






接着 https://blog.51cto.com/mapengfei/2581240 这里用Flink来实现对APP在每个渠道的推广情况包括下载、查看、卸载等等行为的分析
因为之前的文章都是用scala写的,这篇用纯java来实现一波,
分别演示下用aggregate 聚合方式和process 方式的实现和效果
整体思路
1、准备好数据源: 这里用SimulatedSource 来自己随机造一批数据
2、准备数据输入样例 `MarketUserBehavior` 和输出样例`MarketViewCountResult`
3、准备环境并设置watermark时间,和指定事件时间字段为timestamp
4、进行过滤:uninstall 的行为过滤掉(根据实际情况来改)
5、根据行为和渠道进行KeyBy统计
6、设置滑动窗口1小时,每10s输出一次
7、进行聚合输出/**
* @author mafei
* @date 2021/1/9
*/
package com.mafei.market;
import cn.hutool.core.util.RandomUtil;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import static java.lang.Thread.sleep;
/**
* APP市场推广分析
*/
/**
* 定义一个输入数据的样例类
*/
class MarketUserBehavior {
String userId;
String behavior;
String channel;
Long timestamp;
public MarketUserBehavior(String userId, String behavior, String channel, Long timestamp) {
this.userId = userId;
this.behavior = behavior;
this.channel = channel;
this.timestamp = timestamp;
}
}
/**
* 定义一个输出数据的类
*/
class MarketViewCountResult {
Long windowStart;
Long windowEnd;
String channel;
String behavior;
Long count;
public MarketViewCountResult(Long windowStart, Long windowEnd, String channel, String behavior, Long count) {
this.windowStart = windowStart;
this.windowEnd = windowEnd;
this.channel = channel;
this.behavior = behavior;
this.count = count;
getOutput();
}
public void getOutput() {
/**
* 为了验证效果加的
*/
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("windowsStart: " + windowStart);
stringBuffer.append(" windowEnd: " + windowEnd);
stringBuffer.append(" channel: " + channel);
stringBuffer.append(" behavior: " + behavior);
stringBuffer.append(" count: " + count);
//为了验证效果,追加打印的
System.out.println(stringBuffer.toString());
}
}
/**
* 定义一个产生随机数据源的类
*/
class SimulatedSource extends RichSourceFunction<MarketUserBehavior> {
/**
* 是否运行的标志位,主要在cancel 方法中调用
*/
Boolean running = true;
/**
* 定义用户行为和渠道的集合
*/
String[] userBeahviors = {"view", "download", "install", "uninstall"};
String[] channels = {"dingding", "wexin", "appstore"};
Long maxRunning = 64 * 10000L;
Long currentRunningCount = 0L;
@Override
public void run(SourceContext<MarketUserBehavior> sourceContext) throws Exception {
while (running && currentRunningCount < maxRunning) {
String channel = RandomUtil.randomEle(channels);
String beahvior = RandomUtil.randomEle(userBeahviors);
Long timestamp = System.currentTimeMillis() * 1000;
String userId = RandomUtil.randomString(20);
sourceContext.collect(new MarketUserBehavior(userId, beahvior, channel, timestamp));
currentRunningCount += 1;
sleep(100L);
}
}
@Override
public void cancel() {
running = false;
}
}
public class MarketChannelAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator<MarketUserBehavior> dataStream = environment.addSource(new SimulatedSource())
//设置watermark时间为5秒,并且指定事件时间字段为timestamp
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<MarketUserBehavior>(Time.seconds(5)) {
@Override
public long extractTimestamp(MarketUserBehavior marketUserBehavior) {
return marketUserBehavior.timestamp;
}
});
DataStreamSink<MarketViewCountResult> result = dataStream
