









文章目录
前言
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
文章标题:Neural Machine Translation by Jointly Learning to Align and Translate
基于联合学习对齐和翻译的神经机器翻译
作者:Dzmitry Bahdanau1, KyungHyun Cho2, Yoshua Bengio*2
单位:1不来梅雅克布大学Jacobs University Bremen, Germany,2蒙特利尔大学Universite de Montr ´ eal
发表会议及时间:ICLR 2015综合性会议
在线LaTeX公式编辑器
中文参考:https://zhuanlan.zhihu.com/p/36699992
第一课时:论文导读
基于词的对齐翻译
真·一字一句翻译:
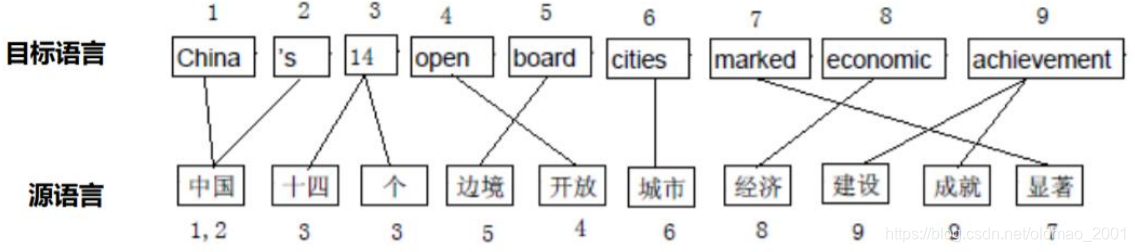
看上去很简单,但是对于复杂句式来说就是噩梦:

为了对齐看上去不这么复杂,提出了基于短语的对齐翻译(phrase-based translation):
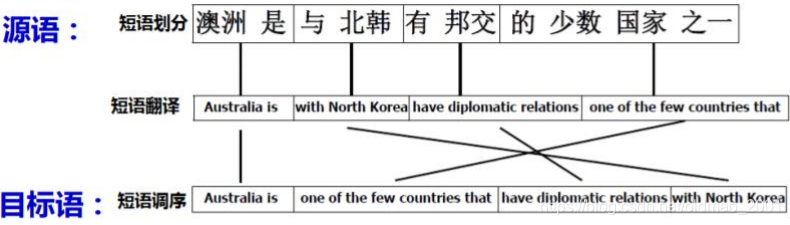
这种方式看上去简单而已,其实实现起来无比复杂,一个完整的基于短语的对齐翻译框架需要50万行代码,而基于NN的翻译只需要500行左右即可。
机器翻译简介
机器翻译,又称为自动翻译,是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。机器翻译是计算语言学的一个分支,是人工智能的终极目标之一,具有重要的科学研究价值。同时,机器翻译又具有重要的实用价值。随着经济全球化及互联网的飞速发展,机器翻译技术在促进政治、经济、文化交流等方面起到越来越重要的作用。
机器翻译发展历史The history of machine translation
趋势:让机器更“自主”地学习如何翻译
1980:基于规则的翻译
1990:基于统计的翻译
2013:基于神经网络的翻译
基于规则的机器翻译Rule-based machine translation
基于规则的机器翻译,是最古老也是见效最快的一种翻译方式。根据翻译的方式可以分为:
·直接基于词的翻译
·结构转换的翻译
·中间语的翻译
大致流程:
输入——词性分析——词典查询——语序调整——输出
举个例子:
we do chicken right—— we do chiken right ——我们做鸡右——我们像鸡右—我们做鸡右
这种翻译方式高度依赖专家,专家必须精通源语言和目标语言的知识。开发周期也比较长。
基于统计的机器翻译Statistical machine translation
基本思想:通过对大量的平行语料进行统计分析,构建统计翻译模型,进而使用此模型进行翻译。
核心问题:为翻译过程建立概率模型。
大致流程:
输入——基于词的翻译——查询语料库——统计概率——输出
其中
θ
\theta
θ是模型参数。这个概率模型不好确定,因为语言有很大随意性,可以产生各种各样的句子,不好建立直接的映射关系。
隐变量:生产过程中不可观测的随机变量
隐变量对数线性模型:在隐式语言结构上设计特征
关键问题:如何设置特征函数
下图中隐变量为z
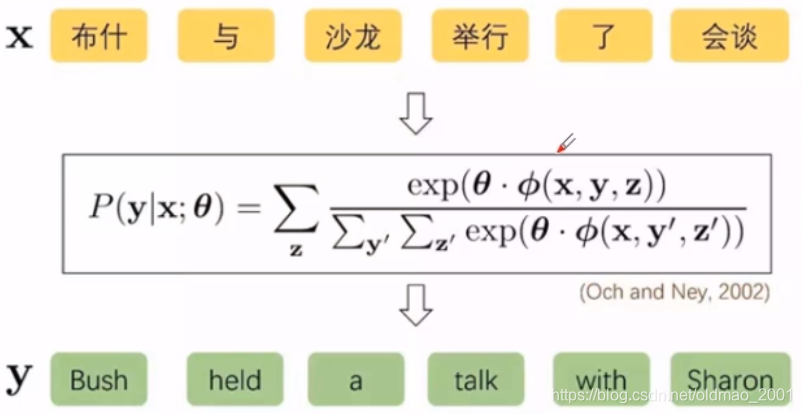
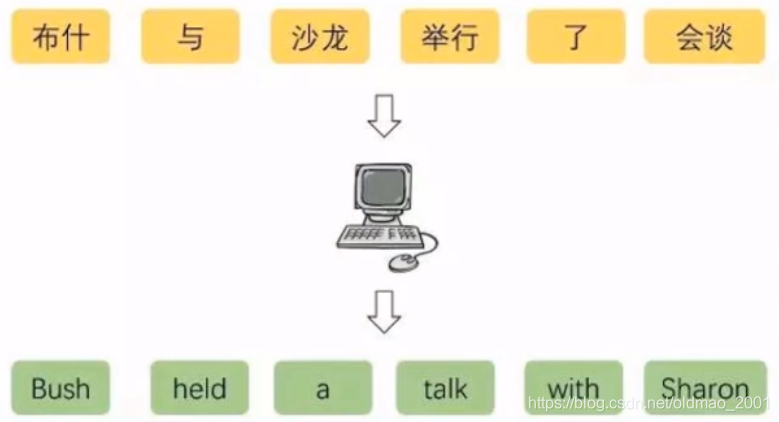
基于神经网络的机器翻译Neural Machine Translation
基于神经网络的机器翻译:通过学习大量成对的语料让神经网络自己学习语言的特征,找到输入和输出之间的关系。
核心思想:端到端(End-to-End)
2014年时,Kyunghyun Cho和Sutskever 先后提出了一种End-to-End即所谓【端到端】的模型,直接对输入输出建立联系。前者将其模型命名为Encoder-Decoder 模型,后者则将其命名为Sequence-to-Sequence模型。
基本思想:利用神经网络实现自然语言的映射
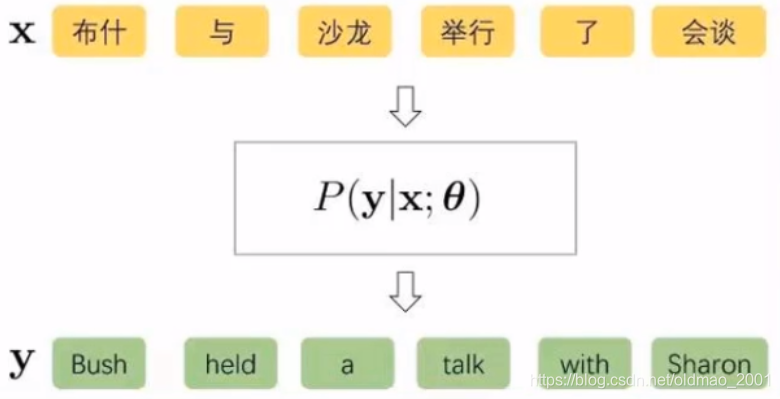
核心问题:条件概率建模
P
(
y
n
∣
x
,
y
<
n
;
θ
)
P(y_n|x,y_{<n};\theta)
P(yn∣x,y<n;θ)
y
n
y_n
yn: 当前目标语言词
x
x
x:源语言句子
y
<
n
y_{<n}
y<n:已经生成的目标语言句子
例如下图中,
N
N
N为目标语言的长度,
y
n
y_n
yn代表第n个词,
x
x
x代表整个中文句子,
y
<
n
y_{<n}
y<n已经生成的英文句子,图中公式的意思就是已知源语言句子和已经翻译好的句子,预测目标词。但是问题是源语言句子和已经翻译好的目标语言句子是非常稀疏的,可以生成各种各样的句子,很难用传统的离散表示来建立概率分布。而深度学习可以使用连续的表示来对条件概率进行建模。
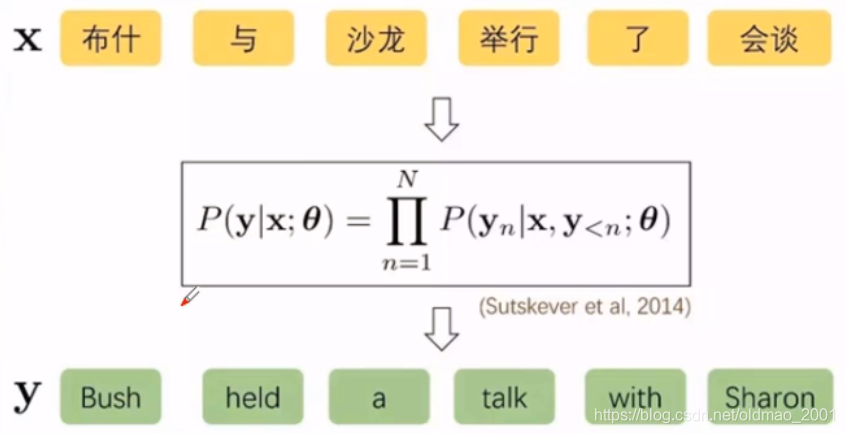
如何对条件概率进行建模?
