







CentOS下Hadoop伪分布模式安装笔记
一. 前言
Hadoop 伪分布式模式是在单机上模拟 Hadoop分布式,单机上的分布式并不是真正的伪分布式,而是使用线程模拟分布式。Hadoop本身是无法区分伪分布式和分布式的,两种配置也很相似,唯一不同的地方是伪分布式是在单机器上配置,数据节点和名字节点均是一个机器。 现在很多初学者根本不具备搭建完全分布式集群的硬件环境,大多都是在单机下进行学习和实验。 下面将我在安装期间遇到的问题和解决方法记录下来,和网友共勉。本人当时是在Linux Cent OS 6.3下搭建成功Hadoop伪分布式测试环境。
*******************************************************************博文更新说明**************************************************************************
本博文我已在2014.3.13日做了小幅度的更新,由于工作原因,把hadoop版本定位在了hadoop-1.2.1.tar.gz,其他细节也多有改动,使得配置流程更加容易理解和操作!
二. 环境搭建
搭建测试环境所需的软件包括:jdk-6u19-linux-i586.bin 、hadoop-1.2.1.tar.gz。测试服务器操作系统Linux Cent OS 6.3。
1、JDK安装及Java环境变量的配置
说明:1.CentOS默认情况下,会安装OpenOffice之类的软件,这些软件需要Java的支持,所以系统默认会安装JDK的环境,若需要特定的Java环境,最好将默认的JDK彻底删除;
2.查看默认的JDK命令:java -version
3.但是如果先删除默认再装新的JDK,则与之相关的软件比如openoffice等也会随之删除,所以,应该先装新的jdk再卸系统默认自带的jdk。
***卸载系统自带原JDK的方法示例:(注意,此操作应该在新jdk安装完毕后再执行)
终端输入,查看gcj的版本号:rpm -qa|grep jdk
得到结果:
jdk-1.6.0_19-fcs.x86_64
java-1.6.0-openjdk-1.6.0.0-1.49.1.11.4.el6_3.x86_64
终端输入,卸载:yum -y remove java java-1.6.0-openjdk-1.6.0.0-1.49.1.11.4.el6_3.x86_64
等待系统自动卸载,最终终端显示 Complete,卸载完成
1.1 JDK安装(个人选择把jdk安装在root用户下,供本机所有用户使用。当然也可以选择安装在其他指定用户下。)
root 用户登陆,使用命令mkdir /usr/program新建目录/usr/program,下载 JDK 安装包jdk-6u19-linux-i586.bin,将其复制到目录/usr/program下,用cd命令进入该目录,执行命令“./ jdk-6u13-linux-i586.bin”,命令运行完毕即安装完成,将在目录下生成文件夹/jdk1.6.0_19,此即为jdk被成功安装到目录:/usr/program/jdk1.6.0_13下。
1.2 java环境变量配置
root 用户登陆,命令行中执行命令“vi /etc/profile”,并加入以下内容,配置环境变量(注意/etc/profile 这个文件很重要,后面 Hadoop的配置还会用到)。
# set java environment
export JAVA_HOME=/usr/program/jdk1.6.0_19
export JRE_HOME=/usr/program/jdk1.6.0_19/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
在vi编辑器增加以上内容后保存退出,并执行以下命令使配置生效!
[root@localhost ~]#chmod +x /etc/profile ;增加执行权限
[root@localhost ~]#source /etc/profile;使配置生效!
配置完毕后,在命令行中输入:java -version,如出现下列信息说明java环境安装成功。
java version "1.6.0_19"
Java(TM) SE Runtime Environment (build 1.6.0_19-b03)
Java HotSpot(TM) Server VM (build 16.3-b01, mixed mode)
2、SSH无密码验证配置(SSH免密码登陆应该在hadoop安装环境所在的用户下配置,比如本Hadoop伪集群搭建在hadoop用户下,则SSH免密码登陆应该在hadoop用户下配置)

