







String两种实例化方式:
1.直接赋值 2.通过构造方法完成
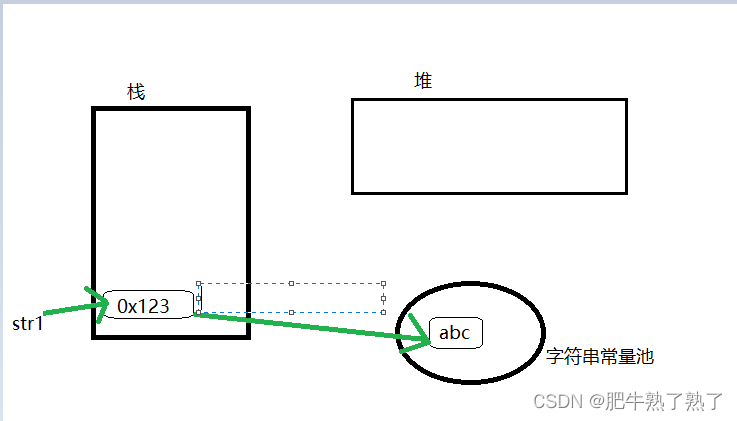
String str1 =“abc”;
String str2 = new String("abc");1. 直接赋值
直接赋值可以节省内存
String str1 =“abc”;表示一个堆内存指向给了栈内存。
步骤:
- 栈中开辟一块空间存放引用变量str1。
- 到字符串常量池查找栈中有没有存放"abc", 如果有,直接令str 指向"abc";如果没有String池中开辟一块空间,存放String常量”abc”。
- 引用str1指向池中String常量”abc”。
- jvm(java virtual machine)会自动根据栈中数据的实际情况来决定是否有必要创建新的对象。
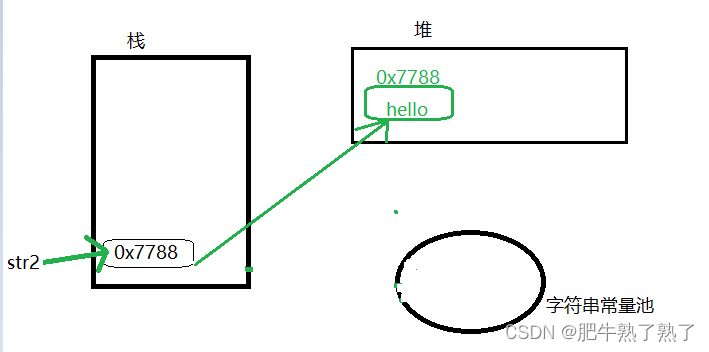
2. new()
String str2 = new String("hello"); //创建String对象 每调用一次就会创建一个新的对象
步骤:
- 栈中开辟一块空间存放引用str2
- 堆中开辟一块空间存放一个新建的String对象“hello”
- 引用str2指向堆中的新建的String对象”hello”
1、若对一个类不重写,它的equals()方法是如何比较的?
1.在Object类中,equals方法是用来比较两个对象的引用是否相等,即是否指向同一个对象,作用和"=="相同。
2.如果 String 类重写了 equals 方法:
- 先 比较引用是否相同(是否为同一对象),
- 再 判断类型是否一致(是否为同一类型),
- 最后 比较内容是否一致
2、请解释hashCode()和equals()方法有什么联系?
1.hashCode():
-
先调用这个元素的 hashCode 方法,然后根据所得到的值计算出元素应该在数组的位置。如果这个位置上没有元素,那么直接将它存储在这个位置上;
-
如果这个位置上已经有元素了,那么调用它的equals方法与新元素进行比较:相同的话就不存了,否则,将其存在这个位置对应的链表中
总结:
1 相等(相同)的对象必须具有相等的哈希码(或者散列码)。
2 如果两个对象的hashCode相同,它们并不一定相同。
3、Java中的方法覆盖(Overriding)和方法重载(Overloading)是什么意思?重载的方法能否根据返回类型进行区分?
1.方法重写(覆写,覆盖):在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding)。
重写规则:三同一大一小(方法名、返回值、参数类型相同;访问权限>=重写前;抛出异常<=重写前)
1、参数列表必须完全与被重写的方法相同,否则不能称其为重写而是重载。
2、返回的类型必须一直与被重写的方法的返回类型相同,否则不能称其为重写而是重载。
3、访问修饰符的限制一定要大于被重写方法的访问修饰符(public>protected>default>private)
4、重写方法一定不能抛出新的检查异常或者比被重写方法申明更加宽泛的检查型异常。例如: 父类的一个方法申明了一个检查异常IOException,在重写这个方法是就不能抛出Exception,只能抛出IOException的子类异常,可以抛出非检查异常。
2.方法重载发生在同一个类里面两个或者是多个方法的方法名相同但是参数不同,返回值类型可以相同也可以不相同。调用方法时通过传递给它们的不同参数个数和参数类型来决定具体使用哪个方法, 对返回类型没有特殊的要求,这就是多态性。
两者区别:
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求。
4、请解释Java中的概念,什么是构造函数?什么是构造函数重载?什么是复制构造函数?
