







原文地址:http://blog.csdn.net/tanxuan231/article/details/44887073
入门视频采集与处理(学会分析YUV数据)
http://blog.csdn.net/vblittleboy/article/details/10945439
核心编码函数研究
如果选择的是帧内模式,则预测值由当前帧已经编码重建的宏块(没有经过去块效应滤波器)给出,最佳的模式值经过熵编码输出到编码流。如果选择的是帧间模式,则预测值由以前编码帧的重建图像给出,选择的参考帧和运动向量等信息经过熵编码输出到码流。原始图像的值和帧内或者帧间预测得到的预测值相减得到残差数据,这些残差数据经过变换,量化后得到的残差系数也经过熵编码输出到码流。另外,参加熵编码的残差系数经过反量化和反变换,和预测值相加,得到重建宏块,存储在当前帧的重建图像中。当前帧的重建图像全部完成以后,经过去块效应滤波器的滤波,将作为参考帧存储起来成为以后编码图像的帧间运动估计的参考。
编码一个宏块的步骤:
帧间帧内模式选择,7 种帧间模式包括:16x16 16x8 8x16 8x8 8x4 4x8 4x4, 分别对应模式编号1~7。在进行帧间预测的时候,只有在选择了把一个宏块划分成4 个8x8 的块之后,才能进一步选择8x4,4x8 和4x4的分块。因此,在JM 模型中,把4~7 的四种帧间模式统称为P8x8。根据配置文件中的RDOptimization 的取值,JM 采用两套不同的编码步骤。
REF: http://www.cnblogs.com/xkfz007/articles/2612755.html
码流控制RC
rate control 的总体目标是控制每一帧图像编码输出的比特数,并在总比特数一定的约束条件下使得图像失真最小,并且保证编解码端的缓存区不发生溢出。
去块滤波
去块滤波是在整幅图像编码完后进行,以宏块为单位,以解决DCT变换和量化引起的块效应。
核心全局变量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
SKIP模式,16×16,16×8,8×16,P8×8(8x8, 8x4, 4x8, 4x4),以一个4x4大小为基础。
运动矢量的写码流
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
运动矢量是以1/4像素为单位的,所以(4,8),实际代表偏移了(1,2)个像素
REF: http://www.360doc.com/content/11/0521/14/1412027_118336851.shtml
PartitionMotionSearch
REF: http://blog.csdn.net/timebomb/article/details/6121089
从码流中提取NALU
从码流中提取一个NALU的过程:get_ annex_ b_NALU
对于一个原始的 H.264 NALU 单元常由 [Start Code] [NALU Header] [NALU Payload] 三部分组成, 其中 Start Code 用于标示这是一个
NALU 单元的开始, 必须是 “00 00 00 01” 或 “00 00 01”, NALU 头仅一个字节, 其后都是 NALU 单元内容.
打包时去除 “00 00 01” 或 “00 00 00 01” 的开始码, 把其他数据封包的 RTP 包即可.
