







概要
学完了Map的全部内容,我们再回头开开Map的框架图。
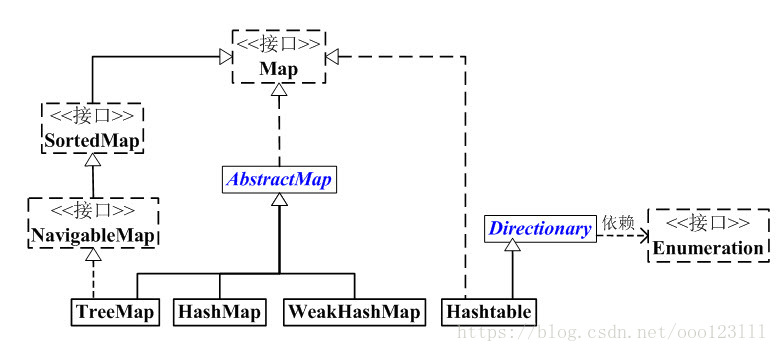
1、Map概括
(01) Map 是“键值对”映射的抽象接口。
(02) AbstractMap 实现了Map中的绝大部分函数接口。它减少了“Map的实现类”的重复编码。
(03) SortedMap 有序的“键值对”映射接口。
(04) NavigableMap 是继承于SortedMap的,支持导航函数的接口。
(05) HashMap, Hashtable, TreeMap, WeakHashMap这4个类是“键值对”映射的实现类。它们各有区别!
- HashMap 是基于“拉链法”实现的散列表。一般用于单线程程序中。
- Hashtable 也是基于“拉链法”实现的散列表。它一般用于多线程程序中。
- WeakHashMap也是基于“拉链法”实现的散列表,它一般也用于单线程程序中。相比HashMap,WeakHashMap中的键是“弱键”,当“弱键”被GC回收时,它对应的键值对也会被从WeakHashMap中删除;而HashMap中的键是强键。
- TreeMap 是有序的散列表,它是通过红黑树实现的。它一般用于单线程中存储有序的映射。
2、HashMap和Hashtable异同
2.1HashMap和Hashtable的相同点
HashMap和Hashtable都是存储“键值对(key-value)”的散列表,而且都是采用拉链法实现的。
存储的思想都是:通过table数组存储,数组的每一个元素都是一个Entry;而一个Entry就是一个单向链表,Entry链表中的每一个节点就保存了key-value键值对数据。
添加key-value键值对:首先,根据key值计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据数组索引找到Entry(即,单向链表),再遍历单向链表,将key和链表中的每一个节点的key进行对比。若key已经存在Entry链表中,则用该value值取代旧的value值;若key不存在Entry链表中,则新建一个key-value节点,并将该节点插入Entry链表的表头位置。
删除key-value键值对:删除键值对,相比于“添加键值对”来说,简单很多。首先,还是根据key计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据索引找出Entry(即,单向链表)。若节点key-value存在与链表Entry中,则删除链表中的节点即可。
上面介绍了HashMap和Hashtable的相同点。正是由于它们都是散列表,我们关注更多的是“它们的区别,以及它们分别适合在什么情况下使用”。那接下来,我们先看看它们的区别。
2.2HashMap和Hashtable的不同点
2.2.1 继承和实现方式不同
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
HashMap的定义:
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable { ... }Hashtable的定义:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable { ... }从中,我们可以看出:
- HashMap和Hashtable都实现了Map、Cloneable、java.io.Serializable接口。
- 实现了Map接口,意味着它们都支持key-value键值对操作。支持“添加key-value键值对”、“获取key”、“获取value”、“获取map大小”、“清空map”等基本的key-value键值对操作。
- 实现了Cloneable接口,意味着它能被克隆。
实现了java.io.Serializable接口,意味着它们支持序列化,能通过序列化去传输。
HashMap继承于AbstractMap,而Hashtable继承于Dictionary
- Dictionary是一个抽象类,它直接继承于Object类,没有实现任何接口。Dictionary类是JDK 1.0的引入的。虽然Dictionary也支持“添加key-value键值对”、“获取value”、“获取大小”等基本操作,但它的API函数比Map少;而且Dictionary一般是通过Enumeration(枚举类)去遍历,Map则是通过Iterator(迭代器)去遍历。然而‘由于Hashtable也实现了Map接口,所以,它即支持Enumeration遍历,也支持Iterator遍历。关于这点,后面还会进一步说明。
- AbstractMap是一个抽象类,它实现了Map接口的绝大部分API函数;为Map的具体实现类提供了极大的便利。它是JDK 1.2新增的类。
2.2.2 线程安全不同
- Hashtable的几乎所有函数都是同步的,即它是线程安全的,支持多线程。
而HashMap的函数则是非同步的,它不是线程安全的。若要在多线程中使用HashMap,需要我们额外的进行同步处理。对HashMap的同步处理可以使用Collections类提供的synchronizedMap静态方法,或者直接使用JDK5.0之后提供的java.util.concurrent包里的ConcurrentHashMap类。
2.2.3 对null值的处理不同
HashMap的key、value都可以为null。
Hashtable的key、value都不可以为null。
我们先看看HashMap和Hashtable “添加key-value”的方法
HashMap的添加key-value的方法
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