P
(
y
n
∣
x
,
y
<
n
;
θ
)
P(y_n|x,y_{<n};\theta)
P(yn∣x,y<n;θ)
=
e
x
p
(
φ
(
y
n
,
x
,
y
<
n
,
θ
)
)
∑
y
∈
Y
e
x
p
(
φ
(
y
,
x
,
y
<
n
,
θ
)
)
=\frac{exp(\varphi(y_n,x,y_{<n},\theta))}{\sum_{y\in Y}exp(\varphi(y,x,y_{<n},\theta))}
=∑y∈Yexp(φ(y,x,y<n,θ))exp(φ(yn,x,y<n,θ))
=
e
x
p
(
φ
(
V
y
n
,
c
s
,
c
t
,
θ
)
)
∑
y
∈
Y
e
x
p
(
φ
(
V
y
,
c
s
,
c
t
,
θ
)
)
=\frac{exp(\varphi(V_{y_n},c_s,c_t,\theta))}{\sum_{y\in Y}exp(\varphi(V_{y},c_s,c_t,\theta))}
=∑y∈Yexp(φ(Vy,cs,ct,θ))exp(φ(Vyn,cs,ct,θ))
V
y
V_{y}
Vy:目标语言词向量
Y
Y
Y:目标语言词汇
c
s
c_s
cs:源语言上下文向量
c
t
c_t
ct:目标语言上下文向量
句子的向量表示
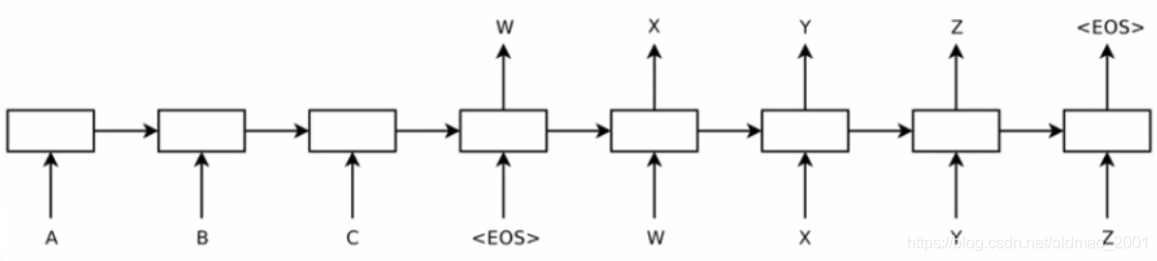
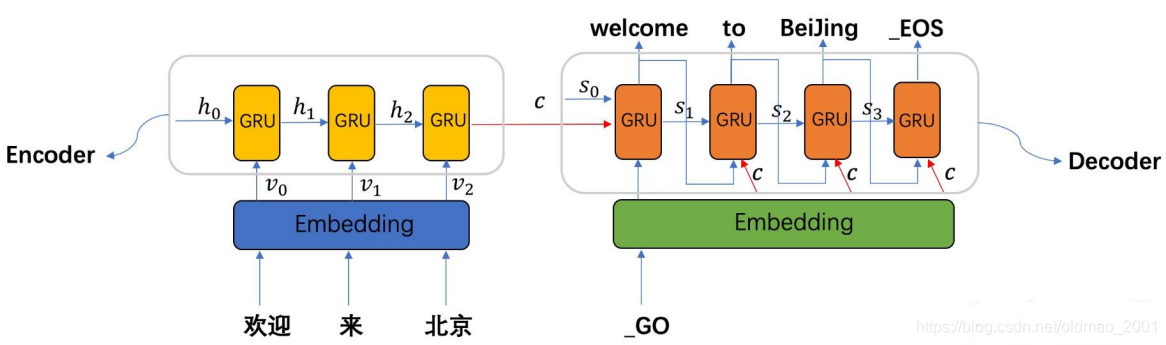
利用循环神经网络(RNN)计算句子的向量表示
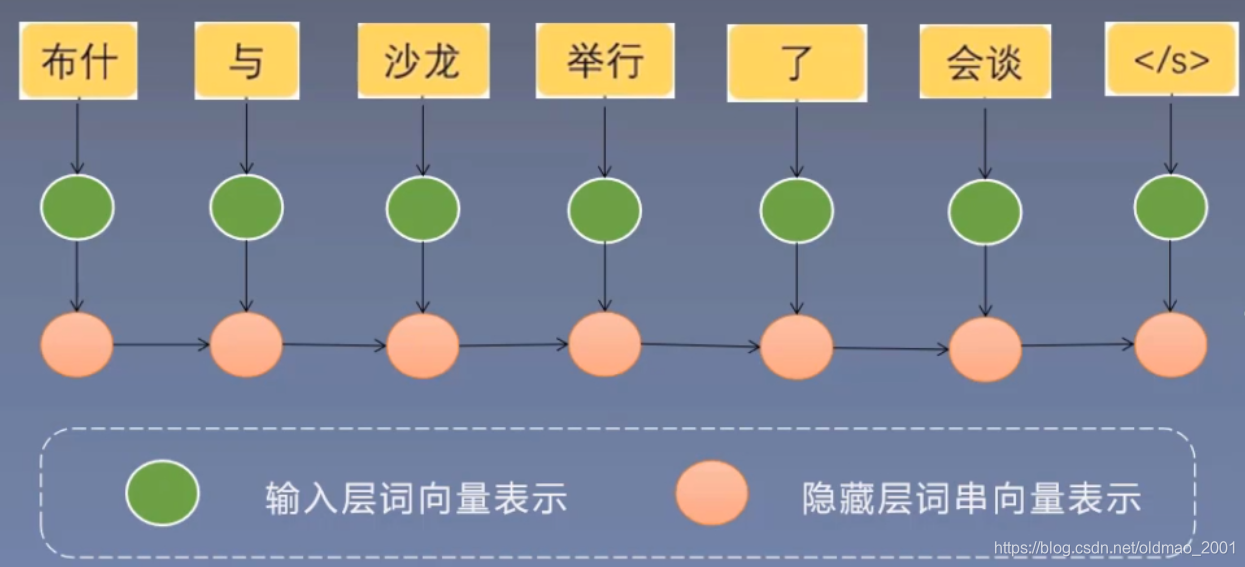
词向量可以用Word2Vec来生成。/s代表句子的结束。
最后那个红色的○就是对整个句子的编码,它存储了整个句子的语义信息。
神经机器翻译相关技术
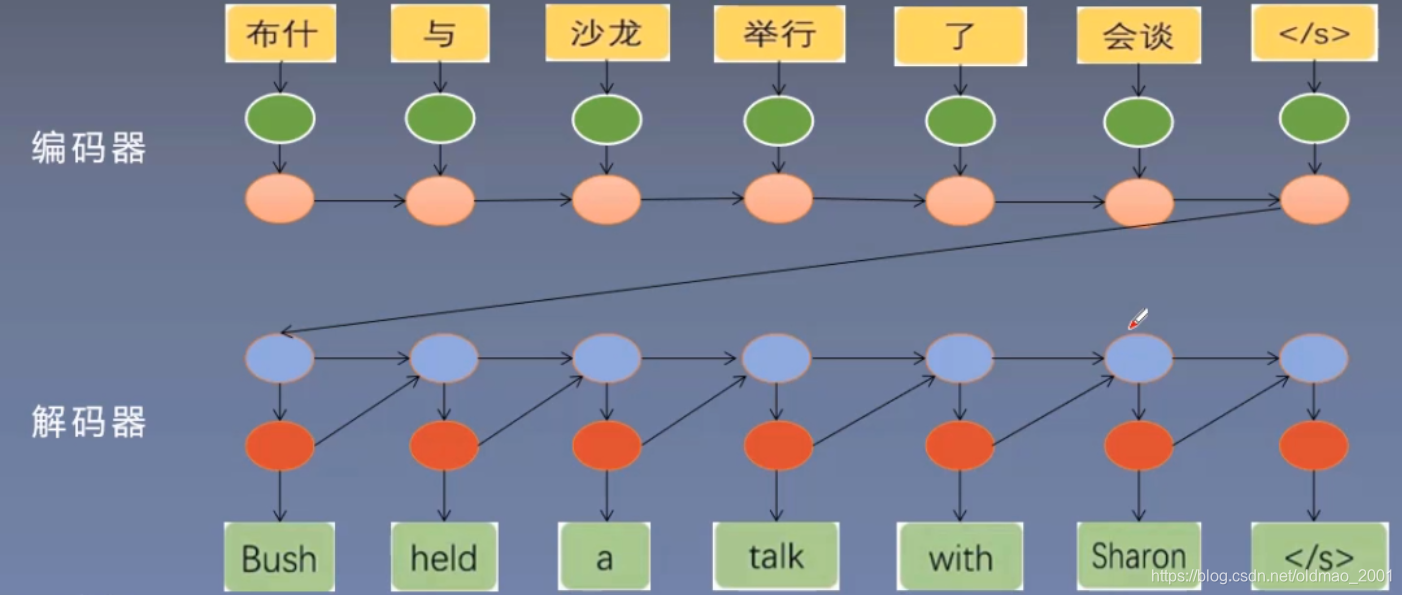
编码器-解码器框架
Encoder-Decoder
利用循环神经网络(RNN)实现源语言的编码和目标语言的解码。
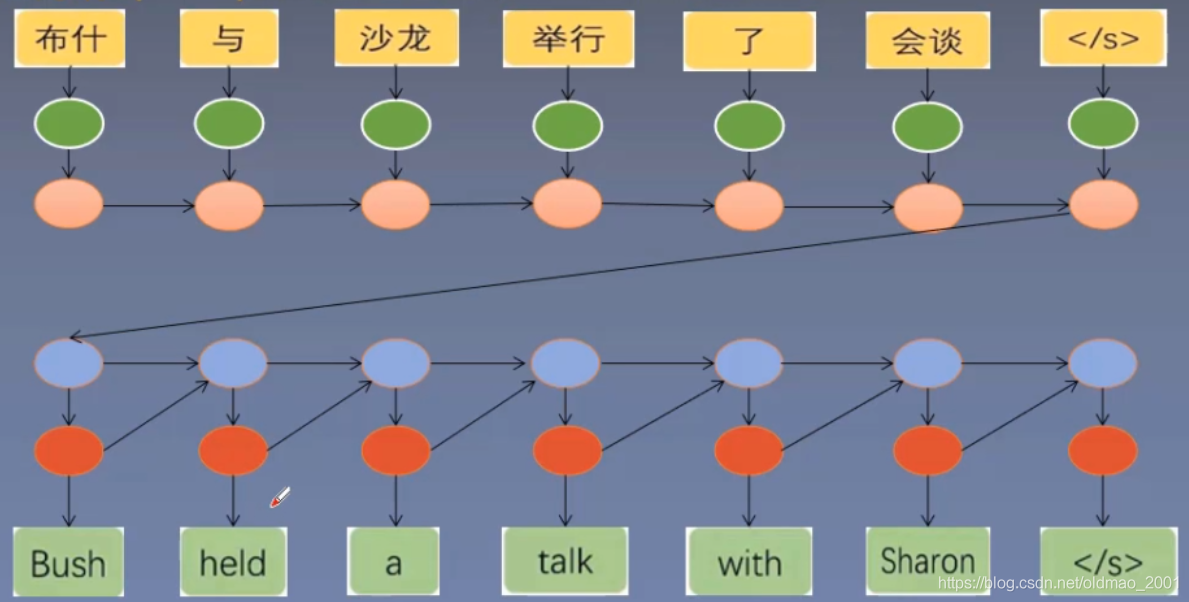
另外一个图如下:
优点:利用长短时记忆处理长距离依赖
缺点有两个方面:
- 任意长度的句子都编码为固定维度的向量,这个向量表示能力有限,对于长句,肯定会丢失一些信息。(不管句子有多长,都压缩在了最后那个红色○,句子越长丢的信息越多);
- 在翻译为目标语言的过程中,会依次的在蓝色圈圈中传递,例如传递到第三个蓝色圈圈的时候模型会丢失部分目标原语言的上下文信息。
对于问题2解决方法如下图所示,将源语言Encoder得到的最终向量(红色圈圈)作为Decoder每一个时间步计算结果的输入,这样保证每个时间步都拿到完整的源语言信息。
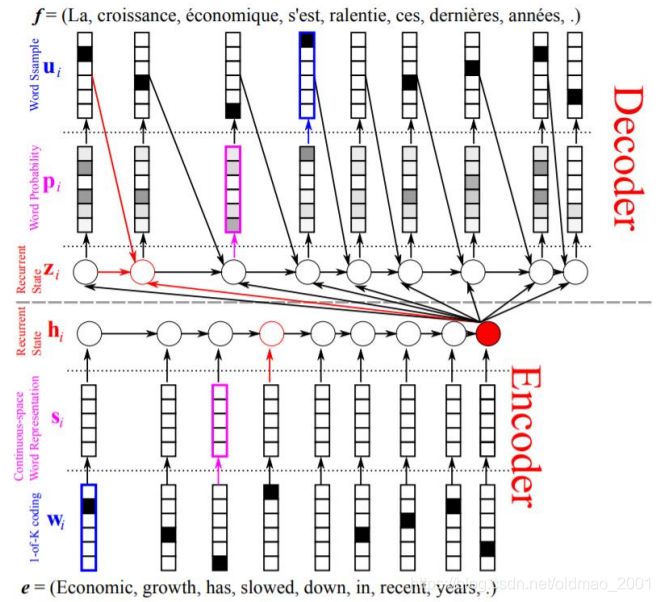
对于问题1,解决方案就是注意力机制
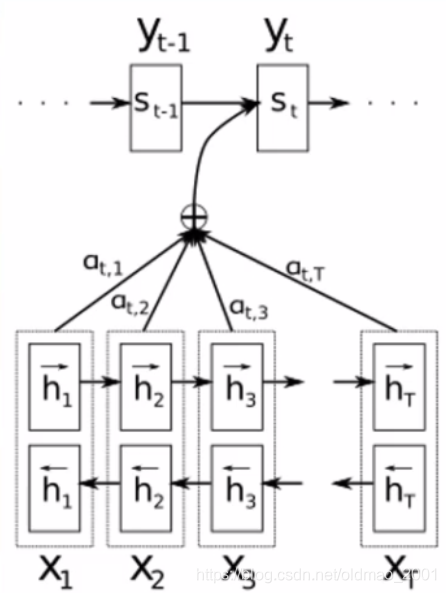
·借助对齐的思想,当Decoder翻译到第t个词时,从Encoder中寻找和第t个目标语言词相关的源语言词用于第t个词的翻译。下图是原文注意力机制图示。
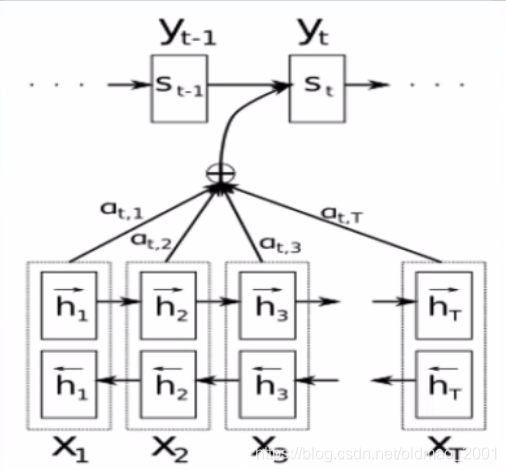
前期知识储备
概率论:了解基本的概率论知识,掌握条件概率的概念和公式
RNN:了解循环神经网络(RNN)的结构,掌握RNN的基本工作原理
机器翻译:了解机器翻译的概念,掌握神经机器翻译的流程
注意力机制:了解注意力机制的思想,掌握注意力机制的分类和实现方式
作业
- 简述你理解的机器翻译。
机器翻译经历了基于规则=>基于统计=>神经网络的过程,趋势是让“机器”更自主的学习,不需要人为去从语法或者匹配的角度干预。 - 简述你学习到的神经机器翻译过程。
最开始是decoder=>encoder,所有的源语言的信息全部压缩到固定(fixed length)向量的decoder的最后一个结点,即使用LSTM,这种在长句子的方向表现并不好;所以本文的思路是“边读边翻译”,当翻译目标词的时候,模型自己确定去源语言中的那些词与之对应,这通过权重得到。 - 列举三个学习完本课程的问题。
略
第二课时 论文精读
学习论文的算法原理,掌握算法的流程和实现方式
下面内容copy自课程说明:
本阶段论文精读的视频课分为两小节,第一节首先介绍了论文的整体框架,这部分我们根据论文结构和摘要理清作者的写研究和写作思路;然后讲解了传统模型结构的实现,这部分我们针对传统编码器-解码器框架下的RNNenc模型进行详细的讲解,为之后学习改进模型打下基础。第二节带领大家详细学习论文提出的改进模型RNNsearch模型,之后还介绍了注意力机制在其他领域的应用,然后这部分我们讲解论文实验中的一些设置和并且分析了实验结果。最后我们进行了论文的讨论和总结,并展望该领域未来的发展方向。
论文整体框架
小标题
- Introduction
- Background:Neural Machine Translation
2.1 RNN Encoder-Decoder - Learning to Align and Translate
3.1 Decoder:General Description
3.2 Encoder:Bidirectional RNN and Annotating Sequences - Experiment Setting
4.1 Dataset
4.2 Models - Results
5.1 Quantitative Results
5.2 Qualitative Analysis
5.2.1Alignment
5.2.2 Long Sentences - Related Work
6.1 Learning to Align
6.2 Neural Networks for Machine Translation - Conclusion
摘要
- 神经机器翻译是一种不同于统计机器翻译的新方法,它构建一个端对端的网络模型来最大化翻译效果。神经机器翻译的任务定义:
Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building a single neural network that can be jointly tuned to maximize the translation performance. - 这种基于Encoder-Decoder的机器翻译模型中的Encoder将源语言句子编码成一个固定长度的向量,这会限制神经机器翻译的效果。传统神经机器翻译所用的编码器-解码器模型的缺陷:
The models proposed recently for neural machine translation often belong to a family of encoder–decoders and encode a source sentence into a fixed-length vector from which a decoder generates a translation. - 本文为了克服这个问题,使用基于注意力机制的机器翻译方法,这种方法能够自动搜索源语言中和当前要翻译的词相关的词来辅助翻译。本文提出一种能够自动搜索原句中与预测目标词相关的神经机器翻译模型:
In this paper, we conjecture that the use of a fixed-length vector is a bottleneck in improving the performance of this basic encoder–decoder architecture, and propose to extend this by allowing a model to automatically (soft-)search for parts of a source sentence that are relevant to predicting a target word, without having to form these parts as a hard segment explicitly. - 通过这种基于注意力机制的机器翻译模型,我们达到了和统计机器翻译相比差不多的结果,并且实验发现这种对齐效果非常好,和我们直觉一致。所提出模型的效果:英语翻译为法语得到了SOTA。
With this new approach, we achieve a translation performance comparable to the existing state-of-the-art phrase-based system on the task of English-to-French translation. Furthermore, qualitative analysis reveals that the (soft-)alignments found by the model agree well with our intuition.
背景
- 相对于传统的统计机器翻译,基于Encoder-Decoder机制的神经机器翻译具有很多优点。
Neural machine translation is a newly emerging approach to machine translation, recently proposed by Kalchbrenner and Blunsom (2013), Sutskever et al. (2014) and Cho et al. (2014b). Unlike the traditional phrase-based translation system (see, e.g., Koehn et al., 2003) which consists of many small sub-components that are tuned separately, neural machine translation attempts to build and train a single, large neural network that reads a sentence and outputs a correct translation. - 但是之前关于Encoder-Decoder的方法都是使用Encoder将源语言编码成一个固定维度的向量,这会带来一些问题。
