







Trident在读写有状态的数据源方面是有着一流的抽象封装的。状态即可以保留在topology的内部,比如说内存和HDFS,也可以放到外部存储当中,比如说Memcached或者Cassandra。这些都是使用同一套Trident API。
Trident以一种容错的方式来管理状态以至于当你在更新状态的时候你不需要去考虑错误以及重试的情况。这种保证每个消息被处理有且只有一次的原理会让你更放心的使用Trident的topology。
在进行状态更新时,会有不同的容错级别。在外面一起来讨论这点之前,让我们先通过一个例子来说明一下如果想要坐到有且只有一次处理的必要的技巧。假定你在做一个关于某stream的计数聚合器,你想要把运行中的计数存放到一个数据库中。如果你在数据库中存了一个值表示这个计数,每次你处理一个tuple之后,就将数据库存储的计数加一。
当错误发生,truple会被重播。这就带来了一个问题:当状态更新的时候,你完全不知道你是不是在之前已经成功处理过这个tuple。也许你之前从来没处理过这个tuple,这样的话你就应该把count加一。另外一种可能就是你之前是成功处理过这个tuple的,但是这个在其他的步骤处理这个tuple的时候失败了,在这种情况下,我们就不应该将count加一。再或者,你接受到过这个tuple,但是上次处理这个tuple的时候在更新数据库的时候失败了,这种情况你就应该去更新数据库。
如果只是简单的存计数到数据库的话,你是完全不知道这个tuple之前是否已经被处理过了的。所以你需要更多的信息来做正确的决定。Trident提供了下面的语义来实现有且只有一次被处理的目标。
- Tuples 是被分成小的集合被批量处理的 (see the tutorial)
- 每一批tuples被给定一个唯一ID作为事务ID (txid). 当这一批tuple被重播时, txid不变.
- 批与批之间的状态更新时严格顺序的。比如说第三批tuple的状态的更新必须要等到第二批tuple的状态更新成功之后才可以进行.
Transactional spouts
记住,Trident是以小批量(batch)的形式在处理tuple,并且每一批都会分配一个唯一的transaction id。 不同的spout会根据他们可以给予不同的批量tuple的guarantee的能力有不同的属性。一个transactional spout会有如下这些属性:
1. 有着同样txid的batch一定是一样的。当重播一个txid对应的batch时,一定会重播和之前对应txid的batch中同样的tuples。
2. 各个batch之间是没有交集的。每个tuple只能属于一个batch
3. 每一个tuple都属于一个batch,无一例外
这是一类非常容易理解的spout, tuple 流被划分为固定的batch并且永不改变。trident-kafka 有一个 transactional spout 的实现.
你也许会问:为什么我们不总是使用transactional spout?这很容易理解。一个原因是并不是所有的地方都需要容错的。举例来说,TransactionalTridentKafkaSpout 工作的方式是给定一个txid的batch所包含的一个属于一个topic的来自于所有Kafka partition的tuple序列。一旦这个batch被发出,在任何时候如果这个batch被重新发出时,它必须包含原来所有的tuple以满足 transactional spout的语义。现在我们假定一个batch被TransactionalTridentKafkaSpout所发出,这个batch没有被成功处理,并且同时kafka的一个节点也down掉了。你就无法像之前一样重播一个完全一样的batch(因为kakfa的节点down掉,该topic的一部分partition可能会无法使用),整个处理会被中断。
这也就是"opaque transactional" spouts(不透明事务spout)存在的原因- 他们对于丢失源节点这种情况是容错的,仍然能够帮你达到有且只有一次处理的语义。后面会对这种spout有所介绍。
(当然,在Kafka开启replication功能时,transactional spout也是可以做到容错的)
在外面来讨论"opaque transactional" spout之前,我们先来看看你应该怎样设计一个State来实现transactional spout的有且只有一次执行的语义。这个State的类型是"transactional state" 并且它利用了任何一个txid总是对应同样的tuple序列这个语义。
假如说你有一个用来计算单词出现次数的topology,你想要将单词的出现次数以key/value对的形式存储到数据库中。key就是单词,value就是这个这个单词出现的次数。你已经看到只是存储一个数量是不足以知道你是否已经处理过一个batch的。你可以通过将value和txid一起存储到数据库中。这样的话,当更新这个count之前,你可以先去比较数据库中存储的txid和现在要存储的txid。如果一样,就跳过什么都不做,因为这个value之前已经被处理过了。如果不一样,就执行存储。这个逻辑可以工作的前提就是txid永不改变,并且Trident保证状态的更新是在batch之间严格顺序进行的。
