容错机制;
- Region 状态管理:
- HBase 集群中 Region 会经常发生变动, 原因可能是系统故障转移, 配置修改, 或者是Region的切分和合并, 只要Region发生变化, 就需要让集群的所有节点知晓, 否则会出现某些事务性的异常; 对于HBase集群, 相当多的Region 如果都交给HMaster做状态管理的话, HMaster 的负担会很重, 所以只有依靠Zookeeper集群来完成;
- Region 元数据的管理:
- 在HBase集群中, Region 元数据被存储在Mete表中, 每次客户端发起新的请求时, 需要查询Meta表来获取Region的位置;
- 当 Region 发生变化时,例如,Region 的手工移动、进行负载均衡的移动或 Region 所在的 RegionServer 出现故障等,就能够通过 ZooKeeper 来感知到这一变化,保证客户端能够获得正确的 Region 元数据信息。
- 提供Meta表的存储位置:
- 在HBase集群中, 数据库的表信息, 列族信息及列族存储信息都属于元数据, 这些原数据存储在Meta表中, 而Meta表的位置入口由Zookeeper来提供;
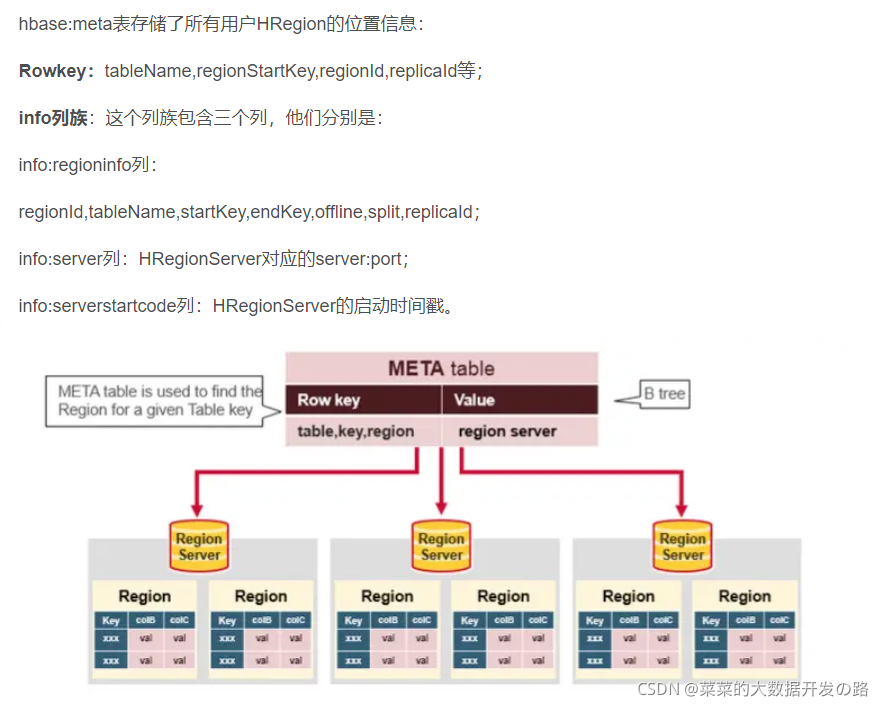
扩展: 什么是Meta Table?
Meta Table(hbase:meta),它存储了集群中所有用户HRegion的位置信息,而ZooKeeper的节点中(/hbase/meta-region-server)存储的则直接是这个Meta Table的位置,并且这个Meta Table如以前的-ROOT- Table一样是不可split的。这样,客户端在第一次访问用户Table的流程就变成了:
1. 客户端从zk中获取保存meta table的位置信息,知道meta table保存在了哪个region server,并在客户端缓存这个位置信息;
2. client会查询这个保存meta table的特定的region server,查询meta table信息,在table中获取自己想要访问的row key所在的region在哪个region server上。
3. 客户端直接访问目标region server,获取对应的row
注:客户会缓存这些位置信息,然而第二步它只是缓存当前RowKey对应的HRegion的位置,因而如果下一个要查的RowKey不在同一个HRegion中,则需要继续查询hbase:meta所在的HRegion,然而随着时间的推移,客户端缓存的位置信息越来越多,以至于不需要再次查找hbase:meta Table的信息,除非某个HRegion因为宕机或Split被移动,此时需要重新查询并且更新缓存。
参考文章:
- https://blog.csdn.net/weixin_33964094/article/details/92441365
- http://c.biancheng.net/view/6510.html
- https://segmentfault.com/a/1190000019959411
4. Q: 上面的三种组件是如何一起工作的?
每个Region Server 都会创建一个ephmeral 节点, HMaster 会监控这些节点来发现可用的Region Servers, 同时他也会监控这些节点是否出现故障;
HMaster 们会竞争创建 ephemeral 节点,而 Zookeeper 决定谁是第一个作为在线 HMaster,保证线上只有一个 HMaster。活动HMaster(active HMaster) 会给 Zookeeper 发送心跳,非活动HMaster (inactive HMaster) 会监听 active HMaster 可能出现的故障并随时准备上位。
如果有一个 Region Server 或者 HMaster 出现故障或各种原因导致发送心跳失败,它们与 Zookeeper 的 session 就会过期,这个 ephemeral 节点就会被删除下线,监听者们就会收到这个消息。Active HMaster 监听的是 region servers 下线的消息,然后会恢复故障的 region server 以及它所负责的 region 数据。而 Inactive HMaster 关心的则是 active HMaster 下线的消息,然后竞争上线变成 active HMaster
2.2 RegionServer的组成
- HRegionServer包含多个HRegion,由WAL(HLog)、BlockCache、MemStore、HFile组成。
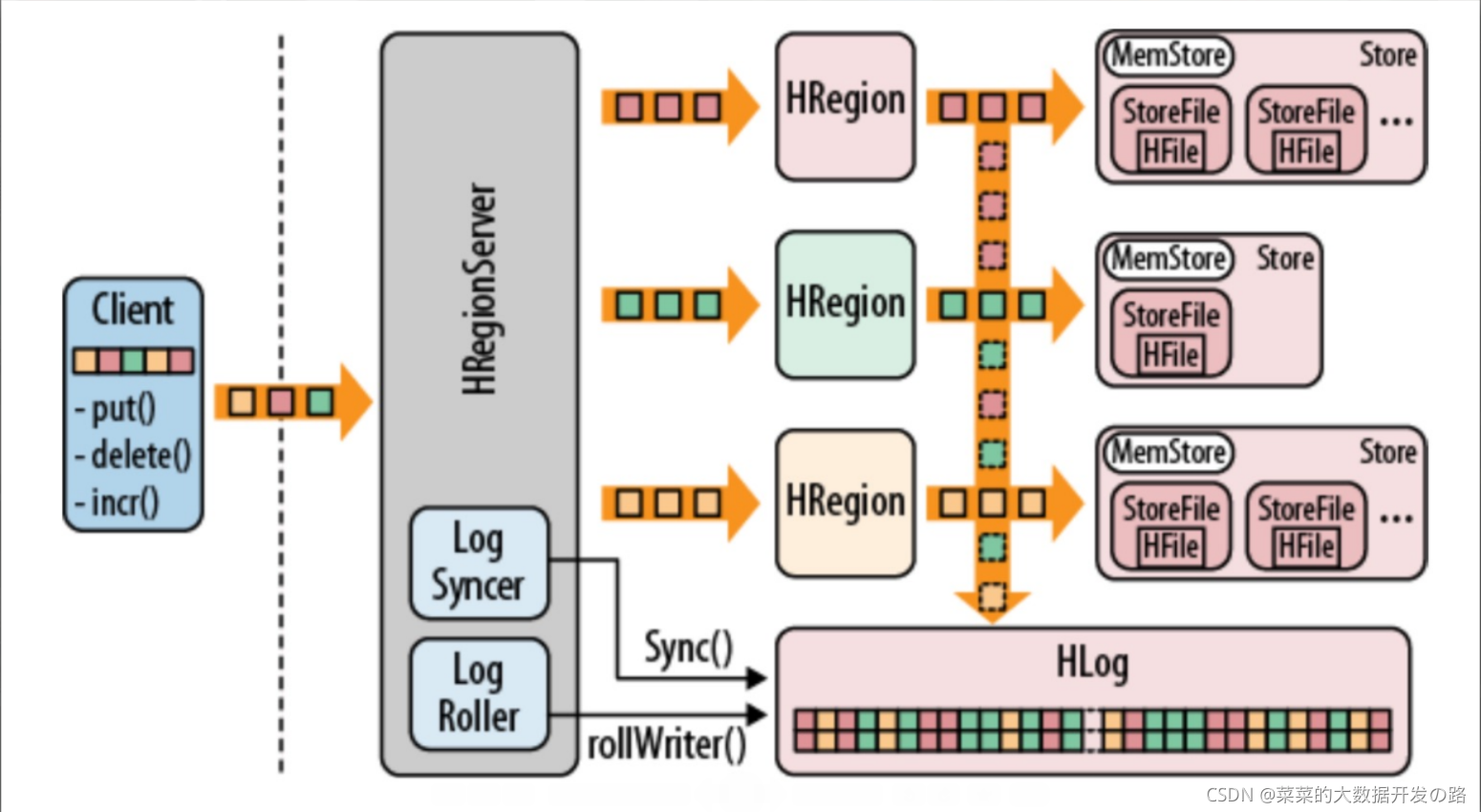
- WAL
HBase的Write Ahead Log (WAL)提供了一种高并发、持久化的日志保存与回放机制。每一个业务数据的写入操作(PUT / DELETE)执行前,都会记账在WAL中。
- 由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,操作记录会先写到一个叫做 Write-Ahead logfile 的文件中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重
建。 (HBase中WAL的实现类是HLog)
[具体操作: ]
