







作为(曾)被认为两大最好的监督分类算法之一的adaboost元算法(另一个为前几节介绍过的SVM算法),该算法以其简单的思想解决复杂的分类问题,可谓是一种简单而强大的算法,本节主要简单介绍adaboost元算法,并以实例看看其效果如何。
该算法简单在于adaboost算法不需要什么高深的思想,它的基础就是一个个弱小的元结构(弱分类器),比如就是给一个阈值,大于阈值的一类,小于阈值的一类,这样的最简单的结构。而它的强大在于把众多个这样的元结构(弱分类器)组合起来一起发挥功效,所谓人多力量大,就是这个道理,组合起来的最终的分类器就是一个强分类器了。相比于SVM,SVM本身是一个个体,本身也就是一个强分类器,是一个天生的天才,而adaboost元算法,把它比如下更像是后天的天才,努力的天才,是建立在广大人名群众上面的天才。
好了,言归正传,所谓元算法,就是建立在元结构基础上,也就是一个个弱分类器(广大人民群众),这个弱分类器可以任何的分类器,可以是简单决策树、简单线性logistic分类器,简单的svm等等,都可以作为它的第一层弱分类器。而一般情况下采用单层决策树分类器作为基础的分类器比较多。所谓单层决策树就是给一个或者多个阈值,将一系列数分成好几堆一样。
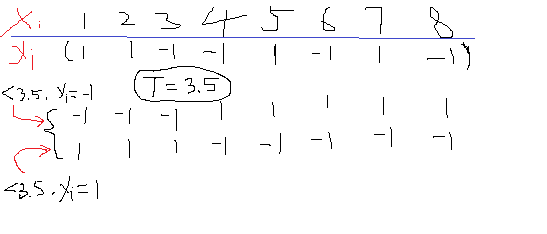
比如下面的一维数据X,其对应的标签如下为y,那么如果任意给定一个阈值T=3.5,那么就可以把X分成两类了,这里就有个问题,小于T的是分成类1还是类-1呢?所以会存在两种情况吧,如上面所示,至于这个阈值好不好,小于T的是归类为1好还是-1好,那后面再说。
本节就是以这种简单的单阈值的决策树作为算法的元结构,也就是弱分类器来实现强分类器。好了再回来说刚刚的问题,首先你怎么知道阈值T=3.5,答案是不知道,那么只能一个个取了。我找到数据X的上下限,然后设置一个步长比如10步,然后就让T从最小值慢慢往上加吧。假设加到了T=3.5了,这个时候到了小于T是取1还是-1的时候了,所以又得分类讨论如果为1,如果为-1。那么我们怎么去判断阈值究竟是哪一个T好了?好了之后数据小于阈值T是是+1还是-1呢?我们看到,对于每一个阈值,然后对于该阈值下的一个取值方向(也就是小于T是+1还是-1),都会出来一个分类结果吧,有了这个结果,我把它与正确的分类结果挨个去比较看看错误率是多少,这样是不是有一个评价标准了,有了这个评价标准就可以知道在遍历所有的T的时候到底是选择那个T最好,同时是选择小于T的为-1还是+1的情况比较好。比如上面那个图,在T为3.5的时候,如果小于T取-1,那么错了5个,所以错误率为5/8。如果小于T取+1,那么正好相反错了3个,错误率3/8,所以这个时候T=3.5时小于T的取+1类比较好。上面只给了T=3.5的,那么你是不是还可以算T=4,5,等等的情况,这样遍历一圈后,找到那个最小错误率下的T以及方向是不是就知道这一组数据在这个单层决策树下的阈值以及阈值的方向了。
那这是一维数据,如果是二维数据怎么使用单层决策树呢?要是二维的,那就一维一维的来吧,比如一个二维样本点如下:
那这个时候我们先找X维的数据,也就是把所有点的x坐标提出来作为一个一维样本,然后进行寻找最佳T与方向,方法同上面那样,不过这个时候找到的T还多了一个标记,就是它是在哪一维上的最小误差,比如说先找X维,那么在X维找完后,就需要记录三个值,一个是维度比如为1代表是在第一位上找的。一个是T,就是阈值,一个是T的方向,就是小于T的值是取+1还是-1,当然还有这一维下的最小错误率。完事后转战到第二维Y,在Y上同样遍历所有的T,不过这个时候遍历的时候就要和X维找完了的那个最小错误率比较,也就是说如果在Y维上还能找到一个阈值T使得划分的结果的错误率还小,那么就更新这个T。所以在遍历了所有的X维与Y维后的最优结果就需要有这么几个参数:一是最佳T来自于哪一维,二是这个T是多少,三是这个T下的方向是+1还是-1,四是对应下的错误率是多少。
那这是二维,同理可以扩展到多维吧。
好了这样一个弱分类器(元结构)就完成了。如果单单去用这个弱分类器去分类的话显然是不准的,这也就好比是在x或者y的某一处画了一条直线,然后按照这条直线去分一样。如果碰巧数据时线性的,效果会好点,碰到非线性的,效果肯定不会好的。
说了半天,我们才把一个人的力量(弱分类器)说完,我们说adaboost元算法是众人的力量,也就是系列弱分类器的力量,那么这一系列弱分类器是怎么联系起来的呢?
上面还说漏了一点内容,就是每个样本点所占的权重问题,也就是每个样本点在最终错误率上占有的比重,反之就是对正确率上占有的比重。比如上面那个二维样本由15个样本点,那么我可以给相同的权重,同时为了保证所有的权重和为1,所以初始化权重D=[1/15,1/15,…….]等等15个1/15。那么这个权重表现在哪里呢?最后我们在算错误率的时候是不是需要寻找预测的与真实的类标签差别吗?那么这个权重可以用在这里,与这个差相乘。也就是如果标签相同,差为0,对应的权重相乘完还是0,没有用到,但是一旦不为0,那么权重就会使得这个差按权重比例放大是不是?所以说这个权重就可以用来计算那些不一样的点,并使得结果变得更好。
好了权重说完了,再来看看这一系列弱分类器是怎么联系起来的,其实联系的方式就是改变上述权重D的过程。具体怎么改变的呢?首先我们需要规定有多少个弱分类器,这需要自己设置。然后我们挨个的去找每个弱分类器的参数(这个参数就是上述的那几个输出值:属于哪一维?T是多少?T的方向?最小误差?当然这里还多出一个,这个弱分类器的D是多少?)。
既然挨个的去找每个弱分类器的参数,那么第一个弱分类器首先就假设一个D=[1/15,1/15,…….],权重均等,有多少个样本,每个样本权重就是多少分之一。然后去找吧,最终会出来T及其参数吧。那么第一个弱分类器找完了。接下来第二个弱分类器,若果D不做任何改变,是不是第二个弱分类器出来的结果T什么的和第一个会一模一样?对,就是一样。那么这个时候关键的地方来了,第二个弱分类器会学习第一个弱分类器,假设第一个弱分类器出来的结果,错误率为 ϵ ,那么
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4280
4280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