注:Hadoop 需要使用SSH 协议,namenode 将使用SSH 协议启动 namenode和datanode 进程,伪分布式模式数据节点和名称节点均是本身,所以配置 SSH localhost无密码验证登录就会方便很多。实际上,在H adoop的安装过程中,是否免密码登录是无关紧要的,但是如果不配置免密码登录,每次启动Hadoop都需要输入密码以登录到每台机器的DataNode上,考虑到一般的Hadoop集群动辄拥有数百或上千台机器,因此一般来说都会配置SSH的免密码登录!在此我们选择配置SSH为免密码登录模式!!!
配置为可以免密码登录本机:
注意:SSH免密码登陆应该在hadoop安装环境所在的用户下配置,比如本Hadoop伪集群搭建在hadoop用户下,则SSH免密码登陆应该在hadoop用户下配置
首先查看在“当前用户”(hadoop)文件夹下是否存在.ssh 文件夹(注意ssh前面有“.”,这是一个隐藏文件夹)。输入命令查看此文件夹是否存在。一般来说,安装SSH时会自动在当前用户下创建这个隐藏文件夹,如果没有,可以手创建一个。
下面的配置我是在hadoop用户下进行的:
[hadoop@localhost ~]$ls –a
发现.ssh文件夹已经存在。
接下来输入命令(注意下面命令中不是双引号,是两个单引号):
方法一:用hadoop用户登录,终端执行如下命令:ssh-keygen -t rsa
[hadoop@localhost ~]$ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/hadoop/.ssh/id_rsa): &按回车默认路径 &
......
......
通过以上命令将在/hadooop/.ssh/ 目录下生成id_rsa私钥和id_rsa.pub公钥。进入/hadoop/.ssh目录在namenode节点下做如下配置:
[hadoop@localhost .ssh]# cat id_rsa.pub > authorized_keys
配置完毕,可通过ssh 本机IP 测试是否需要密码登录。
方法二、或者按照如下方式配置:
生成签名文件:
[hadoop@localhost ~]$ ssh-keygen -t dsa -P ' ' –f ~/.ssh/id_dsa
解释一下,ssh-keygen代表生成秘钥; -t(注意区分大小写)表示指定生成的秘钥类型;dsa是dsa密钥认证的意思。即秘钥类型;-P用于提供密语;-f指定生成的秘钥文件。(其中~代表当前用户文件夹,如home/wade ),这条命令会在.ssh文件夹下创建id_dsa及id_dsa.pub两个文件,这是SSH的一对私钥和秘钥,类似于锁和钥匙。
[hadoop@localhost ~]$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
这条命令用于把公钥加到用于认证的公钥文件中。这里的authorized_keys是用于认证的公钥文件。
至此免密码登录本机已配置完毕,可通过ssh 本机IP 测试是否需要密码登录。如果没有提示输入密码,则无密码登录配置成功!
如果确实配置成功了,但是还是不能免密码登陆,这可能就是authorized_keys文件没有访问权限,执行命令:chmod 600 ~/.ssh/authorized_keys 即可!
3、 Hadoop安装和配置
3.0.首先创建专门的hadoop组和用户
创建用户组:hadoop,然后在此用户组下创建hadoop用户。可在安装系统的时候创建,也可以在安装好之后用如下命令创建:
[root@ localhost ~]# groupadd hadoop
[root@ localhost~]# useradd -g hadoop -d /home/hadoop hadoop
“hadoop”是所创建的用户名, -d指明“ hadoop”用户的home目录是/home/hadoop)
[root@ localhost~]# passwd hadoop [给用户hadoop设置口令]
然后解压安装Hadoop
— 到Hadoop官网下载hadoop-1.2.1.tar.gz
— 建立安装目录
[hadoop@ localhost~] mkdir ~/hadoop-env
— 把hadoop-1.2.1.tar.gz放在这里,然后解压:
[hadoop@ localhosthadoop_env]$ tar –zxvf hadoop-1.2.1.tar.gz
注:解压安装生成文件/hadoop-1.2.1(即为hadoop被安装到/home/hadoop/hadoop-env/ hadoop-1. 2.1文件夹下)。
接着来在root用户下配置hadoop的环境变量:
命令“vi /etc/profile”
#set hadoop
export HADOOP_HOME=/home/hadoop/hadoop-env/ hadoop-1. 2.1
export PATH=$HADOOP_HOME/bin:$PATH
最后执行命令:source /etc/profile 使刚配置的文件生效!
3.1 进入/home/hadoop/hadoop-env/ hadoop-1. 2.1/conf,配置Hadoop配置文件
3.1.1 配置hadoop-env.sh文件
打开文件命令:vi hadoop-env.sh
添加 # set java environment
export JAVA_HOME=/usr/program/jdk1.6.0_19
编辑后保存退出。
3.1.2 配置core-site.xml
[hadoop@localhost conf]$ vi core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000/</value> 注:9000后面的“/”不能少
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-env/hadooptmp</value>
</property>
</configuration>
说明:hadoop分布式文件系统的两个重要的目录结构,一个是namenode上名字空间的存放地方,一个是datanode数据块的存放地方,还有一些其他的文件存放地方,这些存放地方都是基于hadoop.tmp.dir目录的,比如namenode的名字空间存放地方就是 ${hadoop.tmp.dir}/dfs/name, datanode数据块的存放地方就是 ${hadoop.tmp.dir}/dfs/data,所以设置好hadoop.tmp.dir目录后,其他的重要目录都是在这个目录下面,这是一个根目录。我设置的是进入/home/hadoop/hadoop-env/ hadoop-1. 2.1/hadooptmp,当然这个目录必须是存在的。
3.1.3 配置hdfs-site.xml
[hadoop@localhost conf]$ vi hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.1.4 配置mapred-site.xml
[hadoop@localhost conf]$ vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
3.1.5 配置masters文件和slaves文件(一般此二文件的默认内容即为下述内容,无需重新配置)
[hadoop@localhost conf]$ vi masters
localhost //注意,此配置文件中的localhost代表本机IP:127.0.0.1 ,而[hadoop@localhost ~]中的localhost仅仅是一个主机名,二者不对等,主机名可以是任意字符串。
[hadoop@localhost conf]$ vi slaves
localhost
注:因为在伪分布模式下,作为master的namenode与作为slave的datanode是同一台服务器,所以配置文件中的ip是一样的。
3.1.6 主机名和IP解析配置 (这一步非常重要!!!)
[root@localhost ~]# vi /etc/hosts
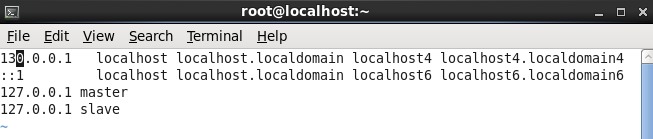
注:因为是在伪分布模式下,所以master与slave是一台机器
补充:若主机名不是localhost,而是我们自己指定一个主机名,则需要按照以下两点进行配置。
1.编辑主机名:
[root@localhost ~]# vi /etc/hostname
内容为:mycentos
[root@localhost ~]# vi /etc/sysconfig/network