考虑下面这个例子的运行逻辑, 假定你在处理一个txid为3的包含下面tuple的batch:
假定数据库中当前保存了下面这样的key/value 对:
单词“man”对应的txid是1. 因为当前的txid是3,你可以确定你还没有为这个batch中的tuple更新过这个单词的数量。所以你可以放心的给count加2并更新txid为3. 与此同时,单词“dog”的txid和当前的txid是相同的,因此你可以跳过这次更新。此时数据库中的数据如下:
接下来我们一起再来看看 opaque transactional spout已经怎样去为这种spout设计相应的state。
Opaque transactional spouts
正如之前说过的,opaque transactional spout并不能确保一个txid所对应的batch的一致性。一个opaque transactional spout有如下属性:
每个tuple只在一个batch中被成功处理。然而,一个tuple在一个batch中被处理失败后,有可能会在另外的一个batch中被成功处理。Opaque TridentKafkaSpout 是一个拥有这种属性的spout,并且它是容错的,即使Kafak的节点丢失。当OpaqueTridentKafkaSpout 发送一个batch的时候, 它会从上个batch成功结束发送的位置开始发送一个tuple序列。这就确保了永远没有任何一个tuple会被跳过或者被放在多个batch中被多次成功处理的情况。
使用opaque transactional spout,再使用和transactional spout相同的处理方式:判断数据库中存放的txid和当前txid去做对比已经不好用了。这是因为在state的更新过程之间,batch可能已经变了。你只能在数据库中存储更多的信息。除了value和txid,你还需要存储之前的数值在数据库中。让我们还是用上面的例子来说明这个逻辑。假定你当前batch中的对应count是“2”, 并且我们需要进行一次状态更新。而当前数据库中存储的信息如下:
如果你当前的txid是3, 和数据库中的txid不同。那么就将value中的值设置到prevValue中,根据你当前的count增加value的值并更新txid。更新后的数据库信息如下:
现在外面再假定你的当前txid是2,和数据库中存放的txid相同。这就说明数据库里面value中的值包含了之前一个和当前txid相同的batch的更新。但是上一个batch和当前这个batch可能已经完全不同了,以至于我们需要无视它。在这种情况下,你需要在prevValue的基础上加上当前count的值并将结果存放到value中去。数据库中的信息如下所示:
Non-transactional spouts
Non-transactional spout(非事务spout)不确保每个batch中的tuple的规则。所以他可能是最多被处理一次的,如果tuple被处理失败就不重发的话。同时他也可能会是至少处理一次的,如果tuple在不同的batch中被多次成功处理的时候。无论怎样,这种spout是不可能实现有且只有一次被成功处理的语义的。
Summary of spout and state types
这个图展示了哪些spout和state的组合能够实现有且只有一次被成功处理的语义:
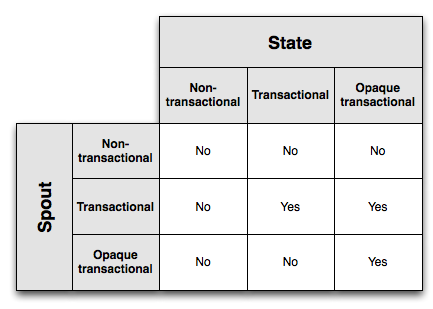
Opaque transactional state有着最为强大的容错性。但是这是以存储更多的信息作为代价的。Transactional states 需要存储较少的状态信息,但是仅能和 transactional spouts协同工作. Finally, non-transactional state所需要存储的信息最少,但是却不能实现有且只有一次被成功处理的语义。
State和Spout类型的选择其实是一种在容错性和存储消耗之间的权衡,你的应用的需要会决定那种组合更适合你。
State APIs
你已经看到一些错综复杂的方法来实现有且只有一次被执行的语义。Trident这样做的好处把所有容错想过的逻辑都放在了State里面。 作为一个用户,你并不需要自己去处理复杂的txid,存储多余的信息到数据库中,或者是任何其他类似的事情。你只需要写如下这样简单的code:
所有管理 opaque transactional state所需的逻辑都在MemcachedState.opaque方法的调用中被涵盖了,除此之外,数据库的更新会自动以batch的形式来进行以避免多次访问数据库。
State的基本接口只包含下面两个方法:
当一个State更新开始时,以及当一个State更新结束时你都会被告知,并且会告诉你该次的txid。Trident并没有对你的state的工作方式有任何的假定。
假定你自己搭了一套数据库来存储用户位置信息,并且你想要在Trident中去访问这个数据。你的state的实现应该有用户信息的set、get方法
然后你还需要提供给Trident一个StateFactory来在Trident的task中创建你的State对象。LocationDB 的 StateFactory可能会如下所示:
Trident提供了一个QueryFunction接口用来实现Trident中在一个source state上查询的功能。同时还提供了一个StateUpdater来实现Trident中更新source state的功能。比如说,让我们写一个查询地址的操作,这个操作会查询LocationDB来找到用户的地址。让我们以怎样在topology中实现该功能开始,假定这个topology会接受一个用户id作为输入数据流。
接下来让我们一起来看看QueryLocation 的实现应该是什么样的:
QueryFunction的执行分为两部分。首先Trident收集了一个batch的read操作并把他们统一交给batchRetrieve。在这个例子中,batchRetrieve会接受到多个用户id。batchRetrieve应该返还一个和输入tuple数量相同的result序列。result序列中的第一个元素对应着第一个输入tuple的结果,result序列中的第二个元素对应着第二个输入tuple的结果,以此类推。
你可以看到,这段代码并没有想Trident那样很好的利用batch的优势,而是为每个输入tuple去查询了一次LocationDB。所以一种更好的操作LocationDB方式应该是这样的:
接下来,你可以这样改写上面的QueryLocation:
通过有效减少访问数据库的次数,这段代码比上一个实现会高效的多。
如何你要更新State,你需要使用StateUpdater接口。下面是一个StateUpdater的例子用来将新的地址信息更新到LocationDB当中。
下面列出了你应该如何在Trident topology中使用上面声明的LocationUpdater:
partitionPersist 操作会更新一个State。其内部是将 State和一批更新的tuple交给StateUpdater,由StateUpdater完成相应的更新操作。
在这段代码中,只是简单的从输入的tuple中提取处userid和对应的location,并一起更新到State中。
partitionPersist 会返回一个TridentState对象来表示被这个Trident topoloy更新过的location db。 然后你就可以使用这个state在topology的任何地方进行查询操作了。
同时,你也可以看到我们传了一个TridentCollector给StateUpdaters。 emit到这个collector的tuple就会去往一个新的stream。在这个例子中,我们并没有去往一个新的stream的需要,但是如果你在做一些事情,比如说更新数据库中的某个count,你可以emit更新的count到这个新的stream。然后你可以通过调用TridentState#newValuesStream方法来访问这个新的stream来进行其他的处理。
persistentAggregate
Trident有另外一种更新State的方法叫做persistentAggregate。 你在之前的word count例子中应该已经见过了,如下:
persistentAggregate是在partitionPersist之上的另外一层抽象。它知道怎么去使用一个Trident 聚合器来更新State。在这个例子当中,因为这是一个group好的stream,Trident会期待你提供的state是实现了MapState接口的。用来进行group的字段会以key的形式存在于State当中,聚合后的结果会以value的形式存储在State当中。MapState接口看上去如下所示:
当你在一个未经过group的stream上面进行聚合的话,Trident会期待你的state实现 Snapshottable接口:
MemoryMapState 和 MemcachedState 都实现了上面的2个接口。
Implementing Map States
在Trident中实现MapState是非常简单的,它几乎帮你做了所有的事情。OpaqueMap, TransactionalMap, 和 NonTransactionalMap 类实现了所有相关的逻辑,包括容错的逻辑。你只需要将一个IBackingMap 的实现提供给这些类就可以了。IBackingMap接口看上去如下所示:
OpaqueMap's会用OpaqueValue的value来调用multiPut方法,TransactionalMap's会提供TransactionalValue中的value,而NonTransactionalMaps只是简单的把从Topology获取的object传递给multiPut。
Trident还提供了一种CachedMap类来进行自动的LRU cache。
另外,Trident 提供了 SnapshottableMap 类将一个MapState 转换成一个 Snapshottable 对象.
大家可以看看 MemcachedState的实现,从而学习一下怎样将这些工具组合在一起形成一个高性能的MapState实现。MemcachedState是允许大家选择使用opaque transactional, transactional, 还是 non-transactional 语义的。














 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