Most of the proposed neural machine translation models belong to a family of encoder–decoders (Sutskever et al., 2014; Cho et al., 2014a), with an encoder and a decoder for each language, or involve a language-specific encoder applied to each sentence whose outputs are then compared (Hermann and Blunsom, 2014). An encoder neural network reads and encodes a source sentence into a fixed-length vector. A decoder then outputs a translation from the encoded vector. The whole encoder–decoder system, which consists of the encoder and the decoder for a language pair, is jointly trained to maximize the probability of a correct translation given a source sentence.
A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. This may make it difficult for the neural network to cope with long sentences, especially those that are longer than the sentences in the training corpus. Cho et al. (2014b) showed that indeed the performance of a basic encoder–decoder deteriorates rapidly as the length of an input sentence increases. - 为了解决这一问题,本文使用注意力机制同时学习对齐和翻译从而在Decoder的每一个时间步选择Encoder的很多输出中的一个子集用于Decoder当前时间步的预测。
In order to address this issue, we introduce an extension to the encoder–decoder model which learns to align and translate jointly. Each time the proposed model generates a word in a translation, it (soft-)searches for a set of positions in a source sentence where the most relevant information is concentrated. The model then predicts a target word based on the context vectors associated with these source positions and all the previous generated target words.
The most important distinguishing feature of this approach from the basic encoder–decoder is that it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector. We show this allows a model to cope better with long sentences. - 本文提出的AttentionNMT方法不仅能够提高长度的翻译效果,在短句上翻译效果也有提高,并且最终在WMT14英语到法语任务上取得了很好的效果。
In this paper, we show that the proposed approach of jointly learning to align and translate achieves significantly improved translation performance over the basic encoder–decoder approach. The improvement is more apparent with longer sentences, but can be observed with sentences of any length. On the task of English-to-French translation, the proposed approach achieves, with a single model, a translation performance comparable, or close, to the conventional phrase-based system. Furthermore, qualitative analysis reveals that the proposed model finds a linguistically plausible (soft-)alignment between a source sentence and the corresponding target sentence.
论文总结
关键点
·之前的Encoder-Decoder模型的Encoder将源语言编码成固定长度的向量,这限制了神经机器翻译的表现。
·通过注意力机制同时学习对齐和翻译。
·Attention NMT模型。
创新点
·提出了一种新的神经机器翻译模型–Attention NMT模型
·Attention NMT能够同时学习源语言到目标语言的对齐和翻译。
·在WMT14英语到法语翻译上得到了非常好的结果。
启发点
·之前的Seq2Seq模型一个潜在的问题就是Encoder将源语言句子的所有信息压缩成一个固定维度的向量。
A potential issue with this encoder-decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector(Introduction P3)
·为了解决这一问题,我们扩展了Encoder-Decoder模型,使得它能够同时学习对齐和翻译。
In order to address this issue,we introduce an extension to the encoder-decoder model which learns to align and translate jointly.(Introduction P4)
传统模型讲解
介绍改进前的RNNenc模型
任务定义
该模型采用1到K编码的字向量的源语言句子作为输入:
X
=
(
x
1
,
.
.
.
,
x
T
x
)
,
x
i
∈
ℜ
K
x
X=(x_1,...,x_{T_x}),x_i\in \real^{K_x}
X=(x1,...,xTx),xi∈ℜKx
K
x
K_x
Kx表示源语言中单词表的大小,
T
x
T_x
Tx是源语言的句子长度
并输出由1到K编码的字向量的目标语言句子:
Y
=
(
y
1
,
.
.
.
,
y
T
y
)
,
y
i
∈
ℜ
K
y
Y=(y_1,...,y_{T_y}),y_i\in \real^{K_y}
Y=(y1,...,yTy),yi∈ℜKy
K
y
K_y
Ky表示目标语言中单词表的大小,
T
y
T_y
Ty是目标语言的句子长度
任务目标:评估函数:
a
r
g
m
a
x
y
p
(
y
∣
x
)
argmax_yp(y|x)
argmaxyp(y∣x),即给定源语言句子,在寻找x的条件下,生成目标语言句子y时,最大的条件概率下所对应的目标语言句子y。
编码器-解码器框架(基线)Encoder-Decoder(baseline)
第一步:对于源语言的每个词,都生成一个词向量

第二步:从左到右,通过RNN来生成隐变量的表示
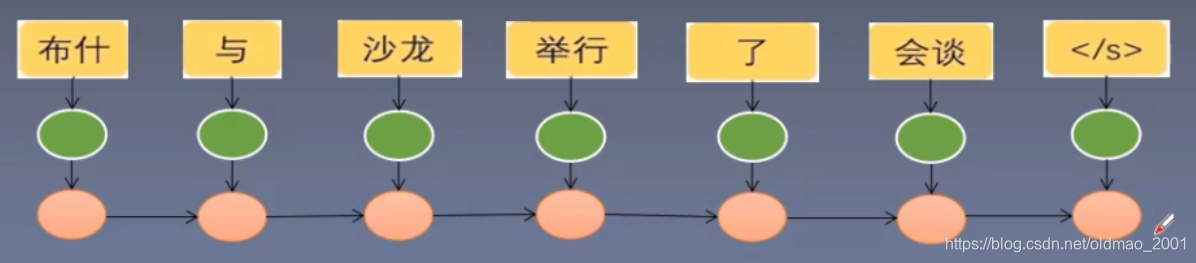
当生成最后一个隐节点是,就完成了对整个句子的语义信息进行了编码。
然后利用解码器从最后一个隐节点开始一个一个的恢复出目标词。
关于encoder-decoder的论文来源:《Learning phrase representations using RNN encoder-decoder for statistical machine translation》
学习使用RNN编码器-解码器进行统计机器翻译的短语表示
模型名称:RNNenc
作者是:Kyunghyun Cho,加拿大,蒙特利尔大学
编码器(基线)Encoder(bsaeline)
本文中给出的公式如下:
X
=
(
x
1
,
.
.
.
,
x
T
x
)
X=(x_1,...,x_{T_x})
X=(x1,...,xTx)
h
t
=
f
(
x
t
,
h
t
−
1
)
h_t=f(x_t,h_{t-1})
ht=f(xt,ht−1)
X
X
X表示一个输入句子的序列,句子中的每一个词都表示为一个独热向量
x
i
x_i
xi
h
t
h_t
ht表示t时间生成句子的隐藏状态
f
f
f表示非线性激活函数(如:sigmod,tanh等)
c
=
q
(
{
h
1
,
.
.
.
