




 本文深入探讨了垃圾回收中的并发标记过程,特别是Snapshot At The Beginning (SATB) 技术。SATB通过保存并发标记开始时的引用关系,确保在多线程环境下正确标记存活对象。在并发标记阶段,使用写屏障记录引用变化,并通过记忆集合处理这些变化。同时,介绍了卡表和热卡片的概念,用于优化记忆集合的维护。整个过程涉及对象引用记录、区域状态管理和多线程优化,确保高效准确的垃圾回收。
本文深入探讨了垃圾回收中的并发标记过程,特别是Snapshot At The Beginning (SATB) 技术。SATB通过保存并发标记开始时的引用关系,确保在多线程环境下正确标记存活对象。在并发标记阶段,使用写屏障记录引用变化,并通过记忆集合处理这些变化。同时,介绍了卡表和热卡片的概念,用于优化记忆集合的维护。整个过程涉及对象引用记录、区域状态管理和多线程优化,确保高效准确的垃圾回收。
Snapshot-At-The-Beginning
-
标记方式有两种方式
- 增量更新(Increment Update)
- 初始快照( Snapshot At The Beginning SATB)
-
SATB( Snapshot At The Beginning, 初始快照) 是一种将并发标记阶段开始时对象间的引用关系, 以逻辑快照的形式进行保存的手段
-
介绍并发标记
-
介绍简单标记
- 在简单标记中, 所有可从根直接触达的对象都会被添加标记。 带标记的是存活对象, 不带标记的是死亡对象
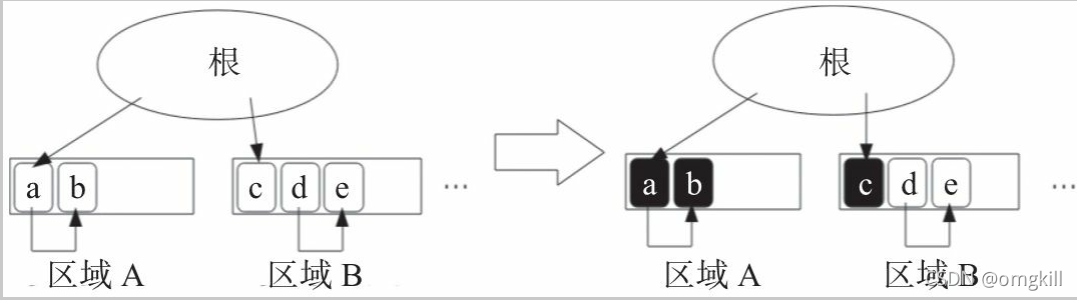
- 在简单标记中, 所有可从根直接触达的对象都会被添加标记。 带标记的是存活对象, 不带标记的是死亡对象
-
标记位图
-
将用于标记的比特值等信息单独拿出来放到其他地方, 用来匹配对应的对象。
-
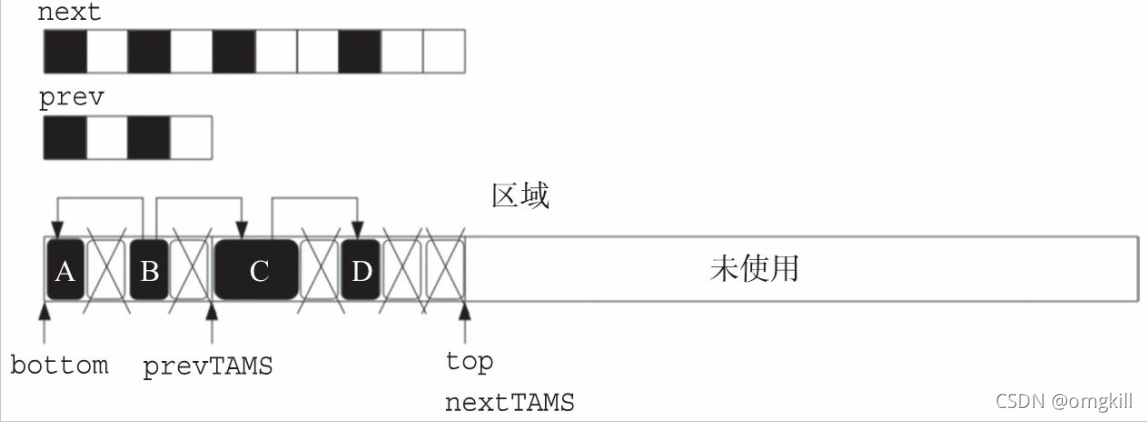
- bottom 表示区域内众多对象的末尾
- nextTAMS 中的 TAMS 是“Top At Marking Start”(标记开始时的 top) 的缩写
- nextTAMS 保存了本次标记开始时的 top, 而 prevTAMS 保存了上次标记开始时的 top。
- next 是本次标记的标 记位图
- prev 是上次标记的标记位图, 保存了上次标记的结果
-
-
-
流程
-
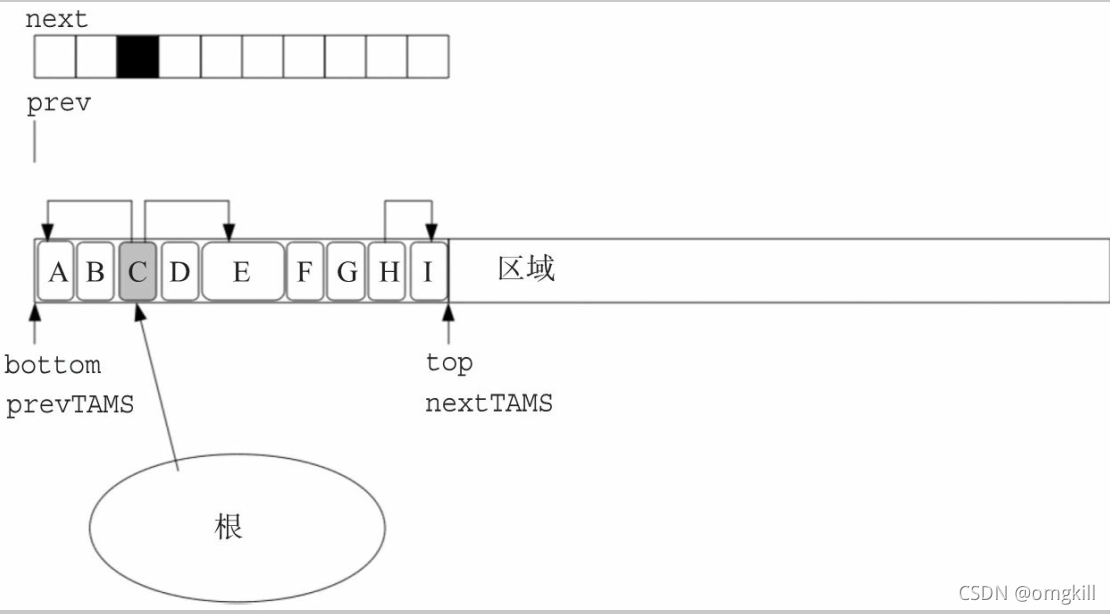
初始标记阶段
- GC 线程首先会创建标记位图 next
- nextTAMS 指的 就是标记开始时 top 所在的位置, 所以在这里我们将它和 top 对齐
-
并发标记阶段
-
概念:在并发标记阶段, GC 线程继续扫描在初始
-
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2349
2349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









