




【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 单/多线程分析(二)
对 Python http.server 模块多线程启动做了测试,并分析了从 Python v3.7 版本之后开始默认使用多线程启动,在 v3.7 之前还是单线程启动,下面继续
Python http.server 单/多线程分析
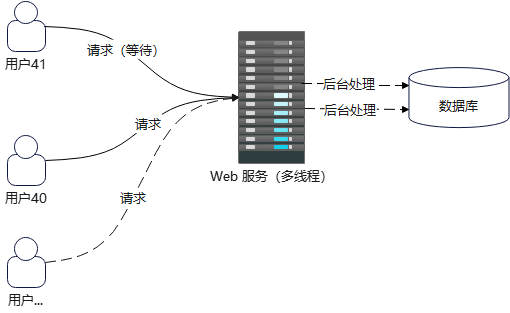
OK,之前 blog 分析完 http.server 的单线程和多线程模型,然后简单分析了下其历史,当前默认的是使用多线程模型,其结构大致如下
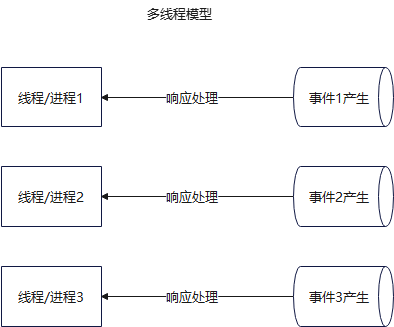
其无法支持高并发能力,主要体现在两个方面:线程本身是阻塞的,多线程本身的资源消耗
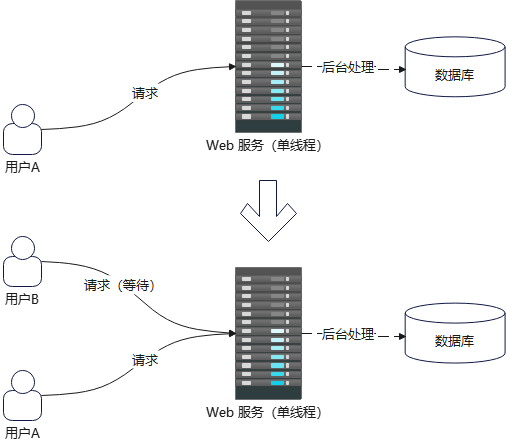
首先看第一点:线程本身是阻塞的,这一点在之前分析 http.server 模块单线程的时候就已经说过,当 A 请求占用 Web 服务线程资源进行处理时,B 请求想要访问只能等待
虽然这一现象在多线程模型中得到缓解
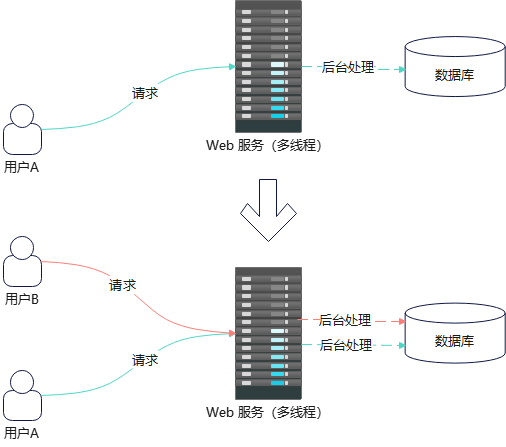
但这是通过新增线程来缓解的,对于多线程中的具体线程而言,其本质还是阻塞式的,一旦并发请求量导致的新增线程达到服务器上限,其最终效果还是会体现为被阻塞,响应慢,比如,当前 http.server 模块规定的多线程默认最多只能支持 40 个线程(在 socketserver.py 模块中定义)
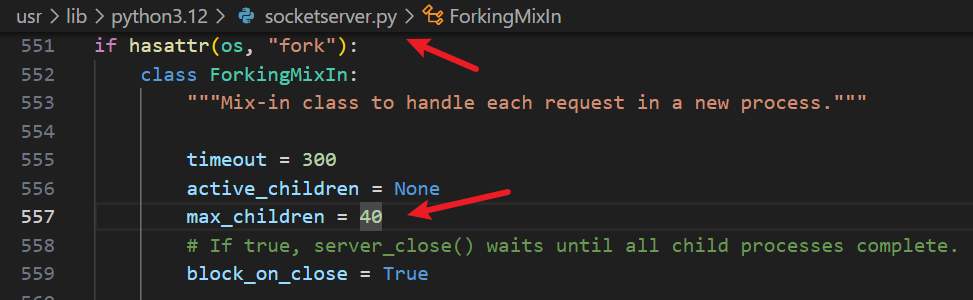
一旦并发请求的数量超过 40 个,那么第 41 个请求由于已达新建线程的上限,就不得不需要等待前面某个请求完成后,才能处理这第 41 个请求,那么这又回到了单线程遇到的问题,所以说这只能缓解,并不能真正解决高并发问题
OK,这时候有人说,那把这 40 给他改大一点不就行了吗?提高 http.server 模块能够处理的上限,下面来分析看不断提高上限会带来什么结果
- 首先,每个线程都需要开辟栈空间的,这里要和进程区分开,进程是操作系统分配内存的基本单位,但线程作为进程内的执行单元,也会申请属于自己的内存(主要是栈),这时线程私有的内存区域(相当于线程找进程借的一块内存区域)
