






 RADICORE是一个基于PHP的快速应用开发框架,采用三层架构和MVC设计模式,支持XML/XSL转换生成HTML页面,实现前后端分离。
RADICORE是一个基于PHP的快速应用开发框架,采用三层架构和MVC设计模式,支持XML/XSL转换生成HTML页面,实现前后端分离。
Rapid Application Development toolkit for building Administrative Web Applications
RADICORE - A Development Infrastructure for PHP
By Tony Marston
2nd August 2003
Amended 15th July 2005
As of 10th April 2006 the software discussed in this article can be downloaded from www.radicore.org
-
Introduction
- Background
The 3 Tier Architecture
- Data Access layer
- Business layer
- Presentation layer
The Model-View-Controller (MVC) design pattern
- The Model component
- The View component
- The Controller component
Infrastructure Design
- Forms Families
- Structure, Behaviour, Content ...
- ... and Style
Infrastructure Implementation
- Component scripts
- Transaction Pattern (Controller) scripts
- Generic (abstract) Table class
- Database Table (Model) classes
- Validation class
- DML class
- Screen Structure (View) scripts
- XML files
- XSL Stylesheets
- XSL Transformation process
- HTML output
- CSS files
- AUDIT class
- Workflow Engine
Levels of Reusability
Extending this Infrastructure
References
Amendment History
Introduction
With every programming language I have worked in it has become normal practice, after having developed an initial series of programs, to identify a common structure to which all subsequent programs should be built. This may take some time as it involves a bit of trial and error in playing with the different ways in which a task can be achieved in order to find the methodology that gives the most advantages in the long term. Eventually this development infrastructure/environment should contain the following:-
- A description as to how the user interfaces should be built so as to provide a consistent look and feel.
- A list of naming conventions to identify how objects, functions and programs should be named.
- A description of the directory structure used in the development environment so everybody knows where each type of object is supposed to be located.
- A description of the strategies to be used when building programs.
- A library of standard functions that can be used to perform common tasks.
The list can be extended even further, but that will do as a starting point.
Background
The PHP development environment that I have devised was created by taking a set of sample programs which I had assembled for a previous language and rewriting them in PHP. These sample programs were used as patterns or templates for all other programs in my applications as they represented all the combinations of structure and behaviour that I had encountered. To build a new component all I had to do was identify the right template, then specify which database tables(s) and columns I wished to show on the screen for the new component. Each database table was accessed via its own separate service component which contained all the business rules associated with that table plus the code to communicate with the database. As each user screen accessed each database table by its own service component it meant that business logic was shared and not duplicated. Both user screens and service components used shared code in the form of 'include' files, so it was possible to update the shared library and have the changes automatically picked up by the various components.
From the outset my aim was to produce an environment with the following characteristics:-
- To be based on the 3 Tier Architecture so that the logic for the presentation layer, the business layer and the data access layer would be contained within separate components. This architecture allows the code within any one of the layers to be changed without affecting any of the other layers.
- To make use of as many standard reusable scripts as possible. I have been long familiar with the advantages of having libraries of reusable subroutines and functions in other development languages, and my previous language, a 4th generation tool called UNIFACE, had the extra ability of components being able to inherit code from component templates.
- To make use of the OO capabilities of PHP, but only where I saw an advantage in doing so. I do not believe OO is a universal panacea as any old problems which it claims to solve are counter-balanced by new problems which it creates. OOP techniques do not prevent errors, they simply create a new class of error.
What I actually produced is as follows:-
- As I was familiar with XML and XSL before learning PHP, and because PHP already incorporates modules for those two disciplines, I chose to generate all HTML output via XML/XSL transformations. I did read about other templating engines that are available for PHP, but as these are written in PHP and tied to PHP I rejected them as I wanted something that was totally independent of the underlying language and preferably written to 'open' standards and therefore accessible to a larger community.
- After building several screens with XSL stylesheets I identified a great deal of common code and moved it to a series of smaller XSL files which can be 'included' at runtime. Now when I build a stylesheet for a component it contains a large number of calls to my library of common templates.
- All HTML output is written to W3C standards and is therefore browser-independent. The output is actually XHTML 1.0 Strict with all formatting specified via Cascading Style Sheets (CSS). There is no JavaScript as this is not controlled by any W3C standard and there are too many incompatibilities with its implementation between the different browsers. This decision allows the software to work as intended on any browser, the only condition being that the browser complies to W3C standards. If anyone has a non-standard browser then any problems are theirs, not mine.
- With UNIFACE I had successfully implemented the 3 Tier Architecture by using service components in the middle layer, and as there are distinct similarities between 'components' and 'objects' (see Using PHP Objects to access your Database Tables (Part 1) for details) I found it very easy to build a class for each database table where previously I had used a service component. The ability for a component to inherit code from a component template was replaced by the ability for a class to inherit code from it's superclass.
- In my first implementation I had a standard set of functions within my abstract database class which dealt with the creation and execution of all DML (Data Manipulation Language) statements. I have subsequently been able to extract all of those functions and place them in a class of their own, thus creating a totally separate DML object in the data access layer.
- I have thus ended up with a 'true' 3 Tier structure as
- Only my data access layer has any form of communication with the database.
- All business rules are processed by objects within the business layer.
- All interfacing with the user is done by components within the presentation layer.
- There is no direct communication between the presentation and data access layers. All communication is routed through the business layer.
- Although I had not intended to use the Model-View-Controller (MVC) design pattern in my infrastructure (a previous encounter with someone else's disastrous implementation had not convinced me of any benefits), I later realised that what I had produced was a good fit to the MVC principles. It just goes to show that it is not what you implement but how you implement it that is important.
Interestingly enough my decision to have all HTML output generated through XSL transformations instead of directly by PHP code actually paid enormous dividends by producing a great deal more reusable code than I had originally anticipated. I started by creating a script which performed an operation on a database table then wrote a second script to perform the same operation on a different table. I then compared the two scripts to see what was duplicated and could therefore be put into a sharable file, and what was different and which would have to remain in a script of its own. By careful engineering of the code I ended up with the situation where there were basically only two differences:
- The name of the database table to be accessed.
- The name of the XSL file to be used to transform the output.
I ended up with three types of PHP script in my presentation layer:
- Unique Component scripts which identify which Model, View and Controller components to use.
- Sharable Transaction Pattern (Controller) scripts to carry out the communication with the business layer objects and which produce the HTML output.
- Screen structure scripts which control how the output is displayed. Some of these can be shared by several components.
When building the XSL stylesheets I came across common code which I was able to move into separate files as XSL templates (subroutines). These templates can be accessed by any number of stylesheets using the <xsl:include> command. A later improvement meant that instead of having a separate XSL stylesheet for each screen where the field names and field labels were hard-coded I could use a much smaller number of generic stylesheets and have the list of field names and field labels supplied within the XML file. The type of HTML control to be used for each field is written to the XML file as a series of field attributes, and a standard XSL template uses these attributes to generate the correct HTML code.
