







Hadoop浅谈
在了解HDFS之前必须介绍一下hadoop以及hadoop和HDFS之前的关系:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。那么它们之间的关系可以通过下面几点了解:
1、Hadoop是google的集群系统的开源实现:
Google集群系统:GFS(Google File System)、MapReduce、BigTable。
Hadoop主要由HDFS(Hadoop Distributed File System Hadoop分布式文件系统)、MapReduce和HBase组成。
2、Hadoop的初衷是为解决Nutch的海量数据爬取和存储的需要。
3、Hadoop于2005年秋天作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
4)名称起源:Doug Cutting儿子的黄色大象玩具的名字。
在这个Hadoop中还有很多子项目:
1)Core:一套分布式文件系统以及支持Map-Reduce的计算框架
2)Avro:定义了一种用于支持大数据应用的数据格式,并为这种格式提供了不同的编程语言支持。
3)HDFS:Hadoop分布式文件系统
4)Map/Reduce:是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
5)ZooKeeper:是高可用的和高可靠的分布式协同系统。
6)Pig:建立于Hadooop Core之上为并行计算环境提供了一套数据工作流语言和执行框架。
7)Hive:是为提供简单的数据操作而设计的下一代分布式数据仓库。它提供了简单的类似SQL的语法的HiveQL语言进行数据查询
8)HBase:建立于Hadoop Core之上提供一个可扩展的数据库系统
9)Flume:一个分布式,可靠,和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据.
10)Mahout:是一套具有可扩充能力的机器学习类库
11)Sqoop:是Apache下用于RDBMS和HDFS互相导致数据的工具。
那么我讲讲这个Hadoop中比较重要的HDFS子项目:
1、HDFS介绍以及整体结构:
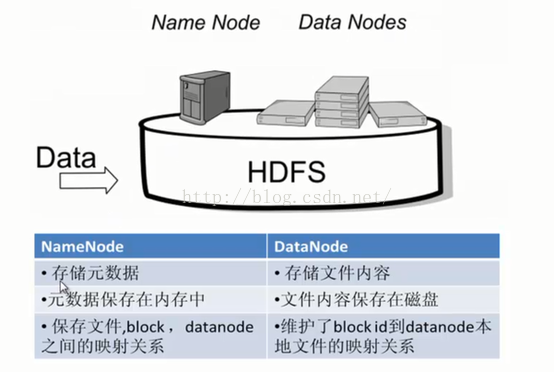
其中NN中存储的是文件的元数据,指的是文件比Data Node更小,主要存储一些文件的名称,大小...之类的属性。
3、 可能大家有点迷糊了,这个图它是怎么个工作机制的呢?图标中各个内容表达什么意思呢?其实HDFS中每当用户和数据进行交互的时候,都要通过NN来转发和接受请求,NN里通过两个文件edits log和fsimage(这两个文件的具体作用会在后面提到)找到DN中的Block并进行操作。
HDFS主要内容如下:
1)一个名字节点(Name Node)和多个数据节点(data Node)
2)数据复制(冗余机制)---存放位置(机器感知策略)
3)故障检测 --数据节点(心跳包--检测是否容机;块报告--安全模式下检测;数据完整性检测--校验和比较) --名字节点(日志文件,镜像文件)
4)空间回收机制(data Node是否还有多余的空间)
4、HDFS命令:可以使用Shell命令进行操作。
5、HDFS优点:
1)高容错性:数据自动保存多个副本;数据丢失之后,自动恢复。
2)适合批处理:移动计算而非数据;数据位置暴露给计算框架
3)适合大数据批处理:GB、TB、甚至PB级数据;处理百万规模以上的文件数量;10K+节点
4)可以构建在廉价机器上:通过多个副本提高可靠性;提供了容错和恢复机制。
6、HDFS缺点:
1)低延迟数据访问:比如毫秒级;低延迟和高吞吐率。
