







代码演示
'''
Author: pipi
Date: 2021-12-13 13:45:01
LastEditTime: 2021-12-13 19:26:54
'''
#-*- coding:utf-8 -*-
#usr/bin/python
from lxml import etree
import requests
import os
url = "https://***.com/ql/lg/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36"
}
r = requests.get(url, headers=headers)
# 生成xpath对象
dom = etree.HTML(r.text)
# 获取data-src内容
src_info = dom.xpath("//img/@data-src")
# 存储目录生成
mkdir_img = os.getcwd()+"\\face_img\\"+url.split("/")[-2]
isExist = os.path.exists(mkdir_img)
if isExist==False:
os.mkdir(mkdir_img)
# 链接存储文件
current_path_html = mkdir_img+"/doc.html"
for i in range(len(src_info)):
# /tp/zjbq/201804201941164065.gif
imgsrc_local = mkdir_img+"\\"+src_info[i].split("/")[-1]
imgsrc_source = "https://***.com"+src_info[i]
response = requests.get(imgsrc_source, headers=headers)
with open(imgsrc_local, "wb") as f:
f.write(response.content);
with open(current_path_html, 'a+', encoding='utf-8') as f:
f.write(imgsrc_local+"\n")
print(imgsrc_local)
print("succ")结果展示
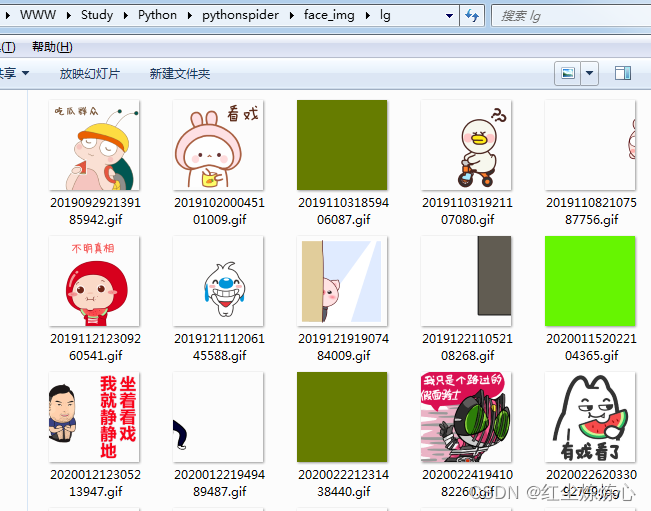
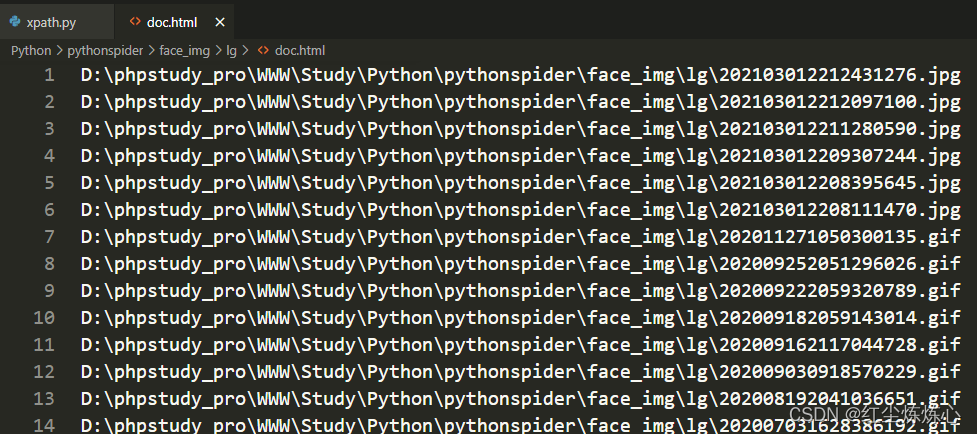
内容仅提供学习参考。。。
















 2938
2938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