The 3 Tier Architecture
Any piece of software can be subdivided into the following areas:
- Presentation logic = User Interface, displaying data to the user, accepting input from the user.
- Business logic = Business Rules, handles data validation and task-specific behaviour.
- Data Access logic = Database Communication, constructing SQL queries and executing them via the relevant API.
If you put the code which deals with presentation logic (the generation of HTML documents), business logic (the processing of business rules) and data access logic (the generation and execution of DML (SQL) statements) into a single component then what you have is a single tier structure, as shown in Figure 1.
Figure 1 - 1 Tier architecture
If you split off all the code that handles the communication with the physical database to a separate component then you have a 2 tier architecture, as shown in Figure 2.
Figure 2 - 2 Tier architecture
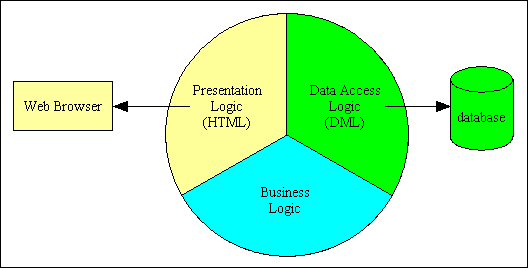
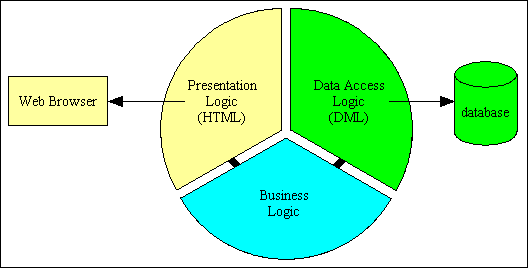
If you go one step further and split the presentation logic from the business logic you have a 3 Tier Architecture, as shown in Figure 3. Note that there is no direct communication between the presentation and data access layers - everything must go through the business layer in the middle.
Figure 3 - 3 Tier Architecture
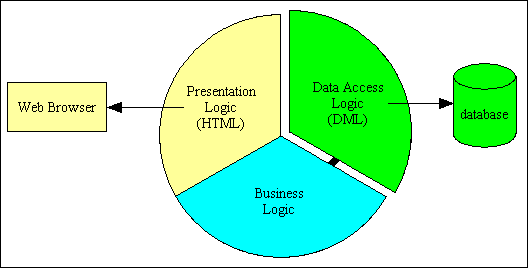
When this architecture is implemented the benefits will become apparent as more code can be shared instead of being duplicated. Several components in the presentation layer can share the same component in the business layer, and all components in the business layer share the same component in the data access layer. This is shown in Figure 4. Note also that a presentation layer component can access more than one business layer component, and a business layer component can access other business layer components.
Figure 4 - 3 Tier Architecture in operation
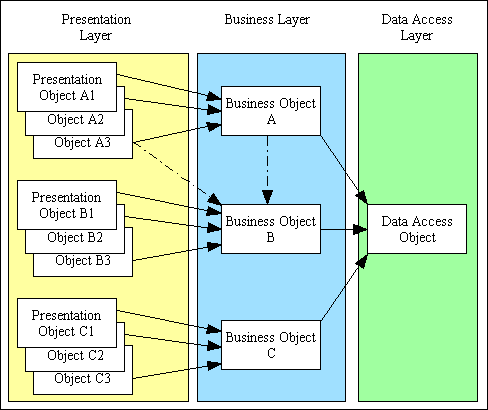
The big advantage of a 3-tier system is that it is possible to change the contents of any one of the tiers/layers without having to make corresponding changes in any of the others. For example:
- A change from one DBMS to another would only require a change to the component in the data access layer.
- A change in the Use Interface, for example from desktop to the web, would only require changes to the components in the presentation layer.
An advantage of having the presentation and business layers written in different languages is that it is possible to use different teams of developers to work on each. That means I can need only PHP skills on the business and data access layers, and (X)HTML, CSS and XSL skills for the presentation layer. It may be easier to find developers with skills in one of these areas rather than both.
Another advantage of using XML/XSL in the presentation layer is that it is possible to switch the output from HTML to WML or PDF or whatever simply by using a different XSL stylesheet. XSL files can be used to transform XML documents into a variety of formats, not just HTML.
The environment which I have created is based on the 3-tier architecture, as shown in Figure 5.
Figure 5 - Environment/Infrastructure Overview
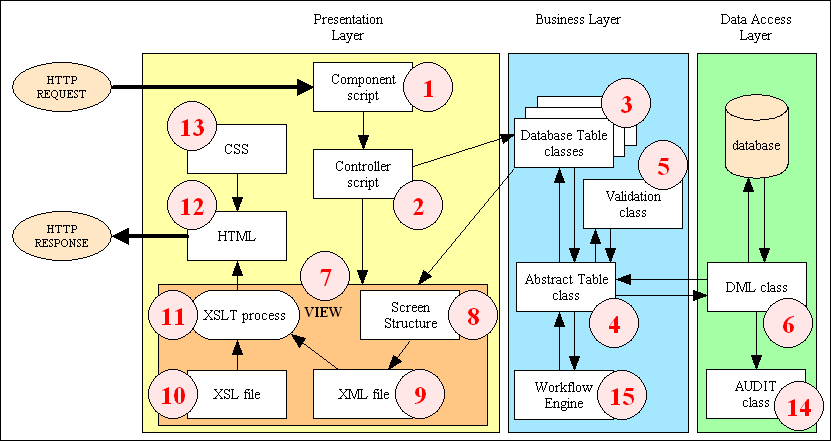
The various components in Figure 5 are described as follows:
- Component scripts
- Transaction Pattern (Controller) scripts
- Database Table (Model) classes
- Generic (abstract) table class
- Validation class
- DML class
- Screen Structure (View) scripts
- XML files
- XSL Stylesheets
- XSL Transformation process
- HTML output
- CSS files
- AUDIT class
- Workflow Engine
Note that this is proper 3-Tier Architecture, not the pseudo variety as claimed by many who seem to think that the arrangement of web browser, web server and database automatically constitutes a 3 Tier system. It is the construction of the software in the middle that decides whether the system is 1, 2 or 3 Tier. It is only when a system has separate components to deal with the different areas of logic that it can be truly described as 3-tier.
The infrastructure described in this document has the following degrees of separation:-
Data Access layer
This consists of a one or more DML objects which issue the functions to communicate with the physical database(s). There is a separate DML class for each database engine (MySQL, PostgreSQL, Oracle). This is sometimes referred to as a Data Access Object (DAO).
Not only is it possible within the same transaction to access tables in different databases, it is also possible to access tables through different database engines.
This layer also communicates my AUDIT class in order to record all changes made to an application database in a separate 'audit' database so that they can be reviewed using online enquiry screens.
Business layer
This contains a separate table class for each database table or business entity. Each table class is a subclass of a generic table class so that it can inherit as much generic code as possible.
