




1. 研究背景与动机
- 问题:Transformer在图像超分辨率(SR)中计算复杂度随空间分辨率呈二次增长,现有方法(如局部窗口、轴向条纹)因内容无关性无法有效捕获长距离依赖。
- 现有局限:
- SPIN等聚类方法依赖稀疏聚类中心传播信息,导致近似粗糙且推理速度慢(需迭代更新中心)。
- ATD引入字典学习但计算负担大,不适合轻量化场景。
- 解决方案:提出 CATANet,通过内容感知令牌聚合实现高效长距离依赖建模,兼顾性能与速度。
2. 方法设计
2.1 整体架构
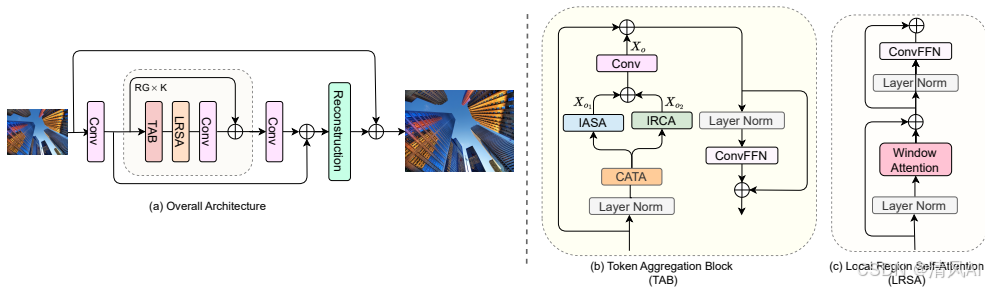
三阶段流程:
- 浅层特征提取:3×3卷积映射LR图像至高维特征。
- 深层特征提取:K个残差组(RG),每个RG包含:
- 令牌聚合块(TAB):核心创新模块。
- 局部区域自注意力(LRSA):增强局部细节。
- 3×3卷积:细化特征并学习位置嵌入。
- 图像重建:全局残差信息 + LR上采样 → 输出HR图像。
2.2 令牌聚合块(TAB)<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