- 虽然这块栈空间在未使用时,是块虚拟空间,在使用时才会真正分配物理内存,但是在高并发的时候,就必然处于使用状态,然后操作系统就要分配物理内存给这些线程,而这些线程基本都要占 2 ~ 8M 的栈空间(就算 8M),首先这样,相比于 Nginx 事件驱动模型,每个连接只占几百字节,这中间就存在了几千,甚至上万倍的内存消耗!
- 其次,线程之间是存在上下文切换的,在高并发情况下,很多线程在不断来回切换,这中间 CPU 宝贵的执行时间就得不断浪费在上下文切换上,宝贵的时间就被白白浪费了!大大降低了 CPU 的利用率,而相比于 Nginx 的事件驱动模型,只需一个线程就能处理成千上万的 TCP 连接,中间不需要上下文切换,CPU 利用率高效
可以看到,不断提高上限这条路也行不通,不管是从空间,还是时间角度,http.server 在高并发这块儿上,都完败给 Nginx
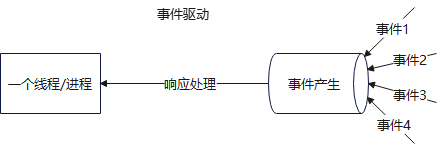
之前说过,Nginx 一个线程,结合 epoll 和非阻塞式的处理(比如 accept,read,write 等),有请求就处理,没请求就拉倒,可以高效地去处理这些事件响应

在高并发上,http.server 完败给 Nginx,也不能就说 http.server 就没用了,因为两者的设计目标,适用场景根本就不同
- 从目的上,
http.server可以快速启动一个简易 HTTP 服务器,用来支撑开发,测试和演示,而 Niginx 是本身就设计为高性能,高并发,生产级别的反向代理或者 Web 服务器 - 从代码量上说,
http.server是标准库内容,几百上千行 Python 代码就能搞定,而 Nginx 规模要几十万行 C 代码,还要不断优化 - 从模型上,设计目标简单,
http.server所以选择了多线程 + 阻塞式 IO 的这种模式,而追求高性能的 Nginx 当然就不能这么搞了,所以选择了事件驱动 + epoll 模型 - 从安全上,
http.server几乎没有安全加固,而为了支撑生产环境,Nginx 还支持 TLS,限流,WAF,DDos 等多重防护
总之,还是 Python http.server 官方那句话,不要用于生产环境!
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog

















 5323
5323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