All communication with the physical database is handled by the generic table class through a separate DML class.
Primary data validation is handled by the generic table class through a validation class. Secondary data validation is performed by customised functions within each table class.
This layer also communicates my Workflow Engine in order to determine if a new workflow case needs to be created, and to progress each case through its various stages.
Presentation layer
This contains a separate component script for each transaction or task within the system. This is a simple mechanism which identifies which model, view and controller components to use.
There is a screen structure script (the 'view' component) which identifies which XSL stylesheet to use for the HTML output, and a list of field names with their associated labels.
There is a transaction pattern script (the 'controller' component) which deals with the request (input) and generates the response (output). It does this by communicating with one or more table objects in the business layer. The data from these objects is written out to an XML file which is then converted into HTML output by an XSL transformation process.
The XML file is generated automatically by the transaction pattern script. It will contain the data obtained by the table classes as well as any other data required by that component.
The XSL stylesheet contains the commands which will transform the XML input into HTML output during the XSL transformation process. This will usually be one of the generic stylesheets, although it is possible to create a custom stylesheet for particular circumstances.
The XSL transformation process takes the XML input and transforms it into HTML output using the rules defined within the XSL stylesheet. This is a standard process built into the language.
The HTML output is the text file which is sent back to the client's web browser. This is rendered into a viewable page with the assistance of one or more CSS files.
The CSS files are the recommended way of specifying a standard style in a group of HTML documents.
The Model-View-Controller (MVC) design pattern
It was some time after I had developed this infrastructure that I discovered that it also contained an implementation of the MVC design pattern. This is discussed in more detail in The Model-View-Controller (MVC) Design Pattern for PHP.
Figure 6 - The Model-View-Controller structure
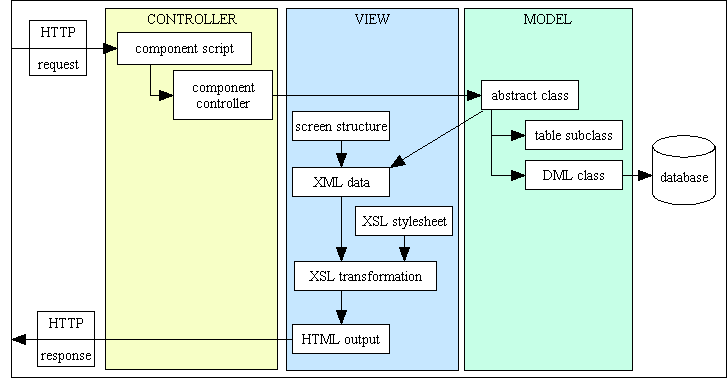
The Model component
A model is an object representing data or even an activity. In my infrastructure this is implemented as a series of table classes, one for each table in the database. All communication with the physical database is routed through a separate DML Object.
The View component
A view is some form of visualisation of the state of the model. In my infrastructure this is implemented as a series of screen structure scripts which are combined with the output from each database table class to produce an XML file which is then transformed into HTML output by using one of the generic XSL stylesheets. For each database table there is typically a list view (containing multiple occurrences with data arranged horizontally) and a detail view (containing a single occurrence with data arranged vertically).
The Controller component
A controller offers facilities to change the state of the model. It accepts input from the user and instructs the model to perform actions based on that input, then updates the view to show the results of those actions.
In my infrastructure this is implemented as a series of component scripts which link to one of a series of transaction pattern (controller) scripts
Infrastructure Design
Some of my approaches to infrastructure design are based on experiences which I have had in previous languages. It is encouraging to know that some of my design decisions as just as valid now as they were then. It just goes to show that quality is ageless.
Forms Families
Some designers have the peculiar notion that the complexity of a system is directly proportional to the number of components it contains, therefore they try to pack as many functions as possible into a single component. In order to maintain the contents of a typical database table it is usual to provide the following functionality:
- The ability to browse through all or selected occurrences (rows).
- The ability to define selection criteria in order to retrieve selected occurrences.
- The ability to create/insert new occurrences.
- The ability to read/enquire the details of existing occurrences.
- The ability to amend/update existing occurrences.
- The ability to delete existing occurrences.
It is possible to put all this functionality into a single component, but the end result is a very large, very complex component. If this approach is duplicated throughout the entire system the end result is a collection of very large, very complex components. In my experience the size of a component is directly proportional to the amount of effort needed to maintain it, so smaller is better.
The alternative approach, one which I first found to be successful when COBOL was my primary language and which was just as successful when I switched to UNIFACE, is to provide each of these facilities in a separate component. This may produce a large number of components, but at least they are small and simple. The arguments for the 'small and simple' approach against the 'large and complex' are explored in more detail in my article Component Design - Large and Complex vs. Small and Simple.
When I read that when designing components for web pages the 'small and simple' approach was preferred over the 'large and complex' this did not pose a problem for me as this has been my design philosophy for 20 years.
Now when I want to write software to maintain the contents of a typical database table I build a 'family' of small components where each one performs just one of the previously mentioned functions. This produces a family of components (sometimes referred to as forms or screens) with the structure shown in Figure 7. Each of these components has its own Transaction Pattern (Controller) script.
Figure 7 - A typical Family of Forms
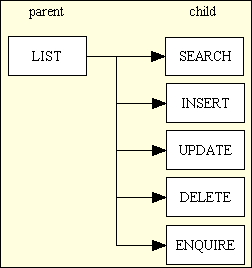
In this structure the LIST (parent) component is the only one that is available on a menu button - all the other child components can only be selected from a navigation button within a suitable parent component. In most cases the child component will need the primary key of an occurrence in the parent component before it can load any data on which it is supposed to act. In this case the required occurrence in the parent screen must be marked as selected using the relevant checkbox before the hyperlink or control button for the child component is pressed.
Another difference between these components is that the LIST component shows multiple rows of details, one occurrence per row, whereas the others will show the details for a single occurrence. As the layout for the SEARCH, INSERT, UPDATE, DELETE and ENQUIRE screens is extremely similar I have managed to provide for their construction with a single XSL file. This means that for each database table I only need 2 XSL files, as shown in Figure 8.
Figure 8 - XSL files required for a family of forms
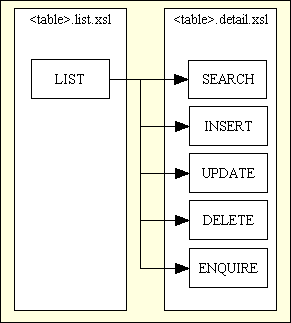
This is made possible as one of the parameters used in the XSL transformation process is $mode. This is used within the XSL stylesheet to determine if each field can be input/amended by the user or should be display only.
In my original infrastructure each database table required its own version of the list.xsl and detail.xsl files as the table, field names and field labels had to be hard-coded inside them, but I have since enhanced my XSL library so that a small number of generic stylesheets can be used for any number of database tables. This is documented in Reusable XSL Stylesheets and Templates and uses updated versions of my std.list1.xsl and std.detail1.xsl stylesheets which allow the table name(s), field names and field labels to be passed in as part of the XML data.