首先,客户端初始化一个可能对数据改动的操作,如put(Put),delete(Delete) 和 incrementColumnValue()。这些操作都将被封装在一个KeyValue对象实例中,通过RPC 调用发送给HRegionServer(最好是批量操作)。 一旦达到一定大小,HRegionServer 将其发送给HRegion。这个过程中,数据会首先会被写入WAL,之后将被写到实际存放数据的MemStore中。当MemStore到达一定大小,或者经过一段时间后,数据将被异步地写入文件系统中
- MemStroe
- 写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机(memStore的大小达到一个阀值(默认128MB))才会刷写到 HFile,每次刷写都会形成一个新的 HFile。
- StoreFile
- memStore内存中的数据写到文件后就是StoreFile,保存实际数据的物理文件,
- StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有一个或多个 StoreFile(HFile),
- 数据在每个 StoreFile 中都是有序的。
- HFile
HBase中KeyValue数据的存储格式,HFile是Hadoop的 二进制格式文件,实际上StoreFile就是对Hfile做了轻量级包装,即StoreFile底层就是HFile
Store: 每个Region的每个列簇在底层存储为一个Hfile。
补充文章:
https://www.cnblogs.com/qingyunzong/p/8692430.html
2.3 HBase 的 写流程
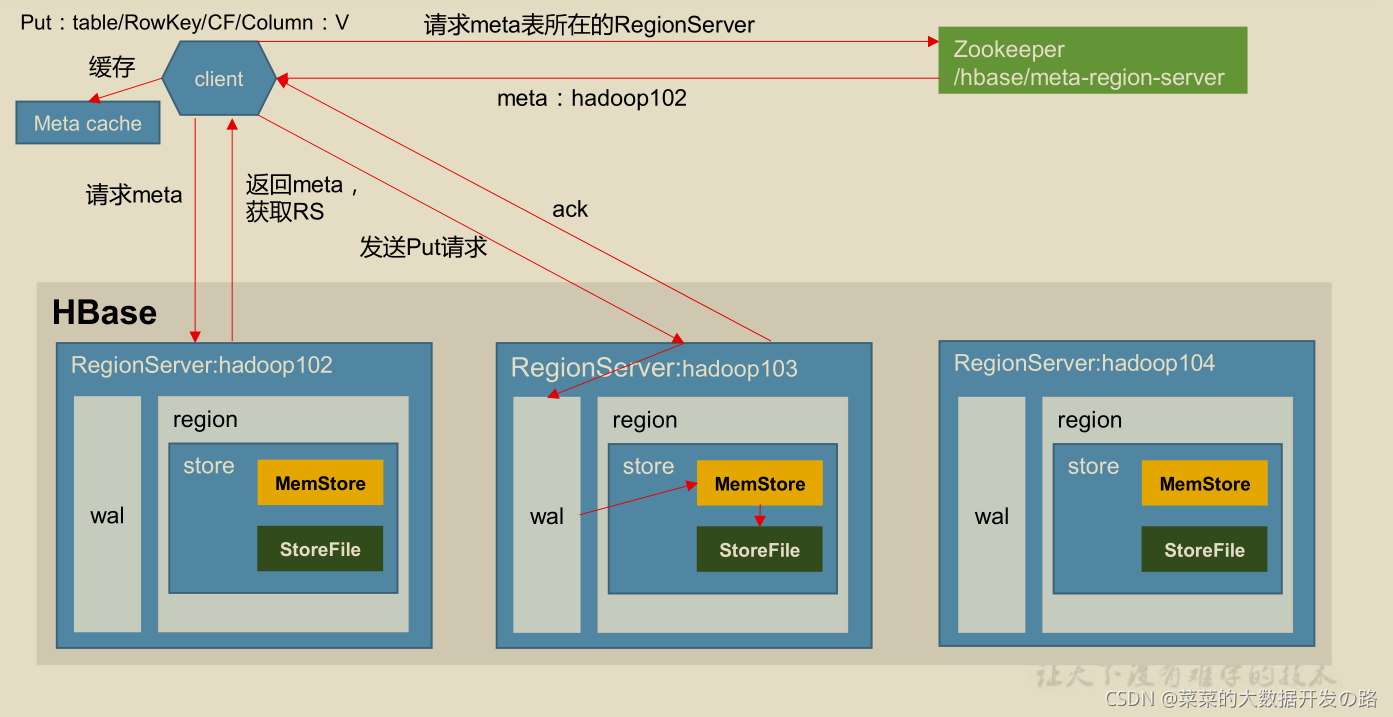

client–>zk–>regionserver–>region–>追加到wal–>memstore–>ack–>flush
2.3.1 MemStore Flush 的时机
2.4 HBase 的读流程
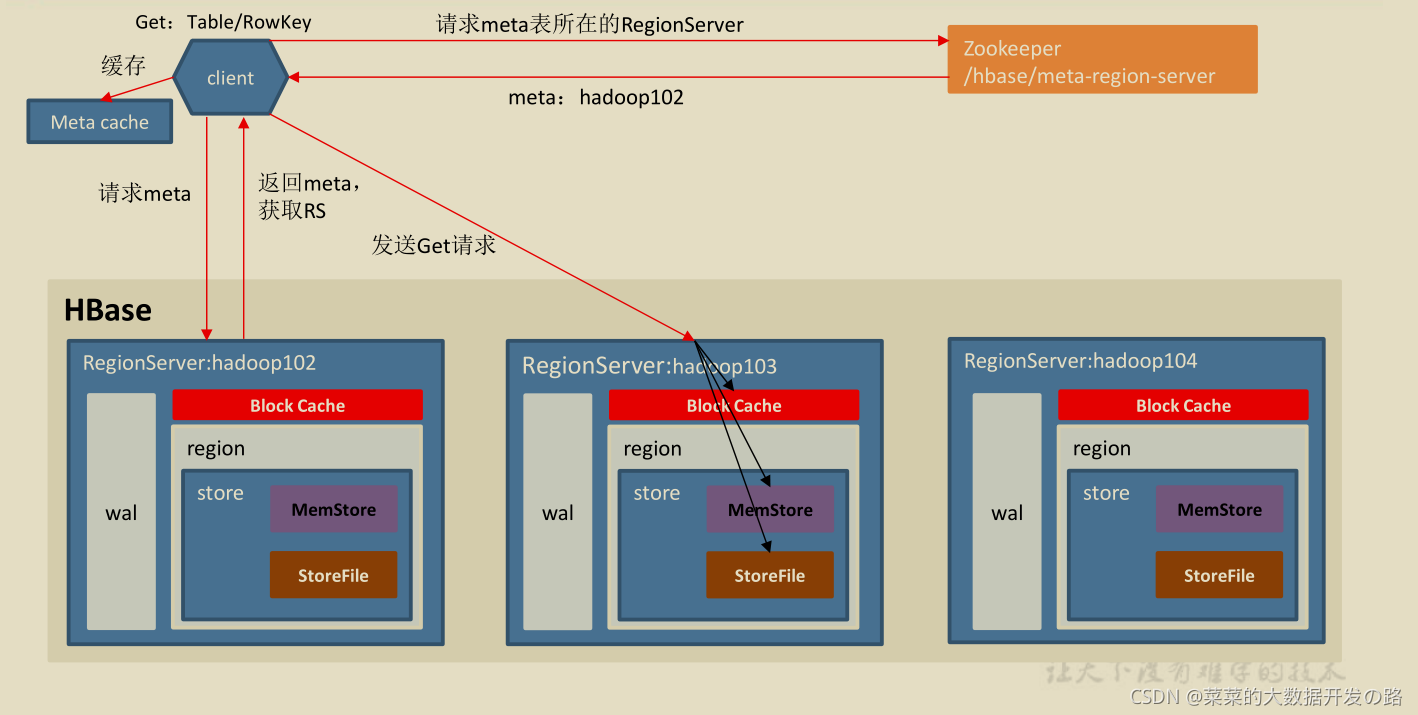

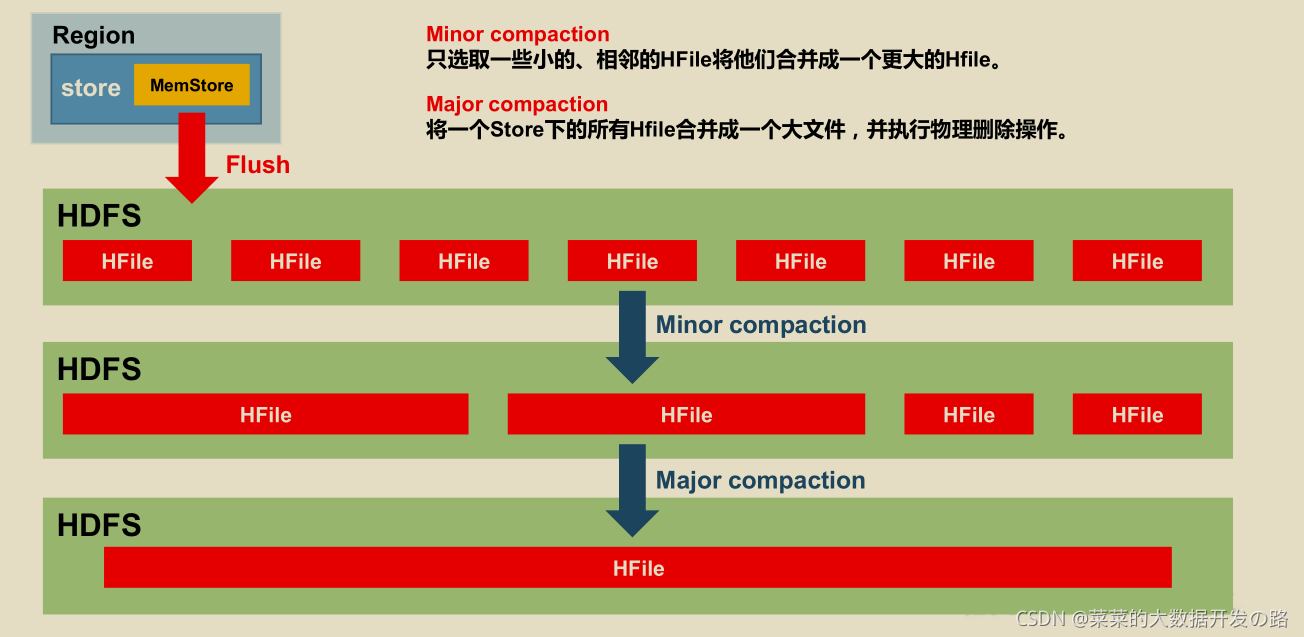
2.4.1 StoreFile Compaction
- 由于memstore 每次刷写都会生成一个新的HFile, 且同一个字段的不同版本(timestamp)和不同类型(put/delete) 有可能会分布在不同的HFile中, 因此查询时需要遍历所有的HFile.