,
h
T
x
}
)
c=q(\{h_1,...,h_{T_x}\})
c=q({h1,...,hTx})
c
c
c表示从句子序列中生成的上下文向量
q
q
q表示非线性激活函数。
最初的隐藏层状态
h
0
h_0
h0为全0的向量
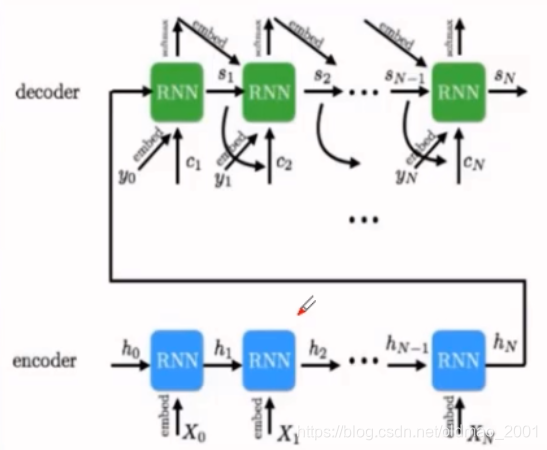
解码器(基线)Decoder(bsaeline)
从编码器中我们得到了源语言句子的压缩表示c
解码器也使用了RNN,本文中给出的公式如下:
Y
=
(
y
1
,
.
.
.
,
y
T
y
)
Y=(y_1,...,y_{T_y})
Y=(y1,...,yTy)
Y
Y
Y表示生成一个句子的序列。
s
t
=
f
(
c
,
y
t
−
1
,
s
t
−
1
)
s_t=f(c,y_{t-1},s_{t-1})
st=f(c,yt−1,st−1)
y
t
−
1
y_{t-1}
yt−1表示生成的前一个单词,
y
0
y_0
y0表示源语言的结束标记。
s
0
s_0
s0是全0的向量。
s
t
s_t
st表示RNN的隐藏层状态。
接下来根据
s
t
s_t
st来计算
y
t
y_t
yt的概率分布,并取得概率最大的
y
t
y_t
yt
p
(
y
t
∣
{
y
1
,
.
.
.
,
y
t
−
1
}
,
c
)
=
g
(
y
t
−
1
,
s
t
,
c
)
p(y_t|\{y_1,...,y_{t-1}\},c)=g(y_{t-1},s_t,c)
p(yt∣{y1,...,yt−1},c)=g(yt−1,st,c)
符号表示On notations
·h表示编码器的隐层状态
·s表示解码器的隐层状态
·j表示编码器的输入
·i表示解码器的输入
编码器-解码器框架(基线)Encoder-Decoder Framework(baseline)
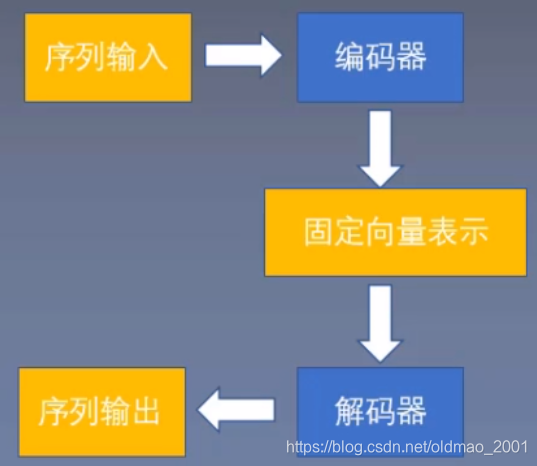
抽象后
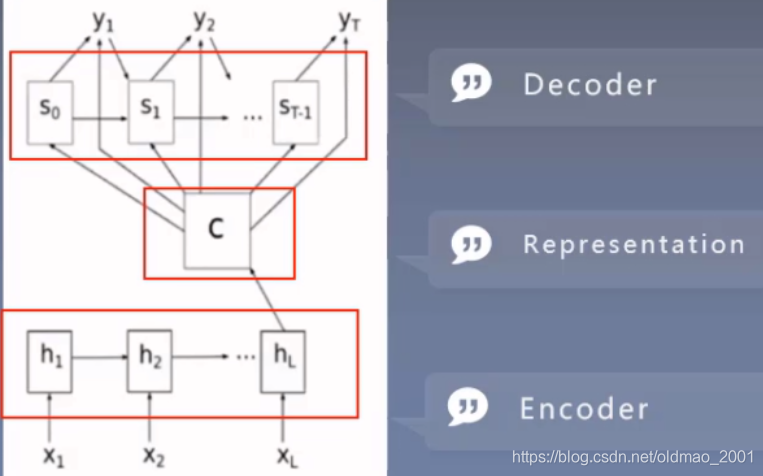
RNNenc模型效果
在机器翻译领域,使用Seq2Seq模型在英法翻译任务中表现接近技术最先进水平,比传统的词袋模型效果好。PS:这里的Seq2Seq就是编码解码器的同一时期同一类型的模型。
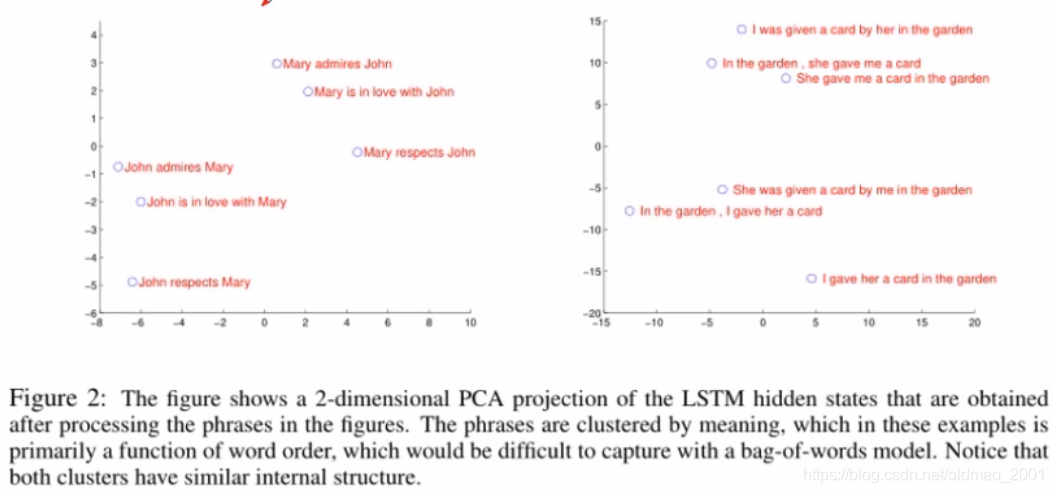
RNNenc模型存在问题
·必须记住整个句子序列的语义信息
·把无论长度多长的句子都编码成固定向量,这样限制了翻译过程中长句子的表示
·与人类翻译时的习惯不同,人们不会在生成目标语言翻译时关注源语言句子的每一个单词
论文的主要贡献
·在WMT14英语到法语数据集上取得了非常好的结果。
·提出一种新的神经机器翻译模型RNNsearch模型(RNNencdec是前人模型,RNNsearch是本文提出的Attention NMT模型。)
·编码器:采用双向循环神经网络
·隐藏状态同时对当前单词前面和后面的信息编码
·解码器:提出一种扩展(注意力)模型
·注意力机制:对输入的隐藏状态求权重
主实验简析
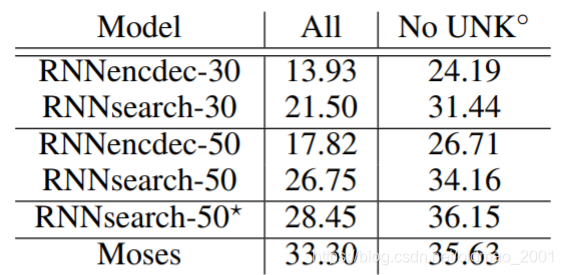
上图中:
·30和50代表句子长度最大分别为30和50。
·*表示训练时间更长,知道验证集结果不会变差才停止,其他大约训练5天。·ALL表示所有句子测试结果。
·No UNK表示翻译句子没有unk字符。
·Moses是一种统计机器翻译模型。
研究意义
·基于Attention的机器翻译模型是之后基于Seq2Seq的机器翻译模型的标准配置。
·极大地推动了注意力机制的发展,目前注意力机制用于自然语言处理的文本分类、对话、阅读理解等各个场合。
RNNSearch模型
| RNNenc | RNNsearch |
|---|---|
| ·将整个输入语句编码成一个固定长度的向量 | ·将输入的句子编码为变长向量序列 |
| ·使用单向循环神经网络(RNN) | ·在解码翻译时,自适应的选择这些向量的子集 |
| 使用双向循环神经网络(Bi-RNN),可以捕获某个词的前后语句 |
双向循环神经网络Bidirectional RNN


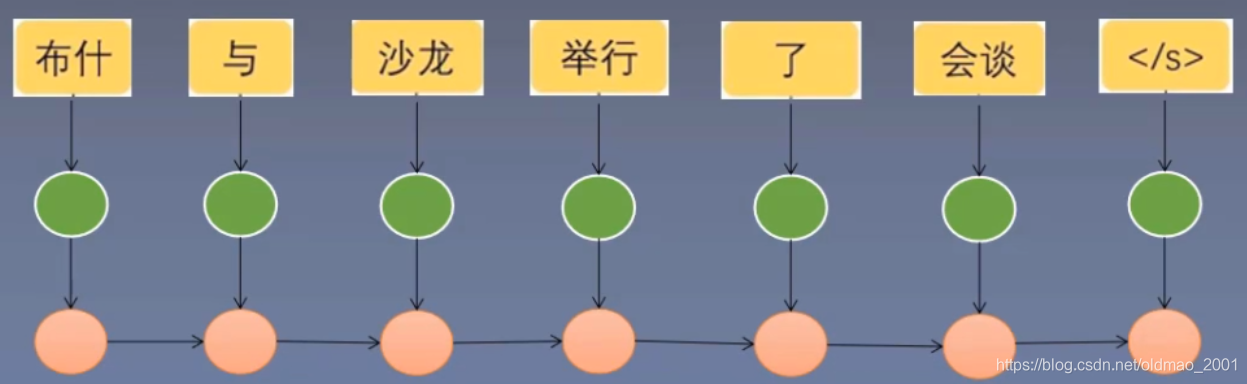
前面三步都和单向RNN是一样的。接下来是从右到左反向递归生成各个词的隐状态。
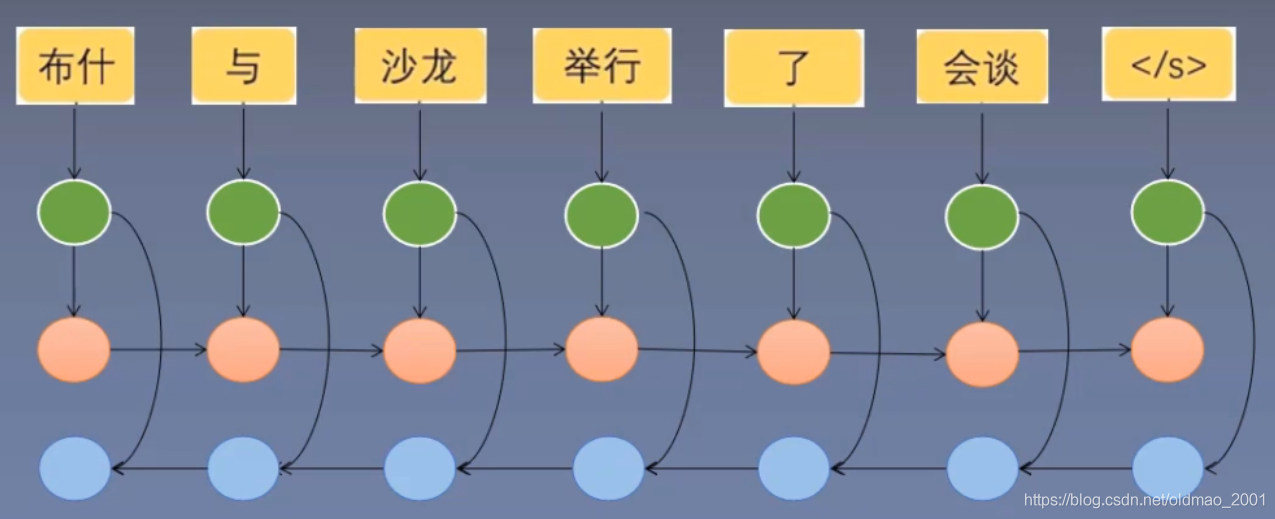
然后把正向和反向生成的隐状态合起来
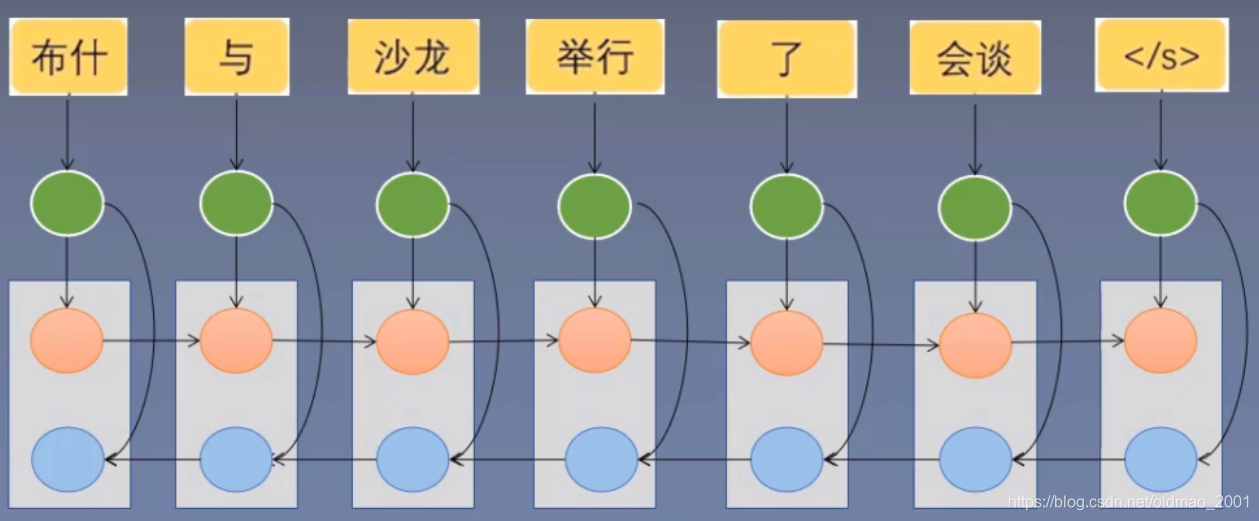
用公式进行抽象表达:
RNNsearch模型编码器:双向RNN
前向RNN:
输入:
X
=
(
x
1
,
x
2
,
…
,
x
T
)
X=(x_1,x_2, …,x_T)
X=(x1,x2,…,xT)
输出:
h
→
i
T
=
(
h
→
1
,
h
→
2
,
…
,
h
→
T
)
\overrightarrow{h}_i^T=(\overrightarrow{h}_1,\overrightarrow{h}_2,…,\overrightarrow{h}_T)
hiT=(h1,h2,…,hT)
后向RNN:
输入:
X
=
(
x
T
,
x
T
−
1
,
…
,
x
1
)
X=(x_T,x_{T-1},…,x_1)
X=(xT,xT−1,…,x1)
输出:
h
←
i
T
=
(
h
←
1
,
h
←
2
,
.