Structure, Behaviour, Content ...
In my long career as a software engineer I have written countless hundreds of components, and many times I have come across the situation where I have been asked to create a new component which is "just like that one, but which works on this set of data". In this situation it is necessary to identify those parts of the original component which can be reused 'as is' and those parts which have to be altered. In order to do this I break down each component into the following areas:
- Structure - how many tables or objects it deals with, arranged in different areas or zones, and how they are arranged in relation to one another.
- Behaviour - what action it performs, such as listing multiple rows, or creating/reading/updating/deleting a single row.
- Content - which database table(s) and field(s) does it deal with.
The trick now is to make different templates or patterns based on a particular combination of structure and behaviour so that when you build a component from a template all you have to do is specify the content. No two languages provide the same method of creating reusable templates, so what works in one particular language may be totally impossible in another. With PHP the method I have devised is to produce scripts in two categories - Screen Structure scripts which identify the content and reusable Transaction Pattern (Controller) scripts which deal with the structure and behaviour.
... and Style
A feature of HTML documents is that the visual presentation of each page can be altered quite easily. By 'visual presentation' I mean any of the following:
- Fonts - different parts of the page can use different fonts of different sizes.
- Colours - different parts of the page can use different foreground and/or background colours.
- Images - background colours can be replaced by background images.
- Positioning - elements of a page may be positioned using either absolute or relative co-ordinates.
Although it is possible to include all style specifications within an HTML document it is not considered to be good practice. The most efficient method is to extract all style specifications and keep them in a separate Cascading Style Sheet (CSS) file or files. In this way it is possible to update the contents of a single CSS file and have that change automatically inherited by all the pages which reference the styles defined within that CSS file. Without the use of a CSS file it would be necessary to update each page individually, which on a large site could be a long and laborious process.
The term 'cascading' means that an HTML document can actually refer to a series of CSS files. These files will be scanned in the order in which they were defined and their contents merged so that a single specification is the result. In my infrastructure I use several CSS files
Infrastructure Implementation
Although this infrastructure appears to be quite complex due to the large number of components, each component is responsible for just a small area and is therefore relatively simple. The trick is to know which components have to be created by the developer, which components have already been written and are available for immediate use, and how they all hang together.
Component scripts
This is item (1) in Figure 5.
Each script in this category simply specifies the Model and View before handing control over to a particular Controller.
Sample scripts for each pattern can be found in the /radicore/default/ directory.
Here is an example of one of my scripts:
<?php $table_id = "person"; // identify the Model $screen = 'person.detail.screen.inc'; // identify the View require 'std.enquire1.inc'; // activate the Controller ?>
As you can see this is a simple script whose purpose is to identify the following:
$table_ididentifies the Model part of MVC. This is one of the generated database table classes.$screenidentifies the View part of MVC. This is one of the generated screen structure scripts.includeidentifies the Controller part of MVC. This is one of the pre-written controller scripts.
Transaction Pattern (Controller) scripts
This is item (2) in Figure 5.
This can also be referred to as a Transaction Controller or a Page Controller.
Each controller script contains the code to perform a particular action on an unspecified database table. For example:
- The LIST1 controller will allow the user to browse the contents of a database table.
- The SEARCH1 controller will allow the user to specify selection criteria which will be used by the LIST transaction to filter its results.
- The ADD1 controller will allow the user to add a record.
- The ENQUIRE1 controller will allow the user to view the contents of a selected record.
- The UPDATE1 controller will allow the user to update the contents of a selected record.
- The DELETE1 controller will allow the user to delete a selected record.
For a full list of my Transaction Patterns please refer to Transaction Patterns for Web Applications.
Each script in this category is based on a particular combination of structure and behaviour. The actual content is identified by the Screen Structure script which is set in the calling Component script. This means that one of these Controller scripts may be called by many different Component scripts, as shown in Figure 9.
Figure 9 - Many Component scripts to one Transaction Pattern (Controller) script
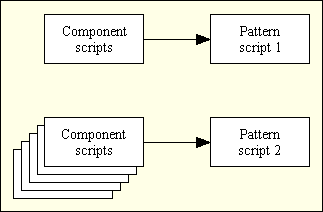
None of these Controller scripts outputs any HTML output directly. What is actually produced is an XML file which is transformed into HTML using a separate XSL stylesheet.
Here is an example of one of my scripts:
<?php // name = std.enquire1.inc // type = enquire1 // This will display a single selected database occurrence using $where // (as supplied from the previous screen) require 'include.inc'; // identify mode for xsl file $mode = 'enquire'; // initialise session initSession(); // look for a button being pressed if ($_SERVER['REQUEST_METHOD'] == 'POST') { if (isset($_POST['finish']) or (isset($_POST['finish_x']))) { // cancel this screen, return to previous screen scriptPrevious(); } // if } // if // create a class instance for the main database table require "classes/$table_id.class.inc"; $dbobject = new $table_id; $dbobject->sql_select = &$sql_select; $dbobject->sql_from = &$sql_from; $dbobject->sql_where = &$sql_where; $dbobject->sql_groupby = &$sql_groupby; $dbobject->sql_having = &$sql_having; // check that primary key is complete $dbobject->checkPrimaryKey = TRUE; // define action buttons $act_buttons['finish'] = 'FINISH'; // retrieve profile must have been set by previous screen if (empty($where)) { scriptPrevious('Nothing has been selected yet.'); } // if // get data from the database $fieldarray = $dbobject->getData($where); if ($dbobject->getErrors()) { // some sort of error - return to previous script scriptPrevious($dbobject->getErrors()); } // if // check number of rows returned if ($dbobject->getNumRows() < 1) { scriptPrevious('Nothing retrieved from the database.'); } // if // use contents of first row only $fieldarray = $fieldarray[0]; // rebuild selection using primary key of retrieved row $where = array2where($fieldarray, $dbobject->getPkey()); // get any extra data and merge with $fieldarray $fieldarray = array_merge($fieldarray, $dbobject->getExtraData($fieldarray)); // build list of objects for output to XML data $xml_objects[]['root'] = &$dbobject; // build XML document and perform XSL transformation buildXML($xml_objects, $errors, $message); ?>
Please note the following points:
- All files containing classes for database tables are in the format '<table_id>.class.inc', so all the Component script need do is supply a value for
$table_idand the Controller script can create an object from that class. - By setting the object variable
checkPrimaryKeyto TRUE I will trigger the code to check that the$wherestring contains values for all fields which make up the primary key for this database table. The primary key details are specified in the $fieldspec array. - Each database table class contains a standard
getDatamethod which returns the$fieldarrayarray of rows (starting at row zero), and each row contains an associative array offieldname=fieldvaluepairs. - By default the
getDatamethod will select all columns from the specified table, but this can be altered to specify any number of columns from any number of tables by settings in the$sql_???variables. - The entire contents of
$fieldarraywill be output to the XML file. Note that no field names need be specified in the script as they are all extracted from$fieldarray. - The $fieldspec array from the database object may contain entries which will be included in the XML output as attributes in order to affect the outcome of the XSL transformation. For example
noeditwill cause a field to be read-only, whilenodisplaywill cause the field to be excluded from the HTML output altogether.