.filter(new FilterFunction<MarketUserBehavior>() {
@Override
public boolean filter(MarketUserBehavior marketUserBehavior) throws Exception {
return !marketUserBehavior.behavior.equals("uninstall");
}
})
// .keyBy("channel", "behavior") // scala的实现方式
.keyBy(new KeySelector<MarketUserBehavior, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> getKey(MarketUserBehavior marketUserBehavior) throws Exception {
// return new String[]{marketUserBehavior.behavior, marketUserBehavior.channel};
return Tuple2.of(marketUserBehavior.behavior, marketUserBehavior.channel);
}
})
.timeWindow(Time.hours(1), Time.seconds(10)) //窗口大小是1小时,每10秒输出一次
.aggregate(new MyMarketChannelAnalysis(), new MyMarketChannelResult())
// .process(new MarkCountByChannel()) //用process方法也可以实现
.print();
environment.execute();
}
}
/**
* 2种实现思路,用process的时候可以用这个方法
* process不用每来一条数据都定义怎么做,而是把对应的数据会放到内存里面,当窗口结束后进行统一处理,比较耗内存,看实际使用场景
*/
class MarkCountByChannel extends ProcessWindowFunction<MarketUserBehavior, MarketViewCountResult, Tuple2<String, String>, TimeWindow> {
@Override
public void process(Tuple2<String, String> key, Context context, Iterable<MarketUserBehavior> iterable, Collector<MarketViewCountResult> collector) throws Exception {
Long startTime = context.window().getStart();
Long endTime = context.window().getEnd();
String channel = key.f1;
String behavior = key.f0;
Long count = iterable.spliterator().estimateSize();
collector.collect(new MarketViewCountResult(startTime, endTime, channel, behavior, count));
}
}
/**
* 定义聚合函数的具体操作,AggregateFunction 的3个参数:
* IN,输入的数据类型: 输入已经在源头定义为 MarketUserBehavior
* ACC,中间状态的数据类型:因为每次要算count数,所以是Long类型
* OUT,输出的数据类型:输出的是统计的次数,所以也是Long类型
*/
class MyMarketChannelAnalysis implements AggregateFunction<MarketUserBehavior, Long, Long> {
@Override
public Long createAccumulator() {
/**
* 初始化的操作,定义次数为0
*/
return 0L;
}
@Override
public Long add(MarketUserBehavior marketUserBehavior, Long aLong) {
/**
* 每来一条数据做的操作,这里直接加1就行了
*/
return aLong + 1;
}
@Override
public Long getResult(Long aLong) {
/**
* 最终输出时调用的方法
*/
return aLong;
}
@Override
public Long merge(Long aLong, Long acc1) {
/**
* 这里是多个的时候用到,主要是session window时会使用
*/
return aLong + acc1;
}
}
/**
* 定义输出的WindowFunction,要的参数可以点进去看
* IN:这里输入是上一步的输出窗口内add的数量,所以是Long类型
* OUT:自定义的输出结构,这里定义的是一个类,可以直接改
* KEY:分组的Key,就是keyBy 里头定义的Tuple2.of(marketUserBehavior.behavior, marketUserBehavior.channel);
* W extends Window:TimeWindow
*
*/
class MyMarketChannelResult implements WindowFunction<Long, MarketViewCountResult, Tuple2<String, String>, TimeWindow> {
@Override
public void apply(Tuple2<String, String> stringStringTuple2, TimeWindow window, Iterable<Long> input, Collector<MarketViewCountResult> out) {
out.collect(new MarketViewCountResult(window.getStart(), window.getEnd(), stringStringTuple2.f1, stringStringTuple2.f0, input.iterator().next()));
}
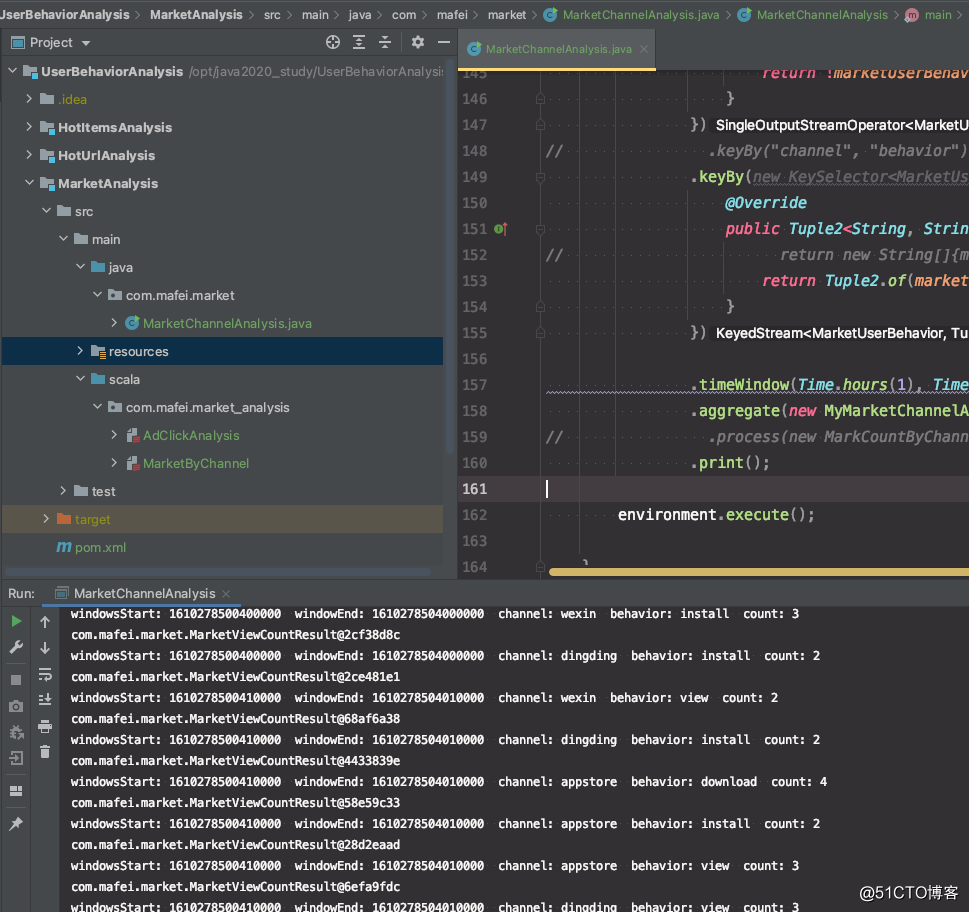
}代码结构及运行的效果,如果要输出es、mysql、kafka之类的直接把print换成addSink就可以了














 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