.
.
,
h
←
T
)
\overleftarrow{h}_i^{T}=(\overleftarrow{h}_1,\overleftarrow{h}_2,...,\overleftarrow{h}_T)
hiT=(h1,h2,...,hT)
连接:
h
i
=
(
h
→
i
T
;
h
←
i
T
)
T
h_i=(\overrightarrow{h}_i^T;\overleftarrow{h}_i^{T})^T
hi=(hiT;hiT)T
目标单词
y
i
y_i
yi的条件概率:
p
(
y
i
∣
y
1
,
.
.
.
,
y
i
−
1
,
X
)
=
g
(
y
i
−
1
,
s
i
,
c
i
)
p(y_i|y_1,...,y_{i-1},X)=g(y_{i-1},s_i,c_i)
p(yi∣y1,...,yi−1,X)=g(yi−1,si,ci)
s
i
s_i
si表示i时间的隐层状态:
s
i
=
f
(
s
i
−
1
,
y
i
−
1
,
c
i
)
s_i=f(s_{i-1},y_{i-1},c_i)
si=f(si−1,yi−1,ci)
与RNNenc模型不同点:
c
c
c→
c
i
c_i
ci
意思是,原来的RNNenc模型中源语言的句子是压缩成为一个固定长度向量c的,而在新模型中,每一个目标词
y
i
y_i
yi都有一个
c
i
c_i
ci与之对应。
将固定的
c
c
c替换成动态的
c
i
c_i
ci,
c
i
c_i
ci表示和
y
i
y_i
yi相关的源语言词信息
c
i
c_i
ci的计算下节说明
注意力思想
思想:集中关注的上下文

在生成红色词的时候,主要关注蓝色底纹的词。
通用注意力机制
注意力机制的思想:当前有很多信息,从这些信息中获取与当前状态有关的重要信息。
Query是一个向量,代表当前状态
Key是一组向量,与Query生成权重
Value是一组向量,一般都是等于Key
Query和Key使用concat或者内积操作得到的结果经过softmax得到不同的权重
α
\alpha
α,
α
\alpha
α再和Value相乘得到对应的向量表示 Attention Value。
利用权重进行对齐操作称为软对齐;相对于的,逐字逐词的对齐操作称为硬对齐。
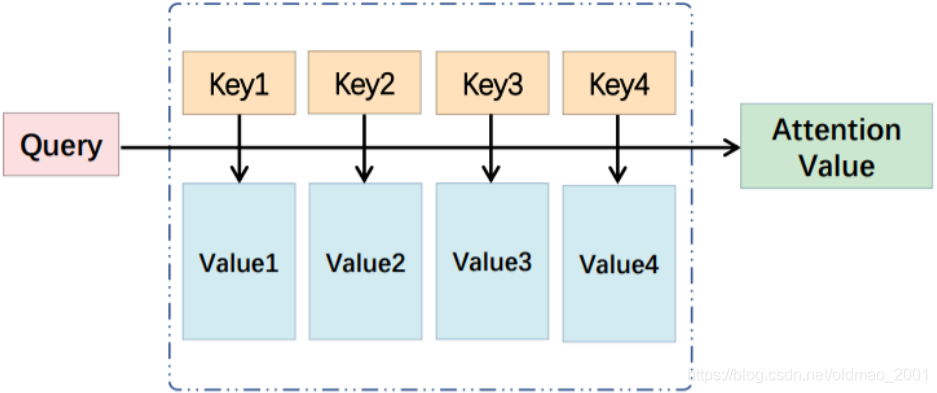
对应到论文里面
Query:
s
i
−
1
s_{i-1}
si−1
Key:
h
1
,
h
2
,
.
.
.
,
h
T
h_1,h_2,...,h_T
h1,h2,...,hT
Value:
h
1
,
h
2
,
.
.
.
,
h
T
h_1,h_2,...,h_T
h1,h2,...,hT
所以:Query*Key=
e
i
j
=
a
(
s
i
−
1
,
h
j
)
e_{ij}=a(s_{i-1},h_j)
eij=a(si−1,hj)
丢进softmax:
α
i
j
=
e
x
p
(
e
i
j
)
∑
k
=
1
T
x
e
x
p
(
e
i
k
)
\alpha_{ij}=\cfrac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}
αij=∑k=1Txexp(eik)exp(eij)
然后再和Value相乘:
c
i
=
∑
j
=
1
T
x
α
i
j
h
j
c_i=\sum_{j=1}^{T_x}\alpha_{ij}h_j
ci=∑j=1Txαijhj
论文注意力机制Attention mechanism
计算上下文向量
c
i
c_i
ci:
c
i
=
∑
j
=
1
T
x
α
i
j
h
j
c_i=\sum_{j=1}^{T_x}\alpha_{ij}h_j
ci=∑j=1Txαijhj
权重(注意力分数)
α
i
j
\alpha_{ij}
αij:
α
i
j
=
e
x
p
(
e
i
j
)
∑
k
=
1
T
x
e
x
p
(
e
i
k
)
\alpha_{ij}=\cfrac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}
αij=∑k=1Txexp(eik)exp(eij)
对齐模型:
e
i
j
=
a
(
s
i
−
1
,
h
j
)
e_{ij}=a(s_{i-1},h_j)
eij=a(si−1,hj)
a是对齐模型,用来衡量第j个源端词与目标端第i个词的匹配程度。

RNNsearch模型的解码器The decoder of RNNsearch
计算步骤:
1)计算注意力分数(对齐模型)
α
i
j
\alpha_{ij}
αij
2)计算带有注意力分数的上下文信息
c
i
c_i
ci
3)生成新的隐层状态输出
s
i
s_i
si
4)计算新的目标语言输出
y
i
y_i
yi
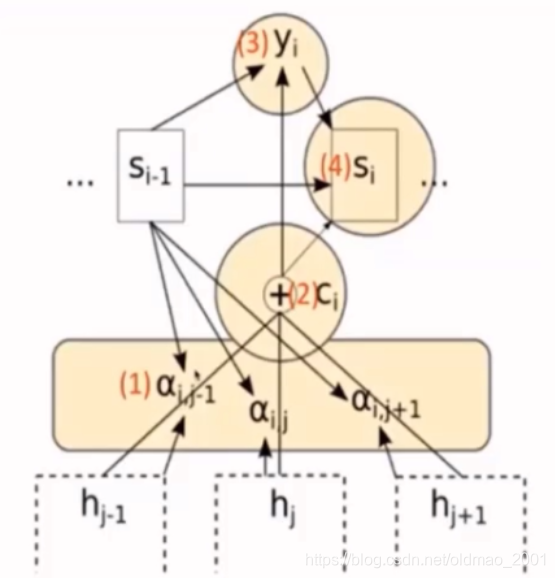
RNNsearch模型 RNNsearch model
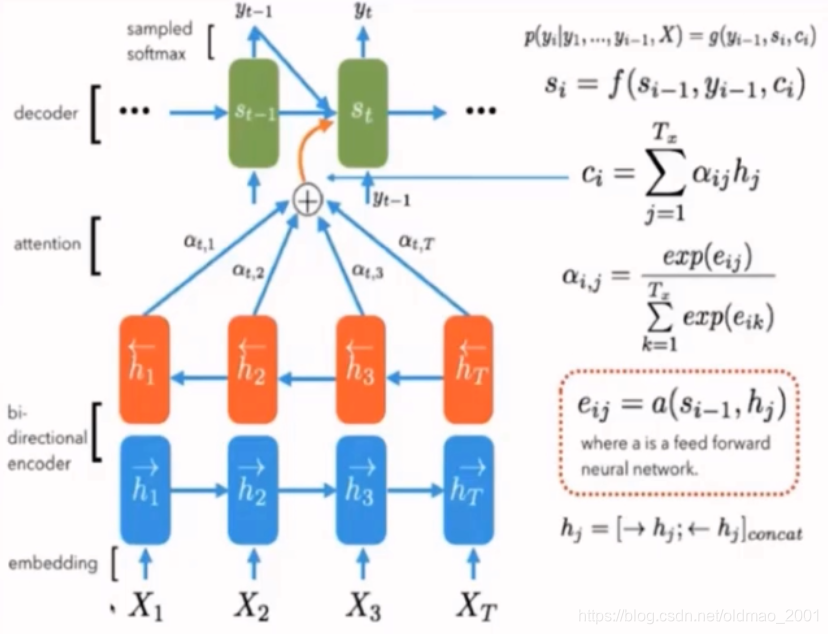
模型实例
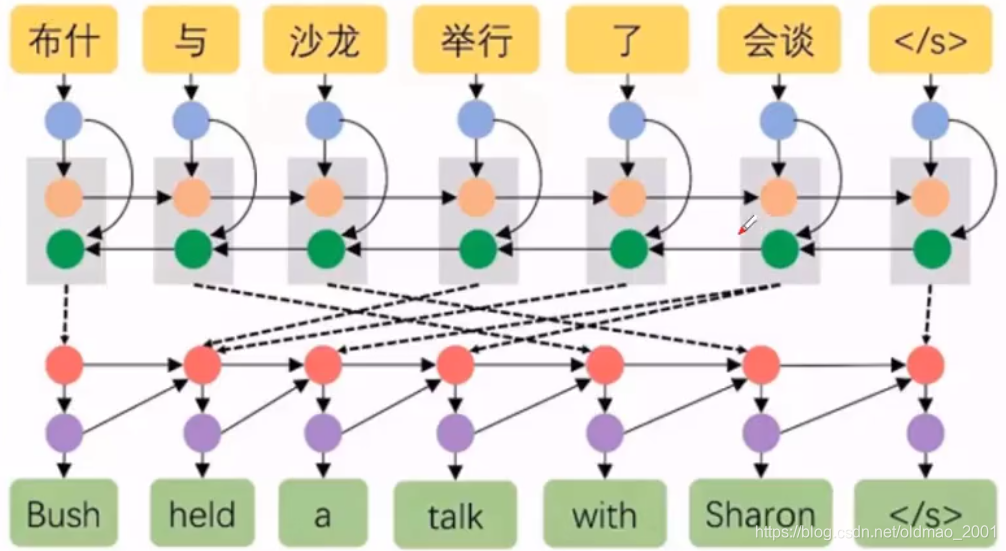
可以看到生成目标词的那里步骤和原来的不一样(原来是固定的输入)。每一个时间步都会动态(通过权重)选取上下文信息来生成目标词。
注意力机制其他应用
1.基于注意力机制的机器翻译模型是之后神经机器翻译模型的标配。
2.基于注意力机制的Seq2Seq模型用于对话生成、阅读理解、摘要生成等各个场合。
下面是“看图说话”的例子:为图片生成自动文本描述

实验和结果
实验设置Experiment settings
实验模型:RNN search 和RNNenc。
实验任务:从英语(源语言)到法语(目标语言)的翻译
数据集:WMT’14数据集
对比试验:分别取最大长度为30和最大长度为50的句子长度进行实验。词典维度为3000
实验评估标准——Bleu Experimental evaluation criteria——Bleu
Bleu:一种文本评估算法,用来评估机器翻译跟专业人工翻译之间的对应关系。
核心思想:机器翻译越接近专业人工翻译,质量就越好。
经过bleu算法得出的分数可以作为机器翻译质量的其中一个指标。
具体可以看上一篇baseline

RNNsearch模型效果The effect of RNNsearch
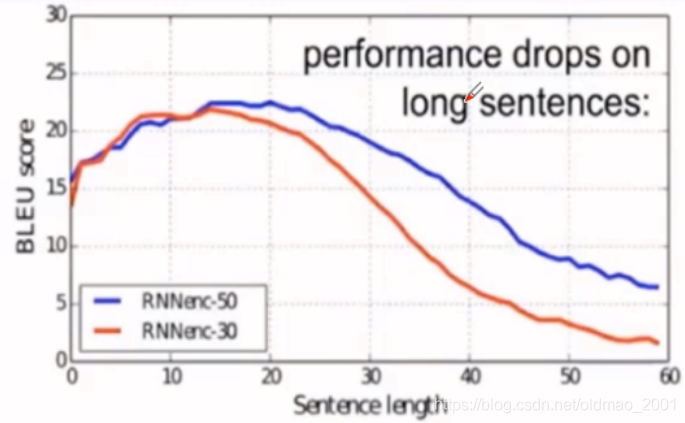
下图中横坐标是句子的长度,可以看到超过50之后本文模型依然效果没有明显下降。
Figure 2: The BLEU scores of the generated translations on the test set with respect to the lengths of the sentences. The results are on the full test set which includes sentences having unknown words to the models.