Here is a brief explanation of my user-defined functions which are contained within file include.inc:
initSession()- carries out all processing required when a script starts. This includes reading the session data to obtain the contents of the variable$wherewhich contains any selection criteria passed down from the previous script.scriptPrevious()- will return processing to the previous script with an optional error message. Note that this is not the same as pressing the browser'sbackbutton.array2where()- transforms an associative array into a string which can be used as the WHERE clause in an SQL SELECT statement. The first parameter is the array, the optional second parameter identifies the subset of fields to be included.buildXML()- takes the$xml_objectsarray and transfers all the data to an XML file, after which it will perform the XSL Transformation process using the specified XSL stylesheet to produce the HTML output.
You should notice that the above script does not contain any hard-coded database, table or field names, therefore it can be used for any database table within the system. The points to consider are:
- The name of the table to work on is passed down in the
$tablevariable which is set by the component script. - That variable name is used to obtain a class definition from an 'include' file, and an object is instantiated from that class with a generic name, which in this case is
$object. - The controller communicates with the object using standard method names which are common to all objects as they are inherited from the generic table class.
- The data which comes out of the object is a standard associative array of
fieldname=fieldvaluepairs. This is processed by a standard function which simply copies the entire array out to the XML file in an equivalentfieldname=fieldvalueformat.
I have some controller scripts which work on more than one database object, such as when dealing with a parent-child relationship or a many-to-many relationship, but the principles are exactly the same.
Generic (abstract) table class
This is item (4) in Figure 5.
This is an abstract class which is based on the ideas outlined in Using PHP Objects to access your Database Tables (Part 1) and (Part 2). It is called an 'abstract' class as it does not contain any implementation details and therefore cannot be instantiated into an object. Implementation details for each physical database table are supplied in separate subclasses, and it is only these subclasses that can be instantiated into objects.
This abstract database class contains generic methods and properties which can be used by any database table in the system. These methods and properties are automatically inherited by every subclass. Code which is specific to any particular table must be built into in the subclass for that particular table.
This generic class also contains the following:
- It contains the standard methods and properties which are accessed by the Transaction Pattern (Controller) scripts. Amongst these are:
- getData ($where) - will retrieve any number of records from the database using the specified WHERE criteria. The sql SELECT statement will be constructed automatically from variables supplied at runtime. The result is an associative array of 'name=value' pairs, indexed by row number.
- insertRecord ($fieldarray) - will insert a single row using the contents of
$fieldarray, which is an associative array of 'name=value' pairs. The sql INSERT statement will be constructed automatically from the contents of$fieldarray. - updateRecord ($fieldarray) - will update a single row using the contents of
$fieldarray, which is an associative array of 'name=value' pairs. The sql UPDATE statement will be constructed automatically from the contents of$fieldarray. - deleteRecord ($fieldarray) - will delete a single row using the contents of
$fieldarray, which is an associative array of 'name=value' pairs. The sql DELETE statement will be constructed automatically from the contents of$fieldarray.
- It passes the input array (usually the
$_POSTarray) to the validation class for all input and update operations. Error messages are returned in the$errorsarray - When actions on the physical database are required these are passed to the DML class for processing.
- During a delete operation it will use the contents of the $child_relations array to check that the record can be deleted and to update/delete all records from child tables if necessary.
- It also contains a series of empty methods which are accessed in set places within the processing cycle. These can be replaced in a subclass with versions that contains custom code, and at runtime the customised method in the subclass will be executed instead of the empty method in the superclass.
Database Table (Model) classes
This is item (3) in Figure 5.
Each database table (or business entity) is represented by its own class which extends (is a subclass of) the generic table class.
Although each table subclass will inherit all the generic code from the superclass, in order to be usable it must also contain information which is specific to the database table to which it relates. This information is as follows:
- class constructor - this defines the basic settings for the table such as:
- database name
- table name
- The $fieldspec, $unique_keys, $parent_relations and $child_relations arrays (see below)
- $fieldspec array - this identifies each field (column) in the table, and for each field it describes its characteristics (type, size, et cetera) so that primary validation can be performed via the validation class when inserting or updating records. This array also contains information which is used by the XSL transformation process to identify what control (text box, dropdown list, radio group, etc) should be used for each field in the HTML output.
- $primary_key array - used to define the field(s) which provide the primary means of uniquely identifying each record in a table. Most databases do not allow primary keys to be changed, so they must be validated during insert only.
- $unique_keys array - used to enable the validation of candidate keys (optional unique keys in addition to the primary key). Unlike the primary key a candidate key can be changed, so it must be validated during both insert and update.
- $parent_relations array - this identifies any parent tables which are related to this table in a parent-child (one-to-many) relationship. This is used when any data from the parent table needs to be added to the query result. The framework is capable of adding in the necessary JOIN clause when the query is constructed.
- $child_relations array - this identifies any child tables which are related to this table in a parent-child (one-to-many) relationship. This is used when any record is deleted to enforce basic referential integrity.
- custom processing - within the generic table class are a series of abstract methods which exist in the processing flow but which are empty of any code. Versions containing custom code can be created in each subclass which at runtime will replace the empty abstract methods in the superclass. These abstract methods provide the ability to perform custom processing at predetermined places in the standard processing flow or to carry out secondary data validation which cannot be performed by the generic validation class.
Note that this class can deal with any number of database rows - I do not have one version to deal with a single row and a second version to deal with a collection of rows.
The class file for each database table does not have to be generated by hand - with the introduction of A Data Dictionary for PHP Applications it is possible to import the table structures directly from the database schema into the data dictionary, then to export those structures into files which can be accessed directly by the application code.
Validation class
This is item (5) in Figure 5.
The generic validation class handles primary validation (sometimes referred to as declarative checking) of all user input. It compares the contents of the input array with the contents of the $fieldspec array to check that the input data for each field conforms to that field's specifications. It puts any error messages in the current object's $errors array.
The input array (usually the $_POST array) is an array of fieldname=fieldvalue pairs.
The $fieldspec array is an array of fieldname=fieldspec pairs. The fieldspec portion is another associative array of keyword=value pairs.
The $errors array is an array of fieldname=errormsg pairs. It can therefore contain error messages for any number of fields.
Primary validation is limited to the following checks:
- That all required fields have a non-null value.
- That fields do not exceed their maximum size.
- That date fields contain valid dates.
- That time fields contain valid times.
- That numeric fields contain valid numbers, with options for minimum/maximum values and number of decimal places.
- A string field may have an optional subtype of
email_addresswhich causes the string to be checked against the relevant pattern. - A string field may have an optional subtype of
filewhich causes a check to ensure that a file with that name exists.
