






 文章介绍了GitHub的PersonalAccessTokens的两种类型——经典和个人细粒度,强调了细粒度令牌在安全性和权限控制上的优势。创建细粒度令牌允许更精确的资源访问控制,并且需要定期审批,增强了安全性。同时,文章提醒用户注意令牌的使用和安全存储,以防止未授权访问。
文章介绍了GitHub的PersonalAccessTokens的两种类型——经典和个人细粒度,强调了细粒度令牌在安全性和权限控制上的优势。创建细粒度令牌允许更精确的资源访问控制,并且需要定期审批,增强了安全性。同时,文章提醒用户注意令牌的使用和安全存储,以防止未授权访问。
1. 背景
在使用github自动化部署博客的环境下,遇到过错误的使用以下秘钥,导致自动构建时出现问题。
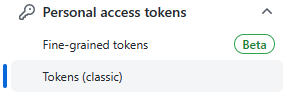
由此就简单认识一下,Personal access tokens (classic)与Fine-grained personal access tokens Beta的区别。
它们之间的区别
关于 personal access token
警告:将访问令牌视为密码。
若要从命令行访问 GitHub,请考虑使用 GitHub CLI 或 Git 凭据管理器,而不是创建 personal access
token。在脚本中使用 personal access token 时,请考虑将令牌存储为机密,并通过 GitHub Actions 运行脚本。
有关详细信息,请参阅“加密机密。”还可以将令牌存储为 Codespaces 机密,并在 Codespaces 中运行脚本。
有关详细信息,请参阅“管理 codespace 的加密机密。”如果无法使用这些选项,请考虑使用其他服务(如 1Password CLI)安全地存储令牌。
使用 GitHub API 或命令行时,可使用 Personal access token 替代密码向 GitHub 进行身份验证。 Personal access token 旨在代表你自己访问 GitHub 资源。 若要代表组织访问资源,或为长时间的集成而访问,应使用 GitHub App。 有关详细信息,请参阅“关于应用”。
GitHub 目前支持两种类型的 personal access token:fine-grained personal access token 和 personal access tokens (classic)。 GitHub 建议尽可能使用 fine-grained personal access token 而不是 personal access tokens (classic)。 与 personal access tokens (classic) 相比,Fine-grained personal access token 具有几个安全优势:
- 每个令牌只能访问单个用户或组织拥有的资源。
- 每个令牌只能访问特定的存储库。
- 每个令牌都被授予特定的权限,这些权限比授予 personal access tokens (classic) 的范围提供更多的控制。
- 每个令牌都必须具有到期日期。
- 组织所有者可要求必须获取对可访问组织中资源的任何 fine-grained personal access token 的批准。
此外,组织所有者还可以限制 personal access token (classic) 对其组织的访问。
注意:目前,某些功能仅适用于 personal access tokens (classic):
只有 personal access tokens (classic) 对不由你或你所属的组织拥有的公共存储库具有写入访问权限。
外部协作者只能使用 personal access tokens (classic) 访问他们参与协作处理的组织存储库。 以下 API
仅支持 personal access tokens (classic)。 有关 fine-grained personal access
token 支持的 REST API 操作列表,请参阅“可用于 fine-grained personal access token
的终结点”。 GraphQL API 用于管理源导入的 REST API 用于管理 Projects (classic) 的 REST
API 用于管理 GitHub Packages 的 REST API 用于管理通知的 REST API 用于传输存储库的 REST API
用于从模板创建存储库的 REST API 用于为已通过身份验证的用户创建存储库的 REST API
作为安全预防措施,GitHub 会自动删除一年内未使用过的 personal access token。 为了提供进一步的安全性,强烈建议将过期时间添加到 personal access token。
创建 fine-grained personal access token
注意:Fine-grained personal access token 目前处于 beta 状态,且可能会更改。 若要留下反馈,请参阅反馈讨论。
1。 验证电子邮件地址(如果尚未验证)。 1. 在任何页面的右上角,单击个人资料照片,然后单击“设置”。
- 在左侧边栏中,单击“ 开发人员设置”。
- 在左侧栏中,在“ Personal access token”下,单击“细粒度令牌” 。
- 单击“生成新令牌”。
- 在“令牌名称”下,输入令牌的名称。
- 在“过期时间”下,选择令牌的过期时间。
- (可选)在“说明”下,添加说明来描述令牌的用途。
- 在“资源所有者”下,选择资源所有者。 令牌只能访问所选资源所有者拥有的资源。 除非你所属的组织选择加入 fine-grained
personal access token,否则不会显示该组织。 有关详细信息,请参阅“为组织设置 personal access
token 策略”。 - (可选)如果资源所有者是需要批准 fine-grained personal access token
的组织,请在资源所有者下方的框中输入请求的理由。 - 在“存储库访问权限”下,选择希望令牌访问的存储库。 应选择满足需求的最小存储库访问权限。 令牌始终包括对 GitHub
上所有公共存储库的只读访问权限。 - 如果在上一步中选择了“仅选择存储库”,则在“所选存储库”下拉列表下,选择希望令牌访问的存储库 。
- 在“权限”下,选择要授予令牌的权限。 根据指定的资源所有者和存储库访问权限,有存储库、组织和帐户权限这几种可能性。
应根据需要选择最小权限。 有关每个 REST API 操作所需的权限的详细信息,请参阅“fine-grained personal
access token 所需的权限”。 - 单击“生成令牌”。****
如果选择了某个组织作为资源所有者,并且该组织需要批准 fine-grained personal access token,则令牌将被标记为 pending,直到组织管理员审核为止。 令牌在得到批准之前只能读取公共资源。 如果你是组织的所有者,请求将自动获得批准。 有关详细信息,请参阅“查看和撤销组织中的 personal access token”。
附件
github官方文档:创建个人访问令牌

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