1.构造函数:当创建新对象的时候,会调用构造函数。每一个类都有构造函数并且Java编译器会为这个类创建一个默认的构造函数。
2.构造函数重载:和方法重载很相似。可以为一个类创建多个构造函数。每一个构造函数必须有它自己唯一的参数列表。
3.复制构造函数:Java不支持像C++中那样的复制构造函数,不自己写构造函数的情况下,Java不会创建默认的复制构造函数。
5、请说明Query接口的list方法和iterate方法有什么区别?
1.list()方法无法利用一级缓存和二级缓存(对缓存只写不读),它只能在开启查询缓存的前提下使用查询缓存;
iterate()方法可以充分利用缓存,如果目标数据只读或者读取频繁,使用iterate()方法可以减少性能开销。
2. list()方法不会引起N+1查询问题,而iterate()方法可能引起N+1查询问题
6、面向对象六原则一法则
- 单一职责原则:一个类只做它该做的事情。(单一职责原则想表达的就是"高内聚",写代码最终极的原则只有六个字"高内聚、低耦合",所谓的高内聚就是一个代码模块只完成一项功能,在面向对象中,如果只让一个类完成它该做的事,而不涉及与它无关的领域就是践行了高内聚的原则,这个类就只有单一职责。另一个是模块化,好的自行车是组装车,从减震叉、刹车到变速器,所有的部件都是可以拆卸和重新组装的,好的乒乓球拍也不是成品拍,一定是底板和胶皮可以拆分和自行组装的,一个好的软件系统,它里面的每个功能模块也应该是可以轻易的拿到其他系统中使用的,这样才能实现软件复用的目标。)
- 开闭原则:软件实体应当对扩展开放,对修改关闭。(在理想的状态下,当我们需要为一个软件系统增加新功能时,只需要从原来的系统派生出一些新类就可以,不需要修改原来的任何一行代码。要做到开闭有两个要点:①抽象是关键,一个系统中如果没有抽象类或接口系统就没有扩展点;②封装可变性,将系统中的各种可变因素封装到一个继承结构中,如果多个可变因素混杂在一起,系统将变得复杂而换乱,如果不清楚如何封装可变性,可以参考《设计模式精解》一书中对桥梁模式的讲解的章节。)
- 依赖倒转原则:面向接口编程。(该原则说得直白和具体一些就是声明方法的参数类型、方法的返回类型、变量的引用类型时,尽可能使用抽象类型而不用具体类型,因为抽象类型可以被它的任何一个子类型所替代,请参考下面的里氏替换原则。)
里氏替换原则:任何时候都可以用子类型替换掉父类型。(关于里氏替换原则的描述,Barbara Liskov女士的描述比这个要复杂得多,但简单的说就是能用父类型的地方就一定能使用子类型。里氏替换原则可以检查继承关系是否合理,如果一个继承关系违背了里氏替换原则,那么这个继承关系一定是错误的,需要对代码进行重构。例如让猫继承狗,或者狗继承猫,又或者让正方形继承长方形都是错误的继承关系,因为你很容易找到违反里氏替换原则的场景。需要注意的是:子类一定是增加父类的能力而不是减少父类的能力,因为子类比父类的能力更多,把能力多的对象当成能力少的对象来用当然没有任何问题。)
- 接口隔离原则:接口要小而专,绝不能大而全。(臃肿的接口是对接口的污染,既然接口表示能力,那么一个接口只应该描述一种能力,接口也应该是高度内聚的。例如,琴棋书画就应该分别设计为四个接口,而不应设计成一个接口中的四个方法,因为如果设计成一个接口中的四个方法,那么这个接口很难用,毕竟琴棋书画四样都精通的人还是少数,而如果设计成四个接口,会几项就实现几个接口,这样的话每个接口被复用的可能性是很高的。Java中的接口代表能力、代表约定、代表角色,能否正确的使用接口一定是编程水平高低的重要标识。)
- 合成聚合复用原则:优先使用聚合或合成关系复用代码。(通过继承来复用代码是面向对象程序设计中被滥用得最多的东西,因为所有的教科书都无一例外的对继承进行了鼓吹从而误导了初学者,类与类之间简单的说有三种关系,Is-A关系、Has-A关系、Use-A关系,分别代表继承、关联和依赖。其中,关联关系根据其关联的强度又可以进一步划分为关联、聚合和合成,但说白了都是Has-A关系,合成聚合复用原则想表达的是优先考虑Has-A关系而不是Is-A关系复用代码,原因嘛可以自己从百度上找到一万个理由,需要说明的是,即使在Java的API中也有不少滥用继承的例子,例如Properties类继承了Hashtable类,Stack类继承了Vector类,这些继承明显就是错误的,更好的做法是在Properties类中放置一个Hashtable类型的成员并且将其键和值都设置为字符串来存储数据,而Stack类的设计也应该是在Stack类中放一个Vector对象来存储数据。记住:任何时候都不要继承工具类,工具是可以拥有并可以使用的,而不是拿来继承的。)
- 迪米特法则:迪米特法则又叫最少知识原则,一个对象应当对其他对象有尽可能少的了解。再复杂的系统都可以为用户提供一个简单的门面,Java Web开发中作为前端控制器的Servlet或Filter不就是一个门面吗,浏览器对服务器的运作方式一无所知,但是通过前端控制器就能够根据你的请求得到相应的服务。调停者模式也可以举一个简单的例子来说明,例如一台计算机,CPU、内存、硬盘、显卡、声卡各种设备需要相互配合才能很好的工作,但是如果这些东西都直接连接到一起,计算机的布线将异常复杂,在这种情况下,主板作为一个调停者的身份出现,它将各个设备连接在一起而不需要每个设备之间直接交换数据,这样就减小了系统的耦合度和复杂度
7、请说明如何通过反射获取和设置对象私有字段的值?