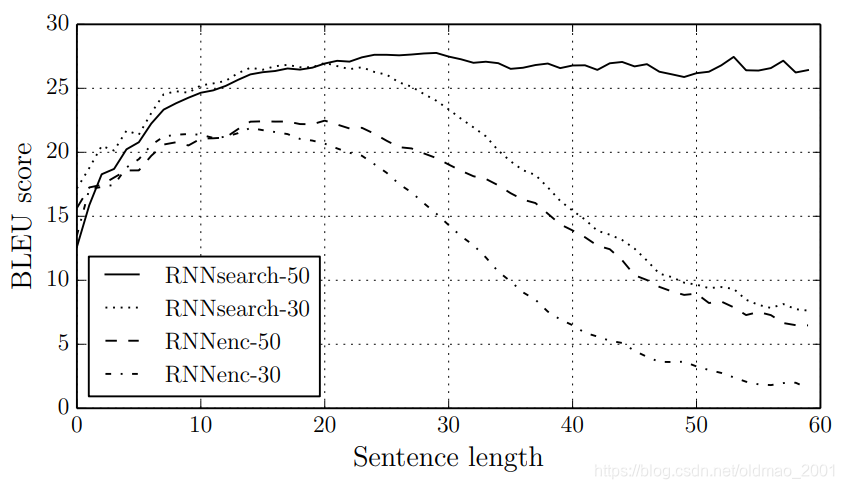
RNNsearch模型在长句子上表现优异
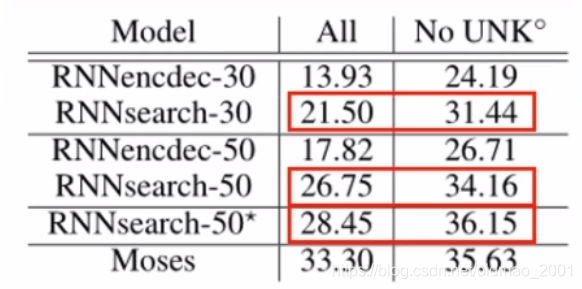
·在WMT14英语到法语数据集上取得了非常好的结果。
·RNNencdec是前人模型,RNNsearch是本文提出的Attention NMT模型。
·30和50代表句子长度最大分别为30和50。
·*表示训练时间更长,直到验证集结果不会变差才停止,其他大约训练5天。
·ALL表示所有句子测试结果。
·No UNK表示翻译句子没有unk字符。
·Moses是一种统计机器翻译模型。
实验结果分析Analysis of results
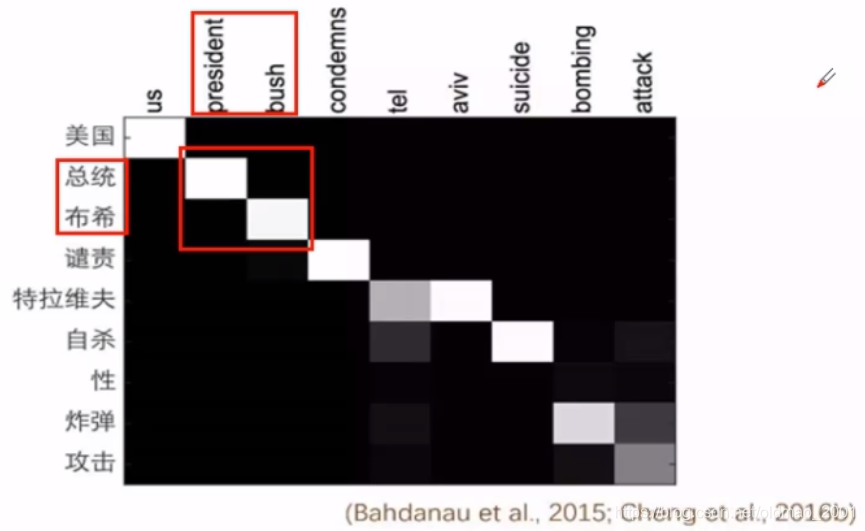
颜色越白相关性越强
讨论和总结
问题
注意力机制能够提升多少性能?Luong等人证明使用不同注意力机制计算会导致不同的结果。
双向循环神经网络能够提升多少性能?Luong等人证明使用单向lstm和使用算注意力分数具有同样的效果。
有其他注意力分数计算方法吗?Luong等人证明提出其他的注意力分数计算方法。
本文的改进论文:
Effective Approaches to Attention-based Neural Machine Translation(Luong,2015)

论文主要创新点:
A提出一种新的神经机器翻译方法
1.没有将输入编码到固定维度向量
2.采用注意力思想
B适用于其他结构化的输入输出问题
C一些设计的选择出于实际的考虑
后续工作做了很多权衡分析
主要参考文献:
Luong et al.2015.Effective approaches to attention-based neural machine translation
Sutskever et al.2014.Sequence to sequence learning with neural network
Cho K et al.2014.On the properties of neural machine translation: Encoder-decoder approaches
Pascanu R et al.2013.How to construct deep recurrent neural networks
作业
1.分别画出基线模型和改进模型的机器翻译数据流程图。
2.展示你的学习笔记(图片)。
3.列举三个学习完本课程的问题。
第三课时 代码复现TF版
学习方法
| 任务定义 | 数据来源 | 运行环境 | 运行结果 | 如何实现 |
|---|---|---|---|---|
| 搞清楚程序的目的是什么 | 源码获取渠道 | 运行环境 | 能否运行成功 | 代码整体构架 |
| 为了实现什么任务 | 数据集类型 | 实验工具 | 运行代码后出现什么结果 | 每部分实现细节 |
| 数据集来源 | 第三方库 | 结果的形式是什么 |
阅读方法Reading method
从上到下:
由点及面,先阅读各函数部分,弄懂各模块完成功能再阅读主程序部分。适用结构简单的程序。
从下到上:
先阅读主程序内容,再根据主程序中的调用函数阅读被调用部分,知道主程序执行完毕。适用结构复杂的程序。
准备工作
代码来源
论文源码:
·文件结构复杂,对初学者不友好
·theano框架实现,开发者不再维护
·源码版本过低,调试有难度
复现代码:
·代码结构简单,只含有一个训练文件train.py和一个测试文件test.py
·便于初学者理解代码实现思想
·采用TensorFlow框架,使用人数多,受众广,便于调试
运行环境:
Tensorflow版本:14以上
Windows/Linux环境运行均可
不要求GPU,但使用GPU 会加快代码运行速度
Pytho版本:2.7
数据集
论文源码:WMT’14英语-法语机器翻译数据集,数据集体量较大,训练时间较长
复现代码:IWLST TED英文-中文演讲数据集,数据集体量较小,训练时间较短
数据预处理
parallel corpora平行语料库:由原文文本及其平行对应的译语文本构成的双语语料库,其双语对应程度可有词级、句级和段级几种。简单的说就是一句英文一句对应中文
平行语料库不能直接用于本文算法,需要处理为神经机器翻译可以处理的数据。具体预处理过程为:
1、切词:将生数据中英文单词和中文字符用空格分割(包括标点符号)
2、统计:统计语料中出现的单词数目
3、分配ID:为每一个单词分配一个ID
4、生成词汇表:将单词和其对应的ID制作成对应的词汇表,保存在vocab文件中
5、编号表示:将程序所需数据集文本转化为用单词编号的形式表示
本次提供了raw data也提供了处理好的data。
语料填充
由于预处理后的数据比较大,不可能一次处理所有的数据,因此要分batch,由于文本中句子的长度不一样,不能像图形一样的处理,常用的做法是用padding的方法把同一batch的句子的长度补齐
填充:用于填充长度而填充的位置,下面是一个数据集有四句话,分两个batch进行填充的例子。每个batch的最大句子长度可以不一样。
| A1 | A2 | A3 | A4 |
|---|---|---|---|
| B1 | B2 | 0 | 0 |
| C1 | C2 | C3 | C4 | C5 | C6 |
|---|---|---|---|---|---|
| D1 | 0 | 0 | 0 | 0 | 0 |
具体的填充调用函数为:tf. data. Dataset.padded_batch(batch_size, padded_shapes)
具体填充代码:
偷懒贴点老师的代码。
# 使用Dataset从一个文件中读取一个语言的数据。
# 数据的格式为每行一句话,单词已经转化为单词编号。
def MakeDataset(file_path):
dataset = tf.data.TextLineDataset(file_path)
# 根据空格将单词编号切分开并放入一个一维向量。
dataset = dataset.map(lambda string: tf.string_split([string]).values)
# 将字符串形式的单词编号转化为整数。
dataset = dataset.map(
lambda string: tf.string_to_number(string, tf.int32))
# 统计每个句子的单词数量,并与句子内容一起放入Dataset中。
dataset = dataset.map(lambda x: (x, tf.size(x)))
return dataset
分batch处理数据
# 从源语言文件src_path和目标语言文件trg_path中分别读取数据,并进行填充和
# batching操作。
def MakeSrcTrgDataset(src_path, trg_path, batch_size):
# 首先分别读取源语言数据和目标语言数据。
src_data = MakeDataset(src_path)
trg_data = MakeDataset(trg_path)
# 通过zip操作将两个Dataset合并为一个Dataset。现在每个Dataset中每一项数据ds
# 由4个张量组成:
# ds[0][0]是源句子
# ds[0][1]是源句子长度
# ds[1][0]是目标句子
# ds[1][1]是目标句子长度
dataset = tf.data.Dataset.zip((src_data, trg_data))
# 删除内容为空(只包含<EOS>)的句子和长度过长的句子。
def FilterLength(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
src_len_ok = tf.logical_and(
tf.greater(src_len, 1), tf.less_equal(src_len, MAX_LEN))
trg_len_ok = tf.logical_and(
tf.greater(trg_len, 1), tf.less_equal(trg_len, MAX_LEN))
return tf.logical_and(src_len_ok, trg_len_ok)
dataset = dataset.filter(FilterLength)
# 从图9-5可知,解码器需要两种格式的目标句子:
# 1.解码器的输入(trg_input),形式如同"<sos> X Y Z"
# 2.解码器的目标输出(trg_label),形式如同"X Y Z <eos>"
# 上面从文件中读到的目标句子是"X Y Z <eos>"的形式,我们需要从中生成"<sos> X Y Z"
# 形式并加入到Dataset中。
def MakeTrgInput(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
trg_input = tf.concat([[SOS_ID], trg_label[:-1]], axis=0)
return ((src_input, src_len), (trg_input, trg_label, trg_len))
dataset = dataset.map(MakeTrgInput)
# 随机打乱训练数据。
dataset = dataset.shuffle(10000)
# 规定填充后输出的数据维度。
padded_shapes = (
(tf.TensorShape([None]), # 源句子是长度未知的向量
tf.TensorShape([])), # 源句子长度是单个数字
(tf.TensorShape([None]), # 目标句子(解码器输入)是长度未知的向量
tf.TensorShape([None]), # 目标句子(解码器目标输出)是长度未知的向量
tf.TensorShape([]))) # 目标句子长度是单个数字
# 调用padded_batch方法进行batching操作。
batched_dataset = dataset.padded_batch(batch_size, padded_shapes)
return batched_dataset
训练模型
训练之前先看一下参数的定义:
SRC_TRAIN_DATA = "./train.en" # 源语言输入文件。
TRG_TRAIN_DATA = "./train.zh" # 目标语言输入文件。
CHECKPOINT_PATH = "./attention_ckpt" # checkpoint保存路径。
HIDDEN_SIZE = 1024 # LSTM的隐藏层规模。
DECODER_LAYERS = 2 # 解码器中LSTM结构的层数。这个例子中编码器固定使用单层的双向LSTM。
SRC_VOCAB_SIZE = 10000 # 源语言词汇表大小。
TRG_VOCAB_SIZE = 4000 # 目标语言词汇表大小。
BATCH_SIZE = 100 # 训练数据batch的大小。
NUM_EPOCH = 5 # 使用训练数据的轮数。
KEEP_PROB = 0.8 # 节点不被dropout的概率。
MAX_GRAD_NORM = 5 # 用于控制梯度膨胀的梯度大小上限。
SHARE_EMB_AND_SOFTMAX = True # 在Softmax层和词向量层之间共享参数。
MAX_LEN = 50 # 限定句子的最大单词数量。
SOS_ID = 1 # 目标语言词汇表中<sos>的ID。<sos>代表解码器输入的开始字符
主程序
训练步骤:
1.初始化
2.定义模型
3.定义输入数据
4.定义前向图
5.训练模型
def main():
# 1.定义初始化函数。均匀分布
initializer = tf.random_uniform_initializer(-0.05, 0.05)
# 2.定义训练用的循环神经网络模型。
with tf.variable_scope("nmt_model", reuse=None,
initializer=initializer):