2.主机名和IP解析配置 (这一步非常重要!!!)
[root@mycentos ~]# vi /etc/hosts

注:因为是在伪分布模式下,所以master与slave是一台机器
说明:这三个位置的配置必须协调一致,Hadpoop才能正常工作!主机名的配置非常重要!
我在上面的配置中没有修改主机名,还是用的mycentos这个主机名,这样容易出错,最好还是将主机名修改为master,在配置中使127.0.0.1 master对应!
4、 Hadoop启动
4.1 进入 /home/hadoop/hadoop-env/ hadoop-1. 2.1/bin目录下,格式化namenode
[hadoop@localhost bin]$ hadoop namenode -format
然后根据提示选择相应操作,即可完成格式化!
4.2启动hadoop所有进程
在/home/hadoop/hadoop-env/ hadoop-1. 2.1/bin目录下,执行start-all.sh命令
启动完成后,可用[root@master bin]# jps命令查看hadoop进程是否启动完全。正常情况下应该有如下进程:如下如所示:

启动hadoop伪分布式集群成功!
说明:1.secondaryname是namenode的一个备份,里面同样保存了名字空间和文件到文件块的map关系。建议运行在另外一台机器上,这样master死掉之后,还可以通过secondaryname所在的机器找回名字空间,和文件到文件块得map关系数据,恢复namenode。
2.启动之后,在/usr/local/hadoop/hadoop-1.0.1/hadooptmp下的dfs文件夹里会生成 data目录,这里面存放的是datanode上的数据块数据,因为笔者用的是单机,所以name和 data都在一个机器上,如果是集群的话,namenode所在的机器上只会有name文件夹,而datanode上只会有data文件夹。
补充:
在搭建过程中,在此环节出现的问题最多,经常出现启动进程不完整的情况,要么是datanode无法正常启动,就是namenode或是TaskTracker启动异常。解决的方式如下:
1. 在Linux下关闭防火墙:使用service iptables stop命令;关闭hadoop:stop-all.sh
1) 重启后生效
开启: chkconfig iptables on
关闭: chkconfig iptables off
2) 即时生效,重启后失效
开启: service iptables start
关闭: service iptables stop
需要说明的是对于Linux下的其它服务都可以用以上命令执行开启和关闭操作。
在开启了防火墙时,做如下设置,开启相关端口,
修改/etc/sysconfig/iptables 文件,添加以下内容:
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
开始我使用的是service方式,但是总不好用,最后使用了chkconfig重启方式,生效!
2.再次对namenode进行格式化:/home/hadoop/hadoop-env/ hadoop-1. 2.1/bin目录下执行hadoop namenode -format命令
3.对服务器进行重启
4.查看datanode或是namenode对应的日志文件,日志文件保存在/home/hadoop/hadoop-env/ hadoop-1. 2.1/logs目录下。
5.再次在/bin目录下用start-all.sh命令启动所有进程,通过以上的几个方法应该能解决进程启动不完全的问题了。
6.在执行hadoop相关命令时候,总是出现如下提示:

分析:经过查看hadoop-1.2.1的hadoop和hadoop-config.sh脚本,发现对于HADDP_HOME做了判断
解决方法如下:
在hadoop-env.sh ,添加一个环境变量:export HADOOP_HOME_WARN_SUPPRESS=true
4.3 查看集群状态
[hadoop@localhost bin]$ hadoop dfsadmin -report
4.4、在WEB页面下查看Hadoop工作情况
4.4.1打开IE浏览器输入部署Hadoop服务器的IP:http://localhost:50070;
示意图略
4.4.2输入:http://localhost:50030
示意图略
5. Hadop使用(一个测试例子wordcount)
计算输入文本中词语数量的程序。WordCount在Hadoop主目录下的java程序包hadoop-examples-1.2.1.jar中,执行步骤如下:
5.1. 首先启动hadoop所有进程:bin/start-all.sh,然后在/home/hadoop/hadoop-env/ hadoop-1. 2.1/下新建目录test,可任意命名),在test下创建文本file01、file02,分别输入数个单词。
5.2.在hdfs分布式文件系统创建目录input:
[hadoop@localhost bin]$hadoop fs -mkdir input
然后可以使用 [hadoop@localhost bin]$hadoop fs -ls查看:
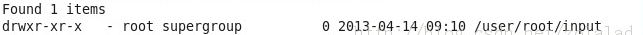
注:删除目录: [hadoop@localhost bin]$hadoop fs -rmr ***;删除文件:hadoop fs -rm ***
5.3.离开hodoop的安全模式 [hadoop@localhost bin]$hadoop dfsadmin –safemode leave
注:Hadoop的安全模式相关命令 [hadoop@localhost bin]$hadoop dfsadmin –safemode enter/leave/get/wait
Hadoop的HDFS系统在安全模式下只能进行“读”操作!不能进行文件等的删除,创建和更新操作!
5.4.将数据从linux文件系统复制到HDFS分布式文件系统中的input文件夹中:
[hadoop@localhost bin]$hadoop fs -put /home/hadoop/hadoop-env/hadoop-1.2.1/test/* input
5.5.执行例子中的WordCount:
[hadoop@localhost bin]$hadoop jar/home/hadoop/hadoop-env/hadoop-1.2.1/hadoop-examples-1.2.1.jar wordcount input output
参考:

5.6.查看执行结果: [hadoop@localhost bin]$hadoop dfs -cat output/*

5.7.执行完毕后,可进入web界面刷新查看running job及completed job的显示。
5.8.关闭hadoop所有进程: [hadoop@localhost bin]$stop-all.sh。
说明:以上配置步骤本人亲自动手实践,证明是可行的!可能不是最优的配置方法,欢迎学友指正批评!
本文出处:
http://blog.csdn.net/zolalad/article/details/11472207
本人亲自实验,搭建成功,感谢原作者的分享!















 5846
5846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