2)小文件存取:占用NameNode大量内存;寻道时间超过读取时间。
3)并发写入、文件随机修改:一个文件只能有一个写者;仅支持append。
7、HDFS架构:
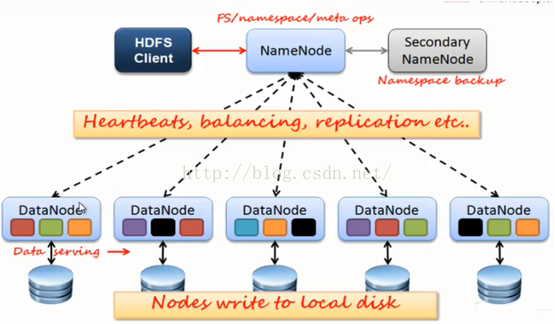
HDFS数据存储单元(block)上图颜色部分的块。
1)文件被切分成固定大小的数据块:默认数据块大小为64MB,可自己配置;若文件大小不到64MB,则单独存成一个block.
2)一个文件存储方式:按大小被切分成若干个block,存储到不同节点上;默认情况下每个block都有三个副本。
3)Block大小和副本数通过Client端上传文件时配置,文件上传成功后副本数可以变更,Block size之后不可变更。
2、HDFS---NN:
1、NameNode主要功能:接受客户端的读写服务。
2、NameNode保存metadata(元数据,除了文件内容之外的都是元数据)信息包括:
1)文件owership和permissions;文件包含哪些块
2)Block保存在哪个DataNode(由DataNode启动时上报)
3、NameNode的metadate信息在启动后加载到内存:
1)metadata存储到磁盘文件名为“fsimages”(NN主要根据fsimage来进行数据操作,SNN利用其进行合并)
2)Block位置信息不会保存到fsimage
3)edits记录对metadata的操作日志
4、Fsimage是元数据在磁盘中存储的一份数据的文件名,当我们操作一份数据的时候,并不是马上在fsimage中进行修改,而是由edits来记录操作日志,之后在某个时间让edits与fsimage合并。
3、HDFS--SNN:
1、它不是NN的备份(但可以做备份),它主要工作是帮助NN合并editslog,减少NN启动时间。
2、SNN执行合并时机:根据配置文件设置的时间间隔fs.checkpoint.period默认3600秒;根据配置文件设置edits log大小fs.checkpoint.size规定edit文件的最大值默认64MB。
3、当删除一个文件的时候其实并不是马上删除,而是在edits log中记录,到一定时间与fsimage通过SNN进行合并的时候进行删除。由于涉及大多的IO和消耗CPU,所以在NN中不做数据操作的合并,而是让另一个机器的CPU去计算实现SNN根据时间来不断合并各个NN,这样用户体验感比较好,速度也是比较快。
4、那么通过SNN合并之后的新的FSimage和edits log会被推送到NN中并且替换原来的FSimage和edits log,这样NN 里面隔段时间就是新的数据。
5、SNN合并流程:

首先是NN中的Fsimage和edits文件通过网络拷贝,到达SNN服务器中,拷贝的同时,用户的实时在操作数据,那么NN中就会从新生成一个edits来记录用户的操作,而另一边的SNN将拷贝过来的edits和fsimage进行合并,合并之后就替换NN中的fsimage。之后NN根据fsimage进行操作(当然每隔一段时间就进行替换合并,循环)。当然新的edits与合并之后传输过来的fsimage会在下一次时间内又进行合并。
4、HDFS--DN
1、存储数据(Block)
2、启动DN线程的时候会向NN汇报block信息,之后NN根据汇报的block信息来找到block数据
3、通过向NN发送心跳保持与其联系(3秒一次),如果NN 10分钟没有收到DN的心跳,则认为其已经lost,NN就会向DN发消息,告诉其副本不够,并copy其上的block到其他的DN中。
有不同见解的欢迎指正。














 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