train_model = NMTModel()
# 3.定义输入数据。
data = MakeSrcTrgDataset(SRC_TRAIN_DATA, TRG_TRAIN_DATA, BATCH_SIZE)
iterator = data.make_initializable_iterator()#初始化迭代器
(src, src_size), (trg_input, trg_label, trg_size) = iterator.get_next()
# 4.定义前向计算图。输入数据以张量形式提供给forward函数。
cost_op, train_op = train_model.forward(src, src_size, trg_input, trg_label, trg_size)
# 5.训练模型。
saver = tf.train.Saver()
step = 0
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(NUM_EPOCH):
print("In iteration: %d" % (i + 1))
sess.run(iterator.initializer)
step = run_epoch(sess, cost_op, train_op, saver, step)
神经机器翻译模型
初始化函数
在模型的初始化函数中定义模型要用到的变量
class NMTModel(object):
# 在模型的初始化函数中定义模型要用到的变量。
def __init__(self):
# 定义编码器和解码器所使用的LSTM结构。
self.enc_cell_fw = tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE)#前向LSTM
self.enc_cell_bw = tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE)#后向LSTM
self.dec_cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) #定义解码器
......
# 为源语言和目标语言分别定义词向量。
self.src_embedding = tf.get_variable("src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable("trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
# 定义softmax层的变量
if SHARE_EMB_AND_SOFTMAX:
self.softmax_weight = tf.transpose(self.trg_embedding)
else:
self.softmax_weight = tf.get_variable("weight", [HIDDEN_SIZE, TRG_VOCAB_SIZE])#定义偏置
self.softmax_bias = tf.get_variable("softmax_bias", [TRG_VOCAB_SIZE])#定义权重
# 在forward函数中定义模型的前向计算图。
# src_input, src_size, trg_input, trg_label, trg_size分别是上面
# MakeSrcTrgDataset函数产生的五种张量。
def forward(self, src_input, src_size, trg_input, trg_label, trg_size):
batch_size = tf.shape(src_input)[0]
# 将输入和输出单词编号转为词向量。
src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input)
trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input)
# 在词向量上进行dropout。
src_emb = tf.nn.dropout(src_emb, KEEP_PROB)
trg_emb = tf.nn.dropout(trg_emb, KEEP_PROB)
构造编码器,使用双向循环神经网络
# 使用dynamic_rnn构造编码器。
# 编码器读取源句子每个位置的词向量,输出最后一步的隐藏状态enc_state。
# 因为编码器是一个双层LSTM,因此enc_state是一个包含两个LSTMStateTuple类
# 张量的tuple,每个LSTMStateTuple对应编码器中的一层。
# 张量的维度是 [batch_size, HIDDEN_SIZE]。
# enc_outputs是顶层LSTM在每一步的输出,它的维度是[batch_size,
# max_time, HIDDEN_SIZE]。Seq2Seq模型中不需要用到enc_outputs,而
# 后面介绍的attention模型会用到它。
# 下面的代码取代了Seq2Seq样例代码中forward函数里的相应部分。
with tf.variable_scope("encoder"):
# 构造编码器时,使用bidirectional_dynamic_rnn构造双向循环网络。
# 双向循环网络的顶层输出enc_outputs是一个包含两个张量的tuple,每个张量的
# 维度都是[batch_size, max_time, HIDDEN_SIZE],代表两个LSTM在每一步的输出。
enc_outputs, enc_state = tf.nn.bidirectional_dynamic_rnn(
self.enc_cell_fw, self.enc_cell_bw, src_emb, src_size,
dtype=tf.float32)
# 将两个LSTM的输出拼接为一个张量。
enc_outputs = tf.concat([enc_outputs[0], enc_outputs[1]], -1)
前向传播——构造解码器
选择注意力权重的计算模型:BahdanauAttention是使用一个隐藏层的前馈神经网络
·memory_sequence_length是一个维度为[batch_size]的张量,代表batch中每个句子的长度,Attention需要根据这个信息把填充位置的注意力权重设置为0
tf. contrib. seq2seq BahdanauAttention(HIDDEN_SIZE, enc_outputs, memory_sequence_length=src_size)
具体代码:
with tf.variable_scope("decoder"):
# 选择注意力权重的计算模型。BahdanauAttention是使用一个隐藏层的前馈神经网络。
# memory_sequence_length是一个维度为[batch_size]的张量,代表batch
# 中每个句子的长度,Attention需要根据这个信息把填充位置的注意力权重设置为0。
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(HIDDEN_SIZE, enc_outputs,memory_sequence_length=src_size)
# 将解码器的循环神经网络self.dec_cell和注意力一起封装成更高层的循环神经网络。
attention_cell = tf.contrib.seq2seq.AttentionWrapper(self.dec_cell, attention_mechanism,attention_layer_size=HIDDEN_SIZE)
# 使用attention_cell和dynamic_rnn构造编码器。
# 这里没有指定init_state,也就是没有使用编码器的输出来初始化输入,而完全依赖
# 注意力作为信息来源。
dec_outputs, _ = tf.nn.dynamic_rnn(attention_cell, trg_emb, trg_size, dtype=tf.float32)
计算损失函数
然后我们就可以像普通神经网络的一个隐藏层一样,添加偏置项(就是神经网络中的’b’)和卷积输出相加并在最后添加一个激活层。
# 计算解码器每一步的log perplexity。这一步与语言模型代码相同。
output = tf.reshape(dec_outputs, [-1, HIDDEN_SIZE])
logits = tf.matmul(output, self.softmax_weight) + self.softmax_bias
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.reshape(trg_label, [-1]), logits=logits)
计算平均损失
计算平均损失函数,最后输出cost_per_token
# 在计算平均损失时,需要将填充位置的权重设置为0,以避免无效位置的预测干扰
# 模型的训练。
label_weights = tf.sequence_mask(
trg_size, maxlen=tf.shape(trg_label)[1], dtype=tf.float32)
label_weights = tf.reshape(label_weights, [-1])
cost = tf.reduce_sum(loss * label_weights)
cost_per_token = cost / tf.reduce_sum(label_weights)
反向传播
只在训练时定义反向传播操作
# 定义反向传播操作。反向操作的实现与语言模型代码相同。
trainable_variables = tf.trainable_variables()
# 控制梯度大小,定义优化方法和训练步骤。
grads = tf.gradients(cost / tf.to_float(batch_size),trainable_variables)
grads, _ = tf.clip_by_global_norm(grads, MAX_GRAD_NORM)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0)
train_op = optimizer.apply_gradients(
zip(grads, trainable_variables))
return cost_per_token, train_op
训练结果
略
每10步一次输出。
测试模型
虽然输入只有一个句子,但因为dynamic_rnn要求输入是batch的形式,因此这里将输入句子整理为大小为1的batch。
测试主函数流程:
1.定义模型
2.定义测试句子
3.转化源语言单词id
4.建立计算图
5.转化目标语言单词id
6.转换文字
7.输出
代码复现PyTorch版
数据集下载
iwslt14: https://wit3.fbk.eu/archive/2014-01/texts/de/en/de-en.tgz
内容回顾
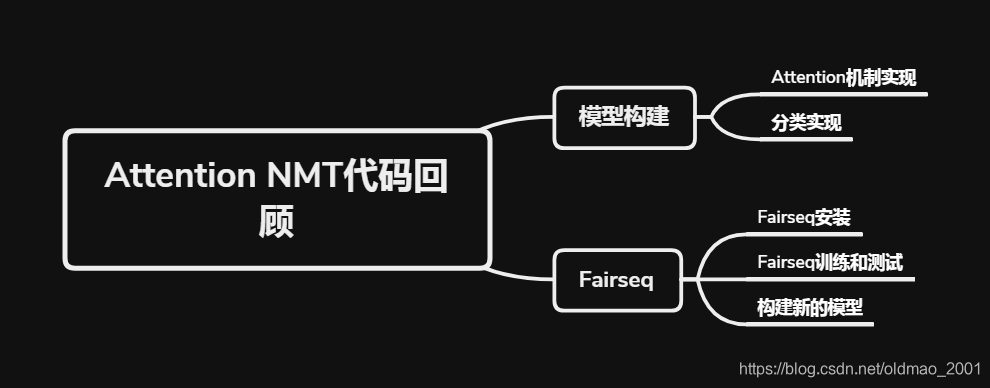
数据处理
和baseline 07一样,直接贴代码过来:
# coding:utf-8
from torch.utils import data
import os
import nltk
import numpy as np
import pickle
from collections import Counter
class iwslt_Data(data.DataLoader):
def __init__(self, source_data_name="train.tags.de-en.de", target_data_name="train.tags.de-en.en",
source_vocab_size=30000, target_vocab_size=30000):
self.path = os.path.abspath(".")
