







最近一直再看《hadoop in action》这本书,这本书整体讲的不错,就是hadoop不同版本之间的区别比较大,大家学习时一定要用统一版本,否则事倍功半。
书上第4章第四节讲的是版本间的区别,我这里简单整理一下:
去hadoop的官网可以找到如下信息:
- 1.0.X - current stable version, 1.0 release
- 1.1.X - current beta version, 1.1 release
- 2.X.X - current alpha version
- 0.23.X - simmilar to 2.X.X but missing NN HA.
- 0.22.X - does not include security
- 0.20.203.X - old legacy stable version
- 0.20.X - old legacy version
http://hadoop.apache.org/releases.html 写作时间:2013-3-10 16:25
-------------------------------update 2014-7-22---------------------------------------------------------
无奈,以前对hadoop的版本总结的不是太清楚,这里重新总结次。先上3个关于版本说明的图:



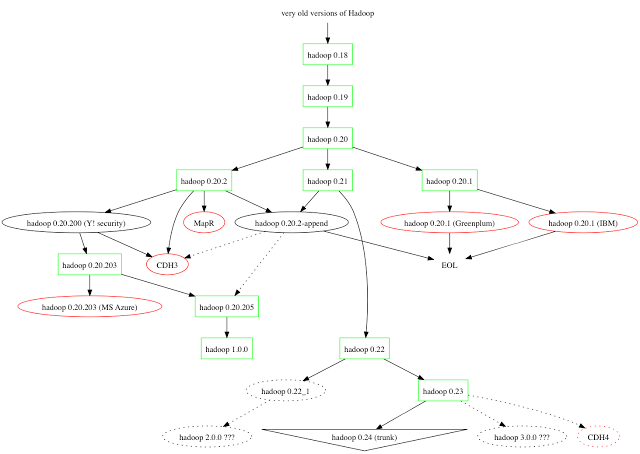
上图可以看出:
- 0.20这个分支最终演变为1.X分支,并且在0.20这个分支中有几个重要版本,也就是0.20.2增加了真正意义上的Append操作。到了0.20.205后直接重命名为1.0,这两个版本没什么变化,就仅仅是个rename的变化
- 0.23这个分支最终演变为2.X分支,也就是现在说的Hadoop2.0,这个版本变化比较大,引入了YARN、HDFS Federation
- hadoop 1.0 指的是1.x(0.20.x),0.21,0.22
- hadoop 2.0 指的是2.x,0.23.x
参考链接:
http://blog.cloudera.com/blog/2012/01/an-update-on-apache-hadoop-1-0/
http://blog.cloudera.com/blog/2012/04/apache-hadoop-versions-looking-ahead-3/
http://elephantscale.com/hadoop2_handbook/Hadoop_Versions.html
--------------------end---------------------
这说明hadoop的发展还是挺快的,有各种各样的版本,alpha beta stable都有,这也说明了开源的hadoop是广大程序员处理大数据的首选。
书上说最稳定的版本是0.18.3,但是鉴于这本书写与09年,所有这个参考价值不是很大。但是0.20这个版本是个承上启下的版本,它对于老版本的api全部支持,只是标注了deprecated的,但是0.20之后的版本直接就把老的api给删去了,0.20同时也很好的支持新发布版本的api,所以这个版本可以用来学习使用。
0.20之前版本中,org.apache.hadoop.mapred包中的内容在新版本被移除了,放在了org.apache.hadoop.mapreduce这个新包中,许多类都在org.apache.hadoop.mapreduce.lib包中。如果我们使用了0.20以后的版本,我们就不能引用org.apache.hadoop.mapred包中的类了。
在新版本中,最有意义的变化是引入了context这个类,它可以代替OutputCollector和Reporter这两个对象。
在新版本中,map()函数和reduce()被放到了抽象类Mapper和Reducer类中,这两个抽象类代替了org.apache.hadoop.mapred.Mapper和org.apache.hadoop.mapred.Reducer这两个接口。同时也代替了MapReduceBase这个类。
在新版本中,JobConf和JobClient被移除了。它们的功能被放到Configuration类和新增的Job类中去了(Configuration以前是JobConf的父类)。Configuration类只是用来配置一个job,而Job类用来定义和控制job的运行。
下面给出一些老版本与新版本代码,以后大家些hadoop程序就可以按照这个模板了。
先给出老版本的代码:
package com.ytu.old;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.KeyValueTextInputFormat;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.Tool;
public class MyOldJob extends Configured implements Tool {
public static class MapClass extends MapReduceBase implements
Mapper<Text, Text, Text, Text> {
@Override
public void map(Text key, Text value, OutputCollector<Text, Text> output,
Reporter arg3) throws IOException {
// TODO Auto-generated method stub
output.collect(value, key);
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
// TODO Auto-generated method stub
String csv = "";
while(values.hasNext()) {
if (csv.length()>0) {
csv+=",";
}
csv+=values.next().toString();
}
output.collect(key, new Text(csv));
}
}
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = this.getConf();
JobConf job = new JobConf(conf, MyOldJob.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setJobName("MyOldJob");
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(KeyValueTextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.set("key.value.separator.in.input.line", ",");
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MyOldJob(), args);
System.exit(res);
}
}
然后在给出新版本的代码:
package com.ytu.new1;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyNewJob extends Configured implements Tool {
public static class MapClass extends Mapper<LongWritable, Text, Text, Text> {
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] citation = value.toString().split(",");
context.write(new Text(citation[1]), new Text(citation[0]));
};
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String csv = "";
for (Text val : values) {
if (csv.length() > 0) {
csv += ",";
}
csv += val.toString();
}
context.write(key, new Text(csv));
};
}
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = this.getConf();
Job job = new Job(conf, "MyNewJob");
job.setJarByClass(MyNewJob.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true)?0:1);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new MyNewJob(), args);
System.exit(res);
}
}
最后再说一点:
书上说KeyValueTextInputFormat这个类在0.20中被移除了,但是我现在用的是版本1.1.0.这个类照样可以用,但是如果要想设置分隔符的方式不一样,
对于hadoop 1.1.0 要用mapreduce.input.keyvaluelinerecordreader.key.value.separator

hadoop 0.2。0 要用 key.value.separator.in.input.line

其他用法一样。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