Secondary validation, such as comparing one field against another, must be defined within the individual table subclass using the empty classes provided in the superclass.
It is also possible to supplement the generic validation with the addition of plug-ins, as described in Extending the Validation class.
DML class
This is item (6) in Figure 5.
This is the only object in the system which carries out any communication with the physical database. It receives requests from the Generic Table class from which it generates the appropriate DML (Data Manipulation Language) or SQL (Structured Query Language) commands. It then executes these commands by calling the relevant API for the database in question.
As this object exists in the Data Access layer it is sometimes referred to as the Data Access Object (DAO).
There is a separate class for each database engine as each engine has its own set of APIs. This design also allows me to isolate and deal with any differences between the various engines. The name of the class file is in the format dml.???.class.inc where '???' can be mysql, postgresql, oracle or whatever. A default value for $dbms_engine is defined within the Generic Table class although this can be overridden in any individual table subclass. At runtime a DML object is instantiated from the relevant DML class according to the value in $dbms_engine. This means that it is possible to switch from one database engine to another simply by changing the value in $dbms_engine either globally for all tables or locally for individual tables.
This class is based on the ideas outlined in Using PHP Objects to access your Database Tables (Part 1) and (Part 2). Some of the methods it contains are as follows:
- getData ($dbname, $tablename, $where) - will retrieve any number of records from the database using a SELECT statement which is constructed as required. The result is an associative array of 'name=value' pairs indexed by row number. There are pagination options which break down large volumes of data into separate pages for display purposes.
- insertRecord ($dbname, $tablename, $fieldarray) - will insert a single row using the contents of
$fieldarray(usually the$_POSTarray). A check is made before the INSERT to ensure that the primary key and any candidate keys are currently unused. - updateRecord ($dbname, $tablename, $newarray, $oldarray) - will update a single row using the contents of
$newarray(usually the$_POSTarray). This is first compared with$oldarray(the current database values) so that only those fields which have changed are included in the DML statement. The identity of the primary key for use in the WHERE clause is extracted using the contents of the$fieldspecarray. If any candidate key has changed it is first checked for uniqueness. - deleteRecord ($dbname, $tablename, $fieldarray) - will delete a single row using the contents of
$fieldarray. The identity of the primary key for use in the WHERE clause is extracted using the contents of the$fieldspecarray.
Note that within a single transaction it is possible to access tables in more than one database and through more than one database engine.
Screen Structure (View) scripts
This is item (7) in Figure 5.
These are simple scripts which do nothing but identify the view or content for the output screen. Each one identifies the name of an XSL stylesheet and a list of table names, field names and field labels that will be used during the XSL transformation process to produce the HTML output.
Sample scripts for each pattern can be found in the /radicore/default/screens/en/ directory with the name <pattern>.screen.inc.
Scripts for each subsystem can be found in the /radicore/<subsystem>/screens/<language>/ directory. The default value for <language> is 'en' (English), but other language codes can be used - refer to Internationalisation and the Radicore Development Infrastructure for details.
Although the parent LIST screen in Figure 7 will require its own Screen Structure file, all the CHILD screens can share the same one as they all use the same structure. The differences in how the fields are displayed for each of the child components is handled by a combination of the $mode parameter within the Transaction Pattern (Controller) script (insert, update, delete, enquire) and individual field attributes within the XML file. These attributes can be specified within the $fieldspec array for that table class, or can be supplied at runtime through custom code.
Here is a sample file:
<?php // this identifies which XSL stylesheet to use $structure['xsl_file'] = 'std.detail1.xsl'; // this identifies which XML data is to go into which XSL zone $structure['tables']['main'] = 'person'; // this specifies the width of each column $structure['main']['columns'][] = array('width' => 150); $structure['main']['columns'][] = array('width' => '*'); // the following may also be used $structure['main']['columns'][] = array('class' => 'classname'); // this identifies the label and field which is to be displayed in each row $structure['main']['fields'][] = array('person_id' => 'ID'); $structure['main']['fields'][] = array('first_name' => 'First Name'); $structure['main']['fields'][] = array('last_name' => 'Last Name'); $structure['main']['fields'][] = array('initials' => 'Initials'); $structure['main']['fields'][] = array('nat_ins_no' => 'Nat. Ins. No.'); $structure['main']['fields'][] = array('pers_type_id' => 'Person Type'); $structure['main']['fields'][] = array('star_sign' => 'Star Sign'); $structure['main']['fields'][] = array('email_addr' => 'E-mail'); $structure['main']['fields'][] = array('value1' => 'Value 1'); $structure['main']['fields'][] = array('value2' => 'Value 2'); $structure['main']['fields'][] = array('start_date' => 'Start Date'); $structure['main']['fields'][] = array('end_date' => 'End Date'); $structure['main']['fields'][] = array('selected' => 'Selected'); ?>
In this example there is a single data zone called main which is linked with an object called person. Some screens have two or more zones which are linked to different objects. At runtime the fields will be extracted from each object and displayed in the relevant zone. Note that a field must exist both within the object and within the screen structure file in order for it to be dislayed.
The name of this file is provided by the Component script in the $screen variable. It is read in by the Transaction Pattern (Controller) script and its contents are added to the XML file to appear something like this:
<root>
......
<structure>
<main id="person">
<columns>
<column width="150"/>
<column width="*"/>
</columns>
<row>
<cell label="ID"/>
<cell field="person_id" />
</row>
<row>
<cell label="First Name"/>
<cell field="first_name"/>
</row>
<row>
<cell label="Last Name"/>
<cell field="last_name"/>
</row>
<row>
<cell label="Initials"/>
<cell field="initials"/>
</row>
....
<row>
<cell label="Start Date"/>
<cell field="start_date"/>
</row>
<row>
<cell label="End Date"/>
<cell field="end_date"/>
</row>
</main>
</structure>
</root>
Several different layouts are now available for displaying user data. For more details on how these can be specified please refer to XSL Structure files in The Model-View-Controller (MVC) Design Pattern for PHP.
XML files
This is item (8) in Figure 5.
XML (Extensible Markup Language) is a simple but flexible text format. It is based on an open standard which is maintained by the World Wide Web Consortium. It is used in this infrastructure to provide the XSL transformation process with all the data it needs to produce the HTML output.
The XML file is generated automatically at runtime by the Transaction Pattern (Controller) script. The technique which is used to create this file in PHP 4 is described in Using PHP 4's DOM XML functions to create XML files from SQL data. For PHP 5 refer to Using PHP 5's DOM functions to create XML files from SQL data instead.
Each XML file can contain any of the following data:
- Values from any number of database table objects. These will use the table names and field names obtained from the database.
- Each field may also have attributes which indicate how the field should be displayed, or to hold an error message.
- A list of table names, field names and field labels obtained from the Screen Structure script. For forms of type LIST this will also provide the column headings.
- Data to construct the Menu bar.