- 为了减少HFile 的个数, 以及清理掉过期和删除的数据, 会进行StoreFile Compaction;
HFile 的compaction 分为两种, 分别是
Minor Compactiomn和Major Compaction,
- Minor Compaction (较小–> 较大, 不删除), 会将临近的若干个较小的HFile 合并成一个较大的HFile, 但不会清理过期和删除的数据;
- Major Compaction (所有–>大, 会删除)会将一个Store 下的所有的HFile 合并成一个大HFile, 并且会清理掉过期和删除的数据;
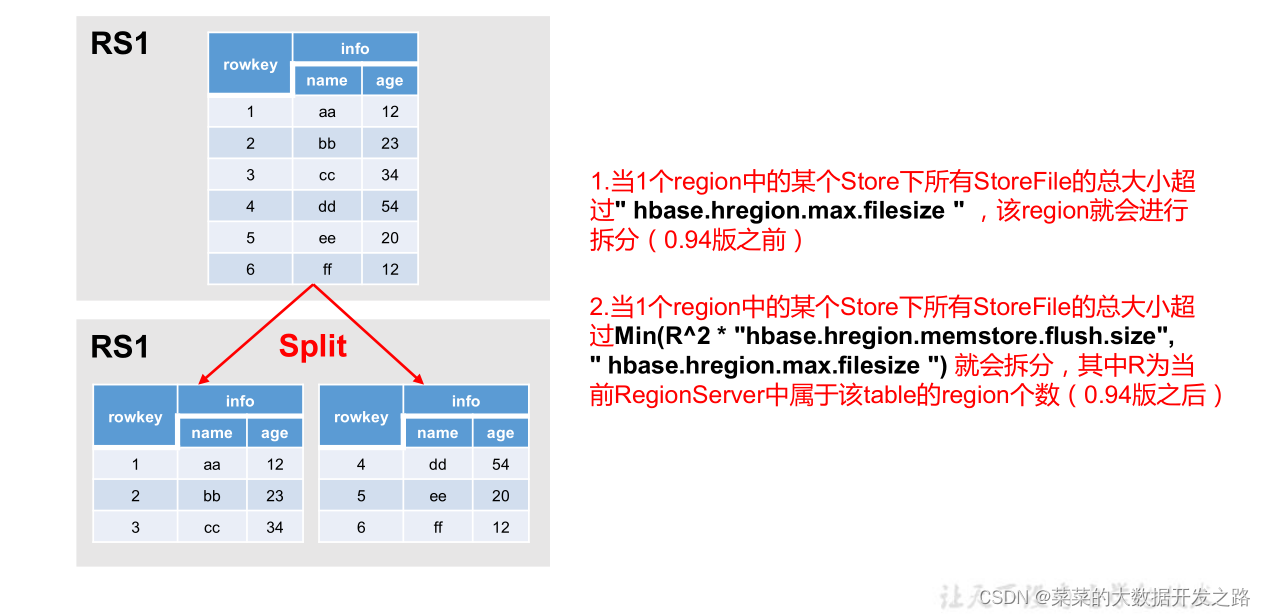
2.4.2 Region Split
- 默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进行拆分。
- 刚拆分时,两个子 Region 都位于当前的 Region Server,
- 但处于负载均衡的考虑,HMaster 有可能会将某个 Region 转移给其他的Region Server。
Region Split 的时机
1.当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize,
该 Region 就会进行拆分(0.94 版本之前)。
2.当 1 个 region 中 的某 个 Store 下所有 StoreFile 的总 大 小超过Min(R^2 * "hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize"),该 Region 就会进行拆分,其中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。














 89
89











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