结构体
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
00000(IDR) 21392 28 37.638 41.571 43.231 391 0 FRM 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
image.c
encode_ one_frame -> ReportNALNonVLCBits ReportFirstframe
buf2img_basic 将文件中的一帧转换为PIC
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
@1:
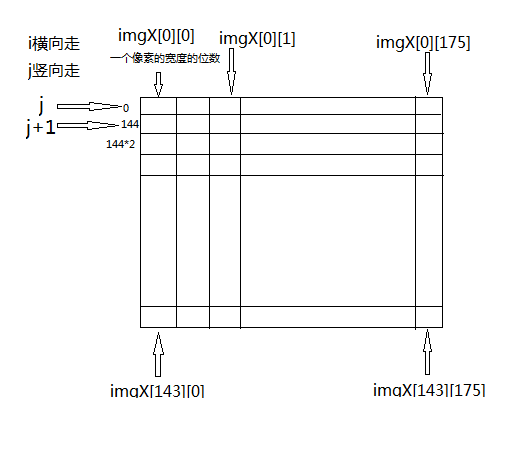
因此imgX这个二位数组里存放了Y DATA的数据
====================== Y Data ======================
+——————————–+——————————–+
| 49, 50, 49, 49, 49, 48, 48, 48,| 48, 49, 51, 57, 62, 62, 61, 62,|
| 47, 47, 48, 48, 48, 48, 48, 47,| 47, 48, 48, 47, 48, 50, 50, 50,|
| 45, 45, 45, 44, 45, 45, 46, 45,| 45, 45, 45, 44, 43, 43, 44, 44,|
| 41, 42, 43, 43, 43, 41, 41, 43,| 43, 41, 42, 43, 43, 42, 43, 43,|
| 38, 39, 38, 38, 39, 40, 39, 38,| 39, 39, 39, 40, 39, 38, 39, 38,|
| 39, 39, 39, 38, 39, 41, 40, 40,| 40, 41, 41, 40, 40, 41, 42, 40,|
| 51, 51, 52, 52, 51, 50, 51, 51,| 51, 50, 50, 50, 50, 50, 51, 50,|
| 64, 64, 65, 64, 63, 62, 62, 62,| 62, 62, 62, 61, 61, 61, 60, 60,|
+——————————–+——————————–+
| 73, 74, 74, 74, 73, 72, 70, 70,| 71, 71, 71, 70, 70, 70, 70, 70,|
| 77, 79, 78, 78, 78, 77, 75, 75,| 76, 75, 75, 75, 75, 75, 75, 74,|
| 79, 79, 79, 79, 78, 77, 76, 76,| 76, 75, 75, 75, 74, 74, 74, 74,|
| 82, 81, 81, 80, 78, 76, 76, 76,| 76, 76, 75, 75, 75, 75, 75, 74,|
| 93, 91, 87, 83, 80, 77, 76, 76,| 76, 76, 75, 74, 75, 76, 76, 76,|
|105,102, 94, 86, 82, 78, 77, 76,| 76, 78, 76, 75, 76, 77, 77, 77,|
|111,108, 99, 89, 82, 80, 77, 77,| 77, 78, 76, 75, 76, 76, 78, 77,|
|117,111,102, 91, 82, 80, 78, 79,| 78, 77, 76, 76, 76, 77, 77, 76,|
+——————————–+——————————–+:
2、int read_one_frame (VideoParameters *p_Vid, VideoDataFile *input_file, int FrameNoInFile, int HeaderSize, FrameFormat *source, FrameFormat *output, imgpel **pImage[3])
pImage[3]存放了Y/U/V的数据
H.264级别Level、DPB 与MaxDpb Mbs 详解
http://blog.csdn.net/vblittleboy/article/details/8033133
宏块模式
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
H264码流结构分析
REF: http://blog.csdn.net/chenchong_219/article/details/37990541
编码端写码流
REF: http://bbs.chinavideo.org/viewthread.php?tid=8325
编码器:
一直以为写码流在write_one_macroblock()函数中进行,其实不是,这个函数的名字对初学者来说绝对有误导作用。(该函数只是将语法元素写入缓冲区,并未写入文件)
真正的写码流过程如下:
—-lencod.c中调用start_sequence()和terminate_sequence()分别打开和关闭文件流(input->outfile).