if "data" not in self.path:
self.path += "/data"
self.source_data_name = source_data_name
self.target_data_name = target_data_name
self.source_vocab_size = source_vocab_size
self.target_vocab_size = target_vocab_size
self.source_data, self.target_data, self.target_data_input = self.load_data()
def load_data(self):
raw_source_data = open(self.path + "/iwslt14/" + self.source_data_name, encoding="utf-8").readlines()
raw_target_data = open(self.path + "/iwslt14/" + self.target_data_name, encoding="utf-8").readlines()
raw_source_data = [x[0:-1] for x in raw_source_data]
raw_target_data = [x[0:-1] for x in raw_target_data]
print(len(raw_target_data))
print(len(raw_source_data))
source_data = []
target_data = []
for i in range(len(raw_source_data)):
if raw_target_data[i] != "" and raw_source_data[i] != "" and raw_source_data[i][0] != "<" and \
raw_target_data[i][0] != "<":
source_sentence = nltk.word_tokenize(raw_source_data[i], language="german")
target_sentence = nltk.word_tokenize(raw_target_data[i], language="english")
if len(source_sentence) <= 100 and len(target_sentence) <= 100:
source_data.append(source_sentence)
target_data.append(target_sentence)
if not os.path.exists(self.path + "/iwslt14/source_word2id"):
source_word2id = self.get_word2id(source_data, self.source_vocab_size)
target_word2id = self.get_word2id(target_data, self.target_vocab_size)
self.source_word2id = source_word2id
self.target_word2id = target_word2id
pickle.dump(source_word2id, open(self.path + "/iwslt14/source_word2id", "wb"))
pickle.dump(target_word2id, open(self.path + "/iwslt14/target_word2id", "wb"))
else:
self.source_word2id = pickle.load(open(self.path + "/iwslt14/source_word2id", "rb"))
self.target_word2id = pickle.load(open(self.path + "/iwslt14/target_word2id", "rb"))
source_data = self.get_id_datas(source_data, self.source_word2id)
target_data = self.get_id_datas(target_data, self.target_word2id, is_source=False)
target_data_input = [[2] + sentence[0:-1] for sentence in target_data]
source_data = np.array(source_data)
target_data = np.array(target_data)
target_data_input = np.array(target_data_input)
return source_data, target_data, target_data_input
def get_word2id(self, data, word_num):
words = []
for sentence in data:
for word in sentence:
words.append(word)
word_freq = dict(Counter(words).most_common(word_num - 4))
word2id = {"<pad>": 0, "<unk>": 1, "<start>": 2, "<end>": 3}
for word in word_freq:
word2id[word] = len(word2id)
return word2id
def get_id_datas(self, datas, word2id, is_source=True):
for i, sentence in enumerate(datas):
for j, word in enumerate(sentence):
datas[i][j] = word2id.get(word, 1)
if is_source:
datas[i] = datas[i][0:100] + [0] * (100 - len(datas[i]))
datas[i].reverse()
else:
datas[i] = datas[i][0:99] + [3] + [0] * (99 - len(datas[i]))
return datas
def __getitem__(self, idx):
return self.source_data[idx], self.target_data_input[idx], self.target_data[idx]
def __len__(self):
return len(self.source_data)
if __name__ == "__main__":
iwslt_data = iwslt_Data()
print(iwslt_data.source_data.shape)
print(iwslt_data.target_data_input.shape)
print(iwslt_data.target_data.shape)
print(iwslt_data.source_data[0])
print(iwslt_data.target_data_input[0])
print(iwslt_data.target_data[0])
Attention Model
#可以按下面的构架来写,这里由于是根据上个baseline中的model代码修改而来,所以结构没有这么清晰
class Encoder():
pass
class Attention():
pass
class Decoder():
pass
class seq2seq():
pass
实际代码如下,里面将每层的输入的shape都注释出来了:
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import numpy as np
from torch.nn import functional as F
from torch.autograd import Variable
class Attention_NMT(nn.Module):
def __init__(self, source_vocab_size, target_vocab_size, embedding_size,
source_length, target_length, lstm_size, batch_size=32):
super(Attention_NMT, self).__init__()
# 源语言的向量表示:source_vocab_size*embedding_size
self.source_embedding = nn.Embedding(source_vocab_size, embedding_size)
# 目标语言的向量表示:target_vocab_size*embedding_size
self.target_embedding = nn.Embedding(target_vocab_size, embedding_size)
# 这里只用了一层LSTM,num_layers=1
# if batch_first==False:input shape=[length,batch size,embedding size]
self.encoder = nn.LSTM(input_size=embedding_size, hidden_size=lstm_size, num_layers=1,
bidirectional=True, batch_first=True)
# decoder的输入是y_{i-1}和ci concat在一起的结果,y_{i-1}的维度是embedding_size
# ci的维度和ht的维度一样是lstm_size,由于是双向LSTM,所以是2个ht:2 * lstm_size
self.decoder = nn.LSTM(input_size=embedding_size + 2 * lstm_size, hidden_size=lstm_size, num_layers=1,
batch_first=True)
# 注意力机制:输入是根据论文中公式6的eij计算的,它由s_{i-1}和hj作为输入
# s_{i-1}是Decoder的LSTM size,hj是双向LSTM,所以是2 * lstm_size
# 一共就是3 * lstm_size,后面的那个3 * lstm_size是自己定的
self.attention_fc_1 = nn.Linear(3 * lstm_size, 3 * lstm_size) # 注意力机制全连接层1
# 这里的第一个参数和上一层的输出(第二个)要一样,所以是3 * lstm_size
# 最后得到一个标量,一个值,即权重,所以输出维度大小是1
self.attention_fc_2 = nn.Linear(3 * lstm_size, 1) # 注意力机制全连接层2
# 这里是根据论文中的公式4来计算输入,里面有:
# y_{i-1}大小是embedding_size
# si大小是LSTM size
# ci的维度和ht的维度一样是lstm_size,由于是双向LSTM,所以是2个ht:2 * lstm_size
# 所以输入维度大小为:embedding_size + 2 * lstm_size + lstm_size
# 输出维度自己定的
self.class_fc_1 = nn.Linear(embedding_size + 2 * lstm_size + lstm_size, 2 * lstm_size) # 分类全连接层1
# 这里的输入维度等于上一层的输出
# 分类器最后的输出是每个词的概率,所以输出的维度大小:target_vocab_size
self.class_fc_2 = nn.Linear(2 * lstm_size, target_vocab_size) # 分类全连接层2
def attention_forward(self, input_embedding, dec_prev_hidden, enc_output):
# squeeze()是把维度大小为1的的维度去掉
# 1*bs*lstm_size变成了bs*lstm_size
# unsqueeze(1)是在第1个维度加一个维度
# bs*lstm_size变成了bs*1*lstm_size
# repeat(1, 100, 1)是在第1个维度重复100次
# bs*length*lstm_size
# 整个操作是为了和ht做concat操作
prev_dec_h = dec_prev_hidden[0].squeeze().unsqueeze(1).repeat(1, 100, 1)
# 把上面的结果和enc_output的第三个维度进行concat操作
# bs*length*(3*lstm_size)
# 这个结果就是论文公式6中计算eij的a的输入
atten_input = torch.cat([enc_output, prev_dec_h], dim=-1)
# 每个单词都得到一个权重:batch size*length*1
attention_weights = self.attention_fc_2(F.relu(self.attention_fc_1(atten_input)))
# alpha:batch_size*length*1
attention_weights = F.softmax(attention_weights, dim=1)
# 公式5加权求和,这里用了广播机制
# 这里是在第一个维度进行求和,这个维度就没有了
# 所以sum后的维度是batch_size*(2*lstm_size)
# 然后用unsqueeze(1)在第一个维度加一个维度,使其能作为Decoder的输入
# 大小变为:batch_size*1*(2*lstm_size)
atten_output = torch.sum(attention_weights * enc_output, dim=1).unsqueeze(1)
# 在第三个维度上进行concat,得到Decoder的输入
# 其大小为:bs*1*(embedding_size+2*lstm_size)
dec_lstm_input = torch.cat([input_embedding, atten_output], dim=2)
# 这里相当于把论文中的每一时间步的s和c保存下来
# dec output:bs*1*lstm_size
# dec_hidden:lbs*1*lstm_size,bs*1*lstm_size]
dec_output, dec_hidden = self.decoder(dec_lstm_input, dec_prev_hidden)
return atten_output, dec_output, dec_hidden
def forward(self, source_data, target_data, mode="train", is_gpu=True):
# 维度为:batch_size*length*embedding_size
source_data_embedding = self.source_embedding(source_data)
# enc output.shape:batch_size*length*(2*1stm size)返回所有hidden,concat
# enc_hidden:[Th1,h2],[cl,c2]]返回每个方向最后一个时间步h和。
enc_output, enc_hidden = self.encoder(source_data_embedding)
# 把中间的attention和Decoder结果保存下来
self.atten_outputs = Variable(torch.zeros(target_data.shape[0],
target_data.shape[1],
enc_output.shape[
2])) # batch_ size*length*(2*Lstm size),encoder是双向LSTM
self.dec_outputs = Variable(torch.zeros(target_data.shape[0],
target_data.shape[1],
enc_hidden[0].shape[2])) # batch_ size*length**Lstm size,Decoder是单向LSTM
if is_gpu:
self.atten_outputs = self.atten_outputs.cuda()
self.dec_outputs = self.dec_outputs.cuda()
# enc_output: bs*length*(2*lstm_size)
# 训练模式下,使用真实的标签
if mode == "train":
# batch_ size*length*embedding size
target_data_embedding = self.target_embedding(target_data)
# dec_prev_hidden[0]: 1*bs*lstm_size, dec_prev_hidden[1]: 1*bs*lstm_size
# 这里的unsqueeze(0)就是加了第0维度,就是上面那个1
dec_prev_hidden = [enc_hidden[0][0].unsqueeze(0), enc_hidden[1][0].unsqueeze(0)]
for i in range(100):
# 在第1个维度加1,变成batch_ size*1*embedding size
input_embedding = target_data_embedding[:, i, :].unsqueeze(1)
atten_output, dec_output, dec_hidden = self.attention_forward(input_embedding,
dec_prev_hidden,
enc_output)
# batch_size * (2 * lstm_size)
self.atten_outputs[:, i] = atten_output.squeeze()
# batch_size * lstm_size
self.dec_outputs[:, i] = dec_output.squeeze()
dec_prev_hidden = dec_hidden
# 将下面的三个东东的第2个维度concat到一起
# 大小为:batch_size*length*(embedding_size + 2 * lstm_size + lstm_size)
class_input = torch.cat([target_data_embedding, self.atten_outputs, self.dec_outputs], dim=2)
# 进入ReLU增加非线性
outs = self.class_fc_2(F.relu(self.class_fc_1(class_input)))
else: # 测试的过程
input_embedding = self.target_embedding(target_data)
dec_prev_hidden = [enc_hidden[0][0].unsqueeze(0), enc_hidden[1][0].unsqueeze(0)]
outs = []
for i in range(100):
atten_output, dec_output, dec_hidden = self.attention_forward(input_embedding,
dec_prev_hidden,
enc_output)
class_input = torch.cat([input_embedding, atten_output, dec_output], dim=2)
# 和训练不一样,这里的每一个时间步是用预测来得到一个下一个时间步的输入,
# 训练则用label直接作为输入。
pred = self.class_fc_2(F.relu(self.class_fc_1(class_input)))
pred = torch.argmax(pred, dim=-1)
outs.append(pred.squeeze().cpu().numpy())
dec_prev_hidden = dec_hidden
input_embedding = self.target_embedding(pred)
return outs
if __name__ == "__main__":
attention_nmt = Attention_NMT(source_vocab_size=30000, target_vocab_size=30000, embedding_size=256,
source_length=100, target_length=100, lstm_size=256, batch_size=64)
source_data = torch.Tensor(np.zeros([64, 100])).long()
target_data = torch.Tensor(np.zeros([64, 100])).long()
preds = attention_nmt(source_data, target_data, is_gpu=False)
print(preds.shape)
target_data = torch.Tensor(np.zeros([64, 1])).long()
preds = attention_nmt(source_data, target_data, mode="test", is_gpu=False)
print(np.array(preds).shape)
fairseq框架
https://github.com/pytorch/fairseq
Requirements and Installation
· PyTorch version>=1.4.0
· Python version>=3.6
· For training new models, you’ ll also need an NVIDIA GPU and NCCL
· To install fairseq and develop localy:
git clone https://github. com/pytorch/fairseq
cd fairseq
pip install--editable./
帮助文档:https://fairseq.readthedocs.io/en/latest/















 4089
4089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