- Data to construct the Navigation bar.
- Data to construct the Pagination or Scrolling areas.
- Data for the Action bar.
- Data for the Message area.
- Data for any lookup (picklist) fields such as dropdown lists or radio groups.
XSL Stylesheets
This is item (9) in Figure 5.
Each component requires an XSL stylesheet in order to transform the data in the XML file into HTML output. In an earlier version of this infrastructure I used different stylesheets for each database table which had the table names, field names and field labels all hard-coded, but I have subsequently found a way to use a smaller number of generic stylesheets. Instead of having the field details hard-coded within the stylesheet I am now able to extract that information from within the XML file using information supplied in a Screen Structure script. This is is documented in Reusable XSL Stylesheets and Templates.
Although my whole web application uses fewer than ten generic stylesheets there is still some code which is needed in more than one stylesheet. This code has been extracted and placed in a library of XSL templates which can be incorporated into any stylesheet at runtime by means of an <xsl:include> command. This is, in effect, a library of standard XSL subroutines.
Using the components in Figure 7 as an example I would use a generic LIST stylesheet for the parent component and a generic DETAIL stylesheet for all the child components. Variations in how the individual fields are displayed within the various child components is handled primarily by the $mode variable which is passed as a parameter during the XSL transformation process. This is used as follows:
- If
$mode= 'input' or 'search' then all fields are editable. - If
$mode= 'read' or 'delete' then all fields are non-editable. - if
$mode= 'update' then primary key fields are non-editable. - If
$mode= 'search' then any boolean fields are given a third option to emulate a tri-state checkbox (yes, no, undefined).
In addition to the $mode parameter the handling of individual fields can be affected by specific attributes in the XML file. These can either be set into the $fieldspec array or altered at runtime using custom code.
- The
noeditattribute will make the field non-editable. - The
nodisplayattribute will make the field invisible.
The type of HTML control (textbox, dropdown, radio group, etc) to be used for each field in the HTML output is completely dynamic in nature. This is a 3 stage process:
- The default HTML control is initially defined within the $fieldspec array, but this can be changed at runtime with custom code.
- As the contents of each database object is written out to the XML file by the Transaction Pattern (Controller) script various details from the $fieldspec array are included with each field as XML attributes.
- During the XSL transformation process a standard XSL template will use the field attributes to build the HTML control to the supplied specifications.
XSL Transformation process
This is item (10) in Figure 5.
This process will take the contents of an XML document and transform it to another document (in this case an HTML document) using rules contained within an XSL stylesheet. These are all open standards which are supervised by the World Wide Web Consortium.
It is possible to send both the XML and XSL files to the client and have the transformation performed within the client's browser (client-side transformation), but this is unreliable due to the different levels (sometimes non-existent) of XML/XSL support in different browsers. It is much safer to perform the transformation in a single place (the web server) where the software is under the control of the web developer. This is known as a server-side transformation.
The technique which I use to perform XSL transformations in PHP 4 is described in Using PHP 4's Sablotron extension to perform XSL Transformations. For PHP 5 refer to Using PHP 5's XSL extension to perform XSL Transformations instead.
HTML output
This is item (11) in Figure 5.
This is the document which is sent back to the client's browser is response to the request. Its content should conform to the (X)HTML specification which is supervised by the World Wide Web Consortium.
In an effort to make my output viewable on as many web browsers as possible I stick to the following guidelines:
- All output is XHTML 1.0 Strict which is structurally clean and free of any style details. All style specifications (fonts, colours and layout) are held within separate CSS files.
- There is no javascript (some users have javascript disabled).
- There are no third party controls or plugins (ActiveX or Flash).
- There are no proprietary extensions.
HTML documents can be validated by the W3C Markup Validation Service.
CSS files
This is item (12) in Figure 5.
These are Cascading Style Sheets which hold all the styling information (fonts, colours, sizes, positioning, etc) for all HTML documents produced by the application. The tags within each HTML document refer to a style by a class name, and the specifications for each of these classes is held within a CSS file. In this way it becomes possible to change the style specifications for any tag in all documents simply by changing the specifications within a single CSS file.
The following CSS files are available:
- global - a selection of files exist within the CSS subdirectory which set the style for the entire application. It is possible to choose any one of these using the style/theme option in the Update Session data screen. Additional CSS files may be created and copied into this subdirectory, in which case they will automatically become available for selection.
- local - if it is required to change the global setting for a CSS element, or to create a new CSS element within a single subsystem, then instead of creating a complete global CSS file it is possible to insert these local modifications into a local CSS file called 'style_custom.css', which exists in every subdirectory. When the HTML document is rendered it will use the contents of both the global and local CSS files. If any setting exists in both files then the local setting will override the global setting.
CSS files can be validated using the W3C CSS Validation Service.
AUDIT class
This is item (13) in Figure 5.
This class is responsible for detecting all database changes (INSERTs, UPDATEs and DELETEs) and recording them in a separate 'audit' database so that they can be reviewed using online enquiry screens. This is documented in Creating an Audit Log with an online viewing facility.
The only additional code required in any database table class is the setting of a class variable called $audit_logging. By default this is TRUE (the table will be logged) but it can be set to FALSE to disable logging.
Workflow Engine
This is item (14) in Figure 5.
Sometimes when a particular task is performed, such as 'Take Customer Order', this has to be followed by a series of other tasks such as 'Charge Customer', 'Pack Order' and 'Ship Order'. Without a Workflow Engine these subsequent tasks must be processed manually, which is where mistakes and inefficiencies can arise.
The purpose of a Workflow System is to manage these tasks in a controlled fashion. This system should have the following components:
- A method whereby different Workflow processes can be defined. This must identify the triggering task and the sequence of subsequent tasks.
- A mechanism which automatically creates a new workflow case when a triggering task is processed, then progresses that case through its various stages.
- A method whereby outstanding tasks (workitems) in workflow cases which require human intervention appear in a list which prompts the relevant users that intervention is required. A task should be activated simply by clicking on its entry in this list.
- A method whereby the status of any individual workflow case can be reviewed.
The Workflow Engine which I have created as an extension to this development infrastructure is documented in An activity based Workflow Engine for PHP. The engine is activated from within my generic table class therefore no additional programmer coding is required.
Levels of Reusability
The single aspect of any development infrastructure which enables Rapid Application Development (RAD) is the volume of reusable code that it contains. Reusable code in the form of a library of standard modules provides the following advantages:
- The library modules contain code which has already been written to provide certain functionality, therefore it is not necessary to waste more time in writing more code to provide the same functionality.
- The library modules contain code which has already been tested, therefore this cuts down the testing phase of new components which use these modules.
- By using standard library modules for standard tasks the developer does not have to waste time in reinventing the wheel (and possibly creating a square wheel).
- By using standard code to provide certain functionality it means that the same functionality will be provided in a consistent manner across multiple components. This will be less confusing to the user.
- By using standard library modules it becomes possible to make a change in a single module and have that change immediately incorporated into every component that references that module.