filehandle.c中的start_sequence()和terminate_sequence()中有几个与写码流相关的重要的操作:
OpenAnexxbFile(input->outfile);
WriteNALU=WriteAnexxbNALU;
于是WriteNALU在编码器中担任了写码流的主要及核心工作。
—-在OpenAnexxbFile()中(Anexxb.c中)将文件打开,句柄赋与FILE *f全局变量,f=fopen(Filename,”wb”) 从这句以后文件流一直处于打开状态,便于写码流。
—-打开后紧接着调用WriteNALU写头部。
注意:WriteNALU的参数及其中各函数的NALU_t类型变量。
—-搜索WriteNALU:
在WriteUnit中有调用,而WriteUnit在WriteOut_Picture中有调用,WriteOut_Picture()在encode_one_frame()中有调用。于是从encode_one_frame开始
,整个写码流流程是:
encode_one_frame—->frame_picture
—->WriteOut_Picture—->WriteUnit—–>WriteNALU(即WriteAnexxbNALU)
整个文件编码完并写码流结束后调用terminate_sequence()关闭文件流。
** 注意各函数中的NALU_t类型变量,以及WriteNALU中的FILE *f
最终落实写码流的语句是:fwrite(n->buf,1,n->len,f);
解码器:
配置文件中共包含三个文件:
test.264 test_dec_yuv test_rec_yuv分别对应inp->infile(bits),inp->outfile(p_out),inp->reffile(p_ref),括号内为文件所对应的变量 初始化在
init_conf()中进行。
举例:OpenBitstreamFile()中有bits=fopen(fn,”rb”)于是bits便与fn建立起了对应关系,其它两个类同。
read_new_slice()中img->currSlice->currStream保存了从码流中读进来的语法元素(memcpy(currStream->streamBuffer,&nalu->buf[1],nalu->len-1);)
注意这里的nalu->len,这个分量控制眷读码流的位数,很重要,它在GetAnexxbNALU中求得。
因此解码器中整个码流流向为:
inp->infile->bits->nalu->[CurrStream->streamBuffer]
解码端读取运动矢量信息
readMBMotionVectors
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
解码端读取残差信息
- Get coefficients (run/level) of one 8x8 block
- from the NAL (CABAC Mode)
readCompCoeff8x8_CABAC
编码端写残差信息
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
JM18中编码一个I宏块的过程
以I16MB为例:
- 1
- 2
- 3
- 1
- 2
- 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
write_i_slice_MB_layer
writeIPCMData 写IPCM宏块到码流
CBP
CBP全称为Coded Block Pattern,指亮度和色度分量的各小块的残差的编码方案。H.264解码器中cbp变量(一个uint8_t类型变量)高4位存储了色度CBP,低4位存储了亮度CBP。色度CBP和亮度CBP的含义是不一样的:
亮度CBP数据从最低位开始,每1位对应1个子宏块,该位等于1时表明对应子宏块残差系数被传送。(因此亮度CBP数据通常需要当成二进制数据来看)
色度CBP包含3种取值:
0:代表所有残差都不被传送
1:只传送DC系数
2:传送DC系数以及AC系数
(因此色度CBP数据通常可以当成十进制数据来看)
JM使用
SliceMode = 0 # Slice mode (0=off 1=fixed mb in slice, 2=fixed bytes in slice, 3=use callback)
正如注释所说:
值为 0:表示不采用分片。也就是一个片组为一个片,如果不采用片组那么就是一幅图像为一个片。
值为 1:表示将每 SliceArgument 个宏块分为一个片;
值为 2:表示将每 SliceArgument 个字节分为一个片
值为 3:我也不知道是什么意思,猜测可能是根据解码器或者其他什么的反馈信息来确定。这样根据反馈信息可以更好适应不同网络环境下抗错能力。
SliceArgument = 50 # Slice argument (Arguments to modes 1 and 2 above)
REF:http://blog.sina.com.cn/s/blog_784448d60100x33x.html
encoder_ baseline.cfg, encoder_ extended.cfg, encoder_ main.cfg, encoder_ tonemapping.cfg, encoder_yuv422.cfg。它们里面的参数名都一样的,只是值不同。把其他一个文件拷贝成文件名 encoder.cfg。
H.264步步为营
http://wmnmtm.blog.163.com/blog/static/382457142011812111015157/?suggestedreading&wumii
下载Elecard StreamEye,用于播放test.264文件。
缩写
ME: Motion Estimation 运动估计