可以通过类对象的getDeclaredField()方法字段(Field)对象,然后再通过字段对象的setAccessible(true)将其设置为可以访问,接下来就可以通过get/set方法来获取/设置字段的值了。
8、内部类可以引用他包含类的成员吗,如果可以,有没有什么限制吗?
一个内部类对象可以访问创建它的外部类对象的内容,1. 普通内部类可以访问创建它的外部类对象的所有属性;2. sattic内部类即为nested class,只可以访问创建它的外部类对象的所有static属性
一般普通类只有public或package的访问修饰,而内部类可以实现static,protected,private等访问修饰。
当从外部类继承的时候,内部类是不会被覆盖的,它们是完全独立的实体,每个都在自己的命名空间内,如果从内部类中明确地继承,就可以覆盖原来内部类的方法。
9、JAVA语言如何进行异常处理,关键字:throws,throw,try,catch,finally分别代表什么意义?在try块中可以抛出异常吗?
Java 通过面向对象的方法进行异常处理,把各种不同的异常进行分类,并提供了良好的接口。在Java中,每个异常都是一个对象,它是Throwable类或其它子类的实例。当一个方法出现异常后便抛出一个异常对象,该对象中包含有异常信息,调用这个对象的方法可以捕获到这个异常并进行处理。
1、try出现在方法体中,它自身是一个代码块,表示尝试执行代码块的语句。如果在执行过程中有某条语句抛出异常,那么代码块后面的语句将不被执行。
2、throw出现在方法体中,用于抛出异常。当方法在执行过程中遇到异常情况时,将异常信息封装为异常对象,然后throw。
3、throws出现在方法的声明中,表示该方法可能会抛出的异常,允许throws后面跟着多个异常类型
4、catch出现在try代码块的后面,自身也是一个代码块,用于捕获异常try代码块中可能抛出的异常。catch关键字后面紧接着它能捕获的异常类型,所有异常类型的子类异常也能被捕获。
5、finally 一定被执行,任何执行try 或者catch中的return语句之前,都会先执行finally语句,如果finally存在的话。如果finally中有return语句,那么程序就return了,所以finally中的return是一定会被return的,
(12条消息) java的异常处理try, catch,throw,throws和finally_YULIU_的博客-CSDN博客
10、请说明Java的接口和C++的虚类的相同和不同处
由于Java不支持多继承,而有可能某个类或对象要使用分别在几个类或对象里面的方法或属性,现有的单继承机制就不能满足要求。与继承相比,接口有更高的灵活性,因为接口中没有任何实现代码。当一个类实现了接口以后,该类要实现接口里面所有的方法和属性,并且接口里面的属性在默认状态下面都是public static,所有方法默认情况下是public.一个类可以实现多个接口。
11、请判断当一个对象被当作参数传递给一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
值传递。Java 编程语言只有值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的内容可以在被调用的方法中改变,但对象的引用是永远不会改变的。
12、浅拷贝和深拷贝区别(Object类下的clone方法)
12.1浅拷贝:
(1) 对于基本数据类型的成员对象,因为基本数据类型是值传递的,所以是直接将属性值赋值给新的对象。基本类型的拷贝,其中一个对象修改该值,不会影响另外一个。
(2) 对于引用类型,比如数组或者类对象,因为引用类型是引用传递,所以浅拷贝只是把内存地址赋值给了成员变量,它们指向了同一内存空间。改变其中一个,会对另外一个也产生影响。
12.2深拷贝:
(1) 对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个(和浅拷贝一样)。
(2) 对于引用类型,比如数组或者类对象,深拷贝会新建一个对象空间,然后拷贝里面的内容,所以它们指向了不同的内存空间。改变其中一个,不会对另外一个也产生影响。
(3) 对于有多层对象的,每个对象都需要实现 Cloneable 并重写 clone() 方法,进而实现了对象的串行层层拷贝。
(4) 深拷贝相比于浅拷贝速度较慢并且花销较大。















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