Although the infrastructure described within this document contains a large number of components it should be pointed out that the majority of them do not require any additional effort on the part of the developer. These are:
- Transaction Pattern (Controller) scripts
- Generic table class
- Validation class
- DML class
- XSL Stylesheets
- XSL Transformation process (server-side, built into PHP, or client-side if supported by the client browser)
- CSS files
- Audit logging
- Workflow Engine
The following components are generated automatically at runtime and do not require any programmer effort:
This leaves the following components for the developer to work on:
- Database Table (Model) classes (can be reused by any component which needs to access that database table).
- Screen Structure (View) scripts (the scripts for 'detail' screens can be used by the SEARCH, INSERT, UPDATE, DELETE and ENQUIRE components for that database table).
- Component scripts (cannot be reused because each one is unique).
An idea of the amount of reusability can be shown in figure 10:
Figure 10 - Levels of Reusability
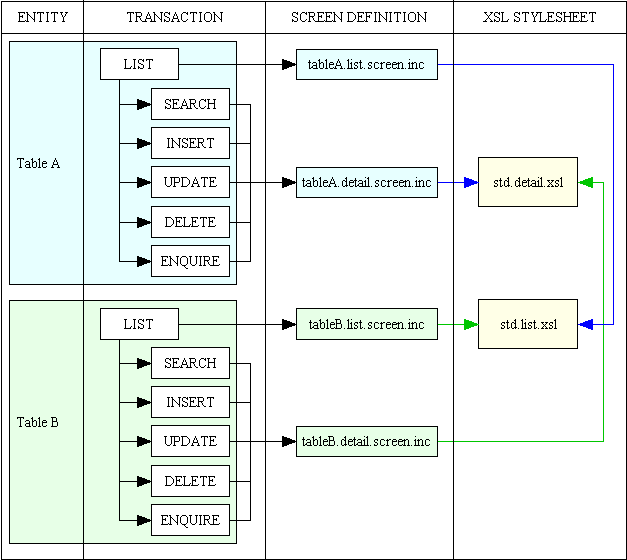
This shows the following:
- A business entity requires one database table class which is shared by six transactions.
- Five of these transactions share the same screen definition.
- All LIST transactions share the same LIST controller scripts, all INSERT transactions share the same INERT controller scripts, etc.
- All LIST screens share the same list.xsl stylesheet.
- All DETAIL (search, insert, update, delete and enquire) screens share the same detail.xsl stylesheet.
I have spent 20+ years working for software houses where the task has been to develop many different applications for many different customers in a swift and cost-effective manner. To be truly reusable an infrastructure should not only work for different components within the same application but for different applications entirely. This offers two advantages:
- It avoids the necessity of constructing a new infrastructure for each new application.
- It avoids the non-productive time in learning a new infrastructure when developers switch from one application to another.
I have witnessed at first hand the advantages of being able to use such infrastructures as I have used them with two entirely different languages - COBOL and UNIFACE. As I was personally responsible for creating those two infrastructures I had all the relevant experience to create a new one in PHP.
Extending this Infrastructure
Having an infrastructure with which you can build applications is one thing, but in my long experience I have also found it useful to build utility components which may be of benefit to those applications. This type of component is not specific to any particular application, but may be used in conjunction with any number of different applications. Amongst those I have built are:
- A Role Based Access Control (RBAC) system (also known as a Menu and Security system) which can act as the front end for any application. It allows tasks to be defined in a hierarchy of menus and allows user access to individual tasks to be granted or denied to individual user roles. This is documented in:
- An audit facility which records all changes made to application databases in a separate 'audit' database so that they may be reviewed using online enquiry screens. This is documented in:
- An activity based Workflow Engine for PHP which is built around Petri Nets. This allows workflow processes to be defined, creates workflow cases when the triggering event is fired, and adds workitems to user menu screens. This is documented in:
- A Data Dictionary which allows details of an application database to be imported, modified and exported for use in PHP scripts, thus saving the need to create these details by hand. This is documented in:
- The capability to allow program-generated text (error messages, screen titles, field labels, button text, etc) to be displayed in more than one language. This is documented in:
References
- Using PHP Objects to access your Database Tables (Part 1)
- Using PHP Objects to access your Database Tables (Part 2)
- What is/is not considered to be good OO programming
- In the world of OOP am I Hero or Heretic?
- Generating dynamic web pages using XSL and XML
- Reusable XSL Stylesheets and Templates
- Using PHP 4's DOM XML functions to create XML files from SQL data
- Using PHP 4's Sablotron extension to perform XSL Transformations
- Using PHP 5's DOM functions to create XML files from SQL data
- Using PHP 5's XSL functions to perform XSL Transformations
- Transaction Patterns for Web Applications
- UML diagrams for the Radicore Development Infrastructure
- Customising the PHP error handler
- Component Design - Large and Complex vs. Small and Simple
- A Sample PHP Application
- The Model-View-Controller (MVC) Design Pattern for PHP
- FAQ on the Radicore Development Infrastructure
- A Role-Based Access Control (RBAC) system for PHP
- User Guide to the Menu and Security (RBAC) System
- Creating an Audit Log with an online viewing facility
- An activity based Workflow Engine for PHP
- A Data Dictionary for PHP Applications
- Internationalisation and the Radicore Development Infrastructure
© Tony Marston
2nd August 2003
http://www.tonymarston.net
http://www.radicore.org
| 15 July 2005 | Added a reference to a new article entitled Internationalisation and the Radicore Development Infrastructure. |
| 21 June 2005 | Amended Screen Structure (View) scripts to show the new layouts caused by the provision of more flexible options. |
| 17 June 2005 | Added a reference to a new article entitled A Data Dictionary for PHP Applications. |
| 16 Sep 2004 | Added a reference to a new article entitled An activity based Workflow Engine for PHP. |
| 10 Sep 2004 | Added section Extending this Infrastructure. |
| 10 Aug 2004 | Added better descriptions for the individual components. Moved all the Frequently Asked Questions to a separate document. |
| 03 June 2004 | Added a section on Style which explains the advantages of using Cascading Style Sheets. |
| 02 May 2004 | Added a reference to The Model-View-Controller (MVC) Design Pattern for PHP. |
| 28 Apr 2004 | Added a reference to Reusable XSL Stylesheets and Templates which describes a method which enables me to use a single generic stylesheet for many database tables instead of having a customised stylesheet for each individual database table. |
| 10 Nov 2003 | Created a sample application to demonstrate the techniques described in this document. This is described in A Sample PHP Application. The code can be run on my website here, or can be downloaded here and run locally. |
| 08 Sep 2003 | Split my abstract database class again so that the code which performs generic validation (declarative checks) is now contained within its own class. Refer to Business layer for details. |
| 31 Aug 2003 | Split my abstract database class into two so that the construction and execution of all DML statements is now contained within its own class. Refer to Data Access layer for details. |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









