



在第二部分,我们来着重讲表的设计,在此之前我们学过了表的增删改查的基本操作。但是对于如何去创建一个合理的数据库表,我们还没有提及。对于一张表,在设计关系数据库时,我们可不能随便创建字段,需要遵照一定的规则要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式。
关系数据库常见有以下范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、第四范式(4NF)和第五范式(5NF,又称完美范式),越高的范式数据库冗余越小。然而,普遍认为范式越高虽然对数据关系有更好的约束性,但同时也可能导致数据库IO更繁忙,因而在实际应用中,数据库设计通常只需满足前三个范式即可。
1. 三大范式
1.1 第一范式
定义:在数据库表中的每一列(字段)都是不可再分的原子项,而不能是集合、数据、对象等非原子项。不满足第一范式的数据库则不是关系型数据库。
这里的原子项就是指该字段名所代表的意思是不可再分的。例如:如果北京大学作为字段,但是北京大学中有北京大学教学楼、北京大学操场、北京大学食堂、北京大学电话等能细分出来的原子字段。所以北京大学这个字段就不是不可再分的原子项。
这里教大家一个办法,1秒就能判断出是否是原子项。当你在创建字段的时候,如果这个字段可以被相应的数据类型所对应,那就说明这个字段天然满足第一范式。这里就不举例特别说明了。
1.2 第二范式
定义:在满足第一范式的基础上,不存在非关键字段对任意候选键的部分函数依赖。一般存在于表中存在复合主键的情况。(复合主键:同样是一个主键,但是该主键中有多个字段,即 primary key (列名,列名))
这里先解释一下专有名词:非关键字段可以理解成非主键字段,候选键可以理解成主键、外键或是无主键时的唯一键。对于部分函数依赖的解释,这里举个例子:
现在,我要创建一个学生必修课的成绩表。那么该表中应该会有学生学号、学生姓名、学生年龄、课程名称、课程学分以及成绩等。(这里以这六个为例,并不是一定是这六个,可以自由创建)
| 学号 | 姓名 | 年龄 | 课程名 | 学分 | 成绩 |
| 01 | 张三 | 18 | 高等数学 | 5.0 | 75 |
从上表的关系中,我们可以通过经验来分析出:学生相关的信息(姓名、年龄)可以通过学号来确定,而学分和成绩是通过课程名来决定的。也就是说,该表中的学号和课程名作为复合主键来确定了学生必修课的成绩表。年龄和姓名依赖了学号,学分和成绩依赖了课程名。这种对于由两个或多个关键字来决定一条记录的情况或是一行数据中的个别字段只与部分关键字段有联系的情况,我们就称之为部分函数依赖。也说明它不满足第二范式。
那么正确的设计表的方法,应该是把一张表拆分成两张表,这张表的复合主键改成两个表的两个主键,就可以有效解决存在函数依赖的问题。即:
1. 学生表
| 学号 | 姓名 | 年龄 |
| 01 | 张三 | 18 |
2. 必修的课程表
| 课程编号 | 课程名 | 学分 |
| 1 | 高等数学 | 5.0 |
3. 必修课成绩表
| 学号 | 课程编号 | 成绩 |
| 01 | 1 | 75 |
这样的设计,在每张表中所有的非主键字段都只依赖于一个主键,满足第二范式。所以其实说白了,不知道大家发现没有,一张表中如果没有复合主键,那么这张表其实就天然满足第二范式。
如果一张表不满足第二范式时,可能在CRUD时,会出现问题,接下来展开说一下。
(1)数据冗余
由于我在一开始时是创建的一个学生必修课的成绩表,其中的主体应该是成绩表,而该表中还有年龄、学分等无关项,这样子不仅在别人查看时显得数据很杂,而且对于数据库的消耗也会更大,所以这不是一个好的编程习惯,也会对数据库增加压力,在实际工作时,往往数据一查就是成千上万条,而其中还有冗余的数据,其实就不是很好了。
(2)更新异常
这里以某个场景举例:
如果学校要将高等数学的学分从5分下调到3分,那么就应该更新表中所有高等数学的记录,这时由于系统故障,导致某些记录更新失败,就会引起数据库中同样的高等数学,而学分不一样的情况。具体表现就是更新后部分数据不一致。
(3) 插入异常
目前创建的一个学生必修课的成绩表的这样的设计,只有学生参与了该必修课的考试得到成绩后,在数据库中才会有一条记录的生成。但是满足第二范式后,有了多张表通过主外键的联系,就不需要等到成绩出来才有那长长的一整条记录出现了,只需要有必修课成绩表的记录生成即可。不会互相产生影响。
(4)删除异常
如果数据库数据太多,我们需要将往年的毕业学生的考试数据全部删除,如果直接删除,此时有可能会将所有的课程和学分信息都会被删除掉,有可能导致一段时间内,数据库里不存在某门课程和学分信息。
1.3 第三范式
定义:在第二范式的基础上,不存在非关键字段对任意候选键的传递依赖。
同样我们举个例子,设置一个场景:
创建了一个包含学院名称的学生表,它的学生记录描述了学生ID、学生姓名、学生年龄、就读学院、学院地址、学院电话。
| ID | 姓名 | 年龄 | 学院名 | 学院地址 | 学院电话 |
| 001 | 张三 | 18 | 护理学院 | XXA | 854625 |
在该表中,姓名、年龄与学号是强相关的,学院地址、电话与学院名是强相关的。看到这,是不是感觉和第二范式有一些相似?但是需要注意的是,ID和学院名不能构成复合主键。因为与第二范式不同的是,ID是表所生成的类似唯一键的东西,具有单一性;和第二范式时的学号不同,学号是一个存在意义的字段。(该部分有些抽象,尝试理解下)
然后在出现两个强相关的关系后,又出现了一种依赖关系:ID -> 学院名 -> 学院电话\地址 ,这样的关系我们称之为传递依赖。
总结:在一个表中出现了两个强相关的关系,而且这两个强相关关系又存在传递现象,这种关系称为传递依赖,不满足第三范式。
解决办法:和第二范式类似,一个表既然存在两个关系,那就拆分成两个表,并用主外键联系起来。即:
1. 学院表
| 学院编号 | 学院名 | 学院电话 | 学院地址 |
| A | 护理学院 | 854625 | XXA |
2. 学生表
| ID | 姓名 | 年龄 | 学院编号 |
| 001 | 张三 | 18 | A |
只要掌握了这三大范式,表的创建格式你就能很好地理解了。
2. 表的设计关系
表的设计方法一般有两种步骤:
1. 从题目需求中获得类,类对应到数据库中就表现为一张一张的表,类中的属性对应着表中的字段;
2. 确定好类与类之间的关系;这部分就是我们现在所要讲的。
1. 一对一关系
例如在登陆界面时需要输入的账号密码,它属于账号;而登录账号后的用户则有个人信息,班级,姓名,手机号等。则这里用户和账号对应的就是一对一关系。
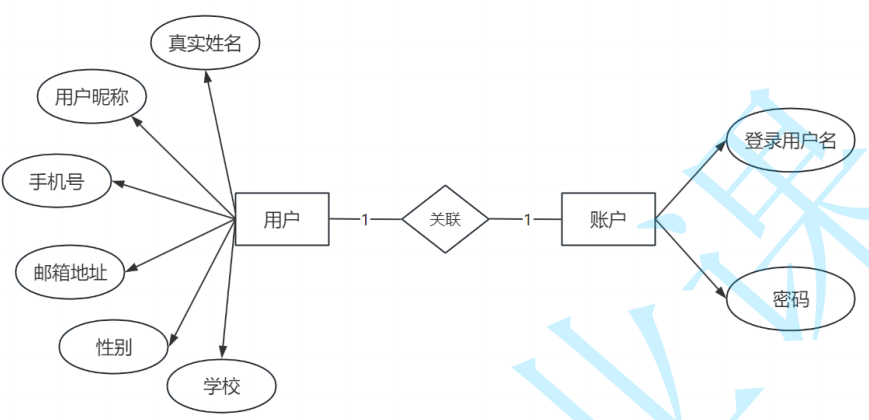
以创建两张表为例,大家可以自己先创建一下,下面给出参考:
user(user_id,name,age,phone_number,mail,account_id)
account(account_id,user_name,password)
2. 一对多关系
例如学生与班级之间的关系,一个班级里会有多个学生。这符合一对多关系。
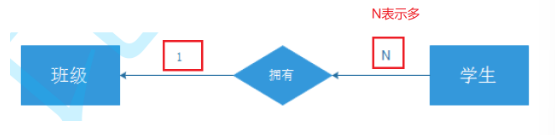
创建出来的两张表就如下所示:
class(class_id,name)
student(student_id,name,age,class_id)
3. 多对多关系
例如在大学中的选修课,一个学生可以选修多个课程,一门课程也可以被多个学生选择。这种就符合多对多关系。这里就不举例了,实质是一样的。
大家下来一定要多看一看,因为虽然内容不算多,但是知识的磨合是需要一些时间的。那么,本篇文章到此结束!希望能对你有帮助。

















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









