



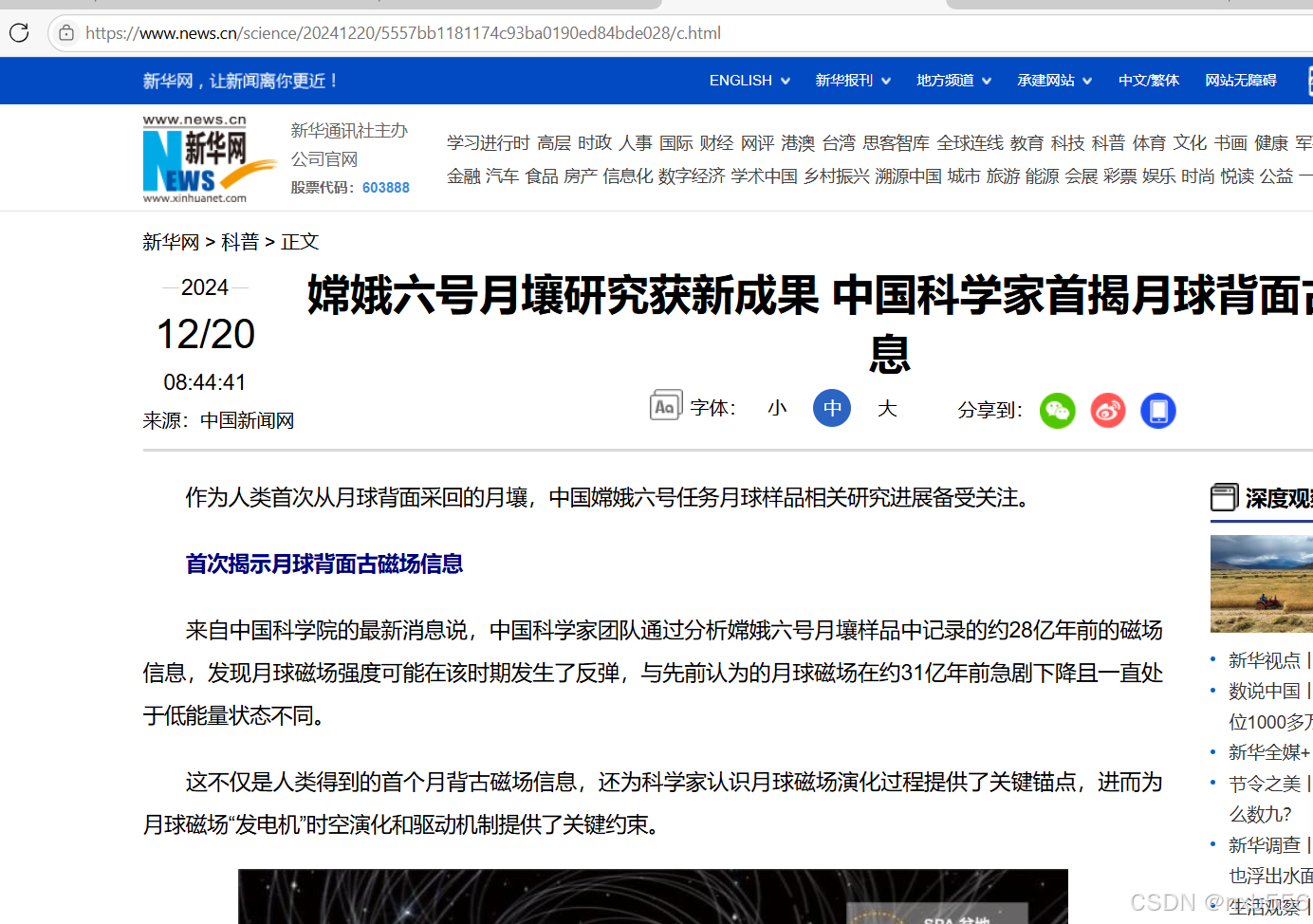
目标网页
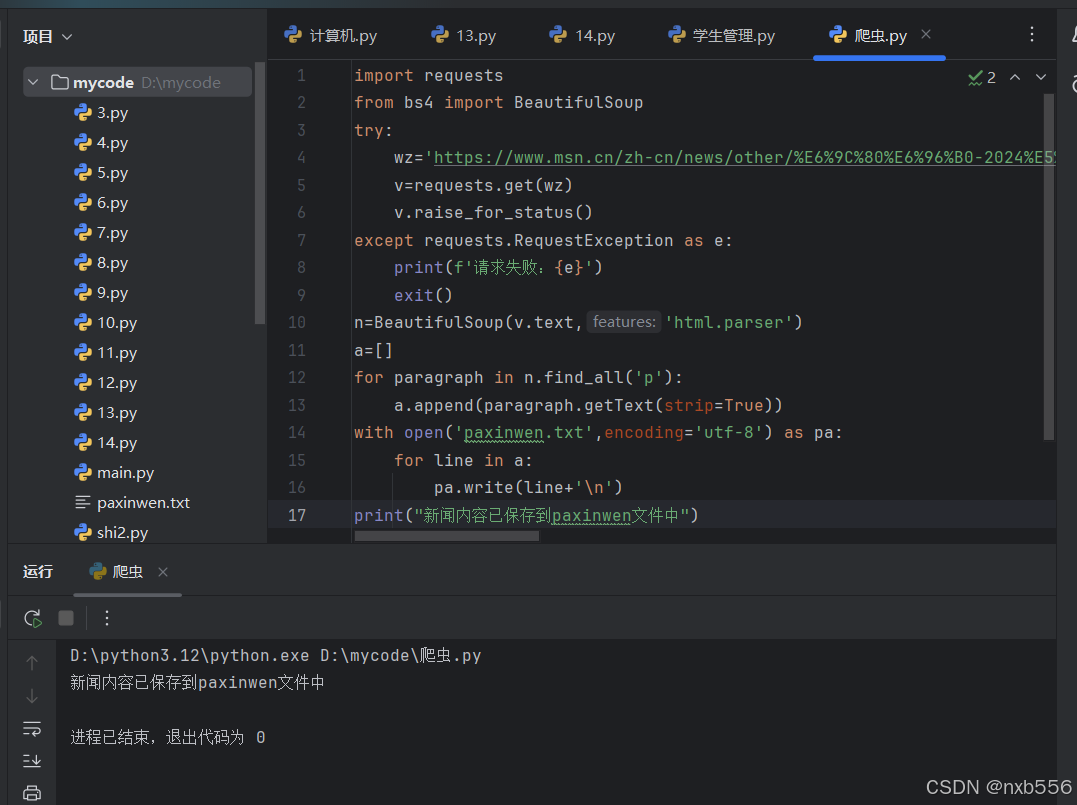
实现代码
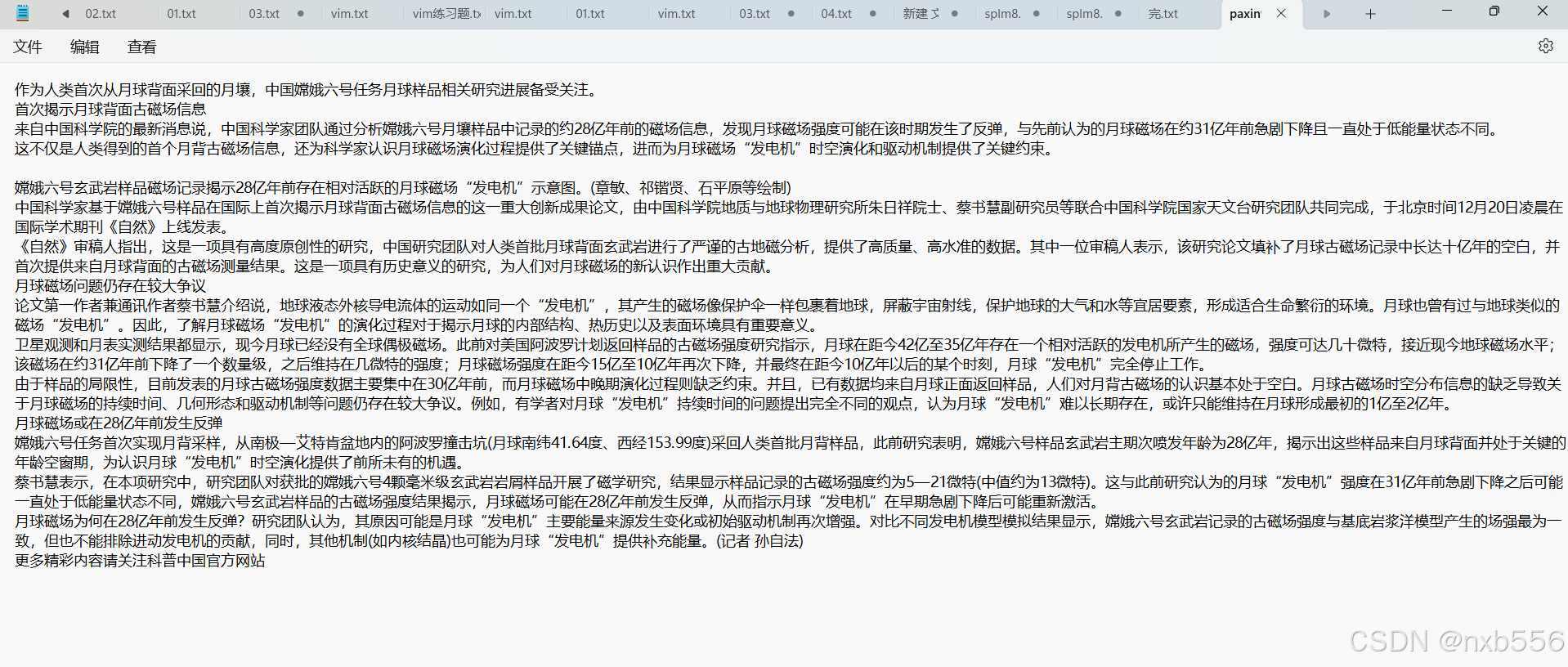
记事本结果
import requests
from bs4 import BeautifulSoup
try:
wz='https://www.news.cn/science/20241220/5557bb1181174c93ba0190ed84bde028/c.html'
v=requests.get(wz)
v.raise_for_status()
except requests.RequestException as e:
print(f'请求失败:{e}')
exit()
n=BeautifulSoup(v.text,'html.parser')
a=[]
for paragraph in n.find_all('p'):
a.append(paragraph.getText(strip=True))
with open('paxinwen.txt','w',encoding='utf-8') as pa:
for line in a:
pa.write(line+'\n')
print("新闻内容已保存到paxinwen文件中")
代码内容


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