qp/QP: quantization parameter 量化参数
RDOQ: rd optimization 率失真率
PSNR: Peak Signal to Noise Ratio 峰值信噪比 评价图像的客观标准
blk: block 块
idr/IDR: IDR帧
CBP: CodedBlockPattern 当前块的编码模式
POC: picture order count
CPB: coded picture buffer 保存编码图像的队列缓存区
用来反应该宏块编码中残差情况的语法元素。CBP每位都为0,表示没有残差要编码,不为0的位数越多表示要编码的残差越多。 用于表示当前宏块是否存在非零值
http://imeradio.blog.163.com/blog/static/153419404201011224714936/
DPB: decoded picture buffer,解码图片缓存区
在做视频解码时,需要将最近的若干幅参考帧缓存起来,这个缓冲区就叫做DPB。所以最大存储帧数也是最大参考帧数(ref)。DPB一般以宏块数为单位(DpbMbs),计算公式为——
DpbMbs = ref(参考帧数) * PicWidthInMbs(水平宏块数) * FrameHeightInMbs(垂直宏块数)
deblock: 去块滤波
FMO: 指灵活块映射,也即多片组模式。 REF: http://blog.csdn.net/newthinker_wei/article/details/8784754
RDO: Rate–distortion optimization 率失真优化
SSE: MMX/SSE/SSE2指令集对H.264解码器的关键算法进行优化
coef: 变换系数,残差值进行DCT变换之后得到。
SAE: 定义了每种预测的预测误差
PCM/DPCM:
预测编码[1] 中典型的压缩方法有脉冲编码调制(PCM,Pulse Code Modulation)、差分脉冲编码调制(DPCM,Differential Pulse Code Modulation)、自适应差分脉冲编码调制(ADPCM,Adaptive Differential Pulse Code Modulation)等
BS: Boundary Strength 边界强度,去块滤波过程中的。
UVLC: 通用可变长编码 熵编码
CABAC: 基于文本的自适应二进制算术编码 熵编码
问题
1、宏块编码长度
2、宏块编码数据
TIFF文件格式
标签图像文件格式(Tagged Image File Format,简写为TIFF) 是一种主要用来存储包括照片和艺术图在内的图像的文件格式。TIFF 是一个灵活适应性强的文件格式,通过在文件头中包含“标签”它能够在一个文件中处理多幅图像和数据。标签能够标明图像的如图像大小这样的基本几何尺寸或者定义图像数据是如何排列的并且是否使用了各种各样的图像压缩选项。
像素由多少位构成
Q:一幅图像存储容量为64KB,分辨率为256×128
整幅图是用64×1024×8=524288位二进制表示
每一个像素是用524288÷(256×128)=16位表示
C库函数
int access(const char *filenpath, int mode)
FILE * fopen(const char * path,const char * mode);
lseek()便是用来控制该文件的读写位置
int read(int handle, void *buf, int nbyte); nbyte:要读多少个字节,不能大于buffer指向的缓冲区
void *memcpy(void *dest, const void *src, size_t n);
gdb调试命令
bt / info stack 查看栈信息
list 查看源程序
list命令后面还可以更一些参数,来显示更多功能:
行号。
<+> [offset] 当前行号的正偏移量。
<-> [offset] 当前行号的负偏移量。
文件的中的行行。
函数的代码
文件中的函数。
<*address> 程序运行时的语句在内存中的地址。
print p 查看运行时数据
查看二位数组:
一个16*16的二维数组的第一行
p **currSlice->tblk16x16@16
格式:print [</format>] <expr>
例如:(gdb) p /x 3+2*5
$19 = 0xd
format的取值范围有如下几种:
x 按十六进制格式显示变量。
d 按十进制格式显示变量。
u 按十六进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
c 按字符格式显示变量。
f 按浮点数格式显示变量。
查看函数返回值
* finish命令运行至函数结束,此时会打印函数返回值
* 返回值会存储在eax寄存器中,p $eax
跳出循环:
until NUM 执行到一个比当前行号大的行,或者也可以指定在当前frame(我理解成函数)中的某一行
跳出函数:
finish 执行,直到选定的frame执行结束,然后打印返回值,将其放入历史值中,停止
REF: http://www.cnblogs.com/TianFang/archive/2013/01/21/2869474.html
查看当前程序运行到的文件
info source
important REF: http://www.cnblogs.com/kzloser/archive/2012/09/21/2697185.html
收集的方法
1、if ((source->pic_unit_size_on_disk & 0x07) == 0)
source->pic_unit_size_on_disk这个数要能被8整除















 5892
5892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