addEntry(hash, key, value, i);
return null;
}
// putForNullKey()的作用是将“key为null”键值对添加到table[0]位置
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
// recordAccess()函数什么也没有做
e.recordAccess(this);
return oldValue;
}
}
// 添加第1个“key为null”的元素都table中的时候,会执行到这里。
// 它的作用是将“设置table[0]的key为null,值为value”。
modCount++;
addEntry(0, null, value, 0);
return null;
}Hashtable的添加key-value的方法
// 将“key-value”添加到Hashtable中
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
}
// 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
// Hashtable中不能插入key为null的元素!!!
// 否则,下面的语句会抛出异常!
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若“Hashtable中不存在键为key的键值对”,
// (01) 将“修改统计数”+1
modCount++;
// (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// (03) 将“Hashtable中index”位置的Entry(链表)保存到e中 Entry<K,V> e = tab[index];
// (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。
tab[index] = new Entry<K,V>(hash, key, value, e);
// (05) 将“Hashtable的实际容量”+1
count++;
return null;
}根据上面的代码,我们可以看出:
- Hashtable的key或value,都不能为null!否则,会抛出异常NullPointerException。
- HashMap的key、value都可以为null。 当HashMap的key为null时,HashMap会将其固定的插入table[0]位置(即HashMap散列表的第一个位置);而且table[0]处只会容纳一个key为null的值,当有多个key为null的值插入的时候,table[0]会保留最后插入的value。
2.2.4 支持的遍历种类不同
- HashMap只支持Iterator(迭代器)遍历。
而Hashtable支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历。
Enumeration 是JDK 1.0添加的接口,只有hasMoreElements(), nextElement() 两个API接口,不能通过Enumeration()对元素进行修改 。
- 而Iterator 是JDK 1.2才添加的接口,支持hasNext(), next(), remove() 三个API接口。HashMap也是JDK 1.2版本才添加的,所以用Iterator取代Enumeration,HashMap只支持Iterator遍历。
2.2.5 通过Iterator迭代器遍历时,遍历的顺序不同
HashMap是“从前向后”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
Hashtabl是“从后往前”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
HashMap和Hashtable都实现Map接口,所以支持获取它们“key的集合”、“value的集合”、“key-value的集合”,然后通过Iterator对这些集合进行遍历。
由于“key的集合”、“value的集合”、“key-value的集合”的遍历原理都是一样的;下面,我以遍历“key-value的集合”来进行说明。
HashMap 和Hashtable 遍历”key-value集合”的方式是:
(01) 通过entrySet()获取“Map.Entry集合”。
(02) 通过iterator()获取“Map.Entry集合”的迭代器,再进行遍历。
HashMap的实现方式:先“从前向后”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
// 返回“HashMap的Entry集合”
public Set<Map.Entry<K,V>> entrySet() {
return entrySet0();
}
// 返回“HashMap的Entry集合”,它实际是返回一个EntrySet对象
private Set<Map.Entry<K,V>> entrySet0() {
Set<Map.Entry<K,V>> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
// EntrySet对应的集合
// EntrySet继承于AbstractSet,说明该集合中没有重复的EntrySet。
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
...
public Iterator<Map.Entry<K,V>> iterator() {
return newEntryIterator();
}
...
}
// 返回一个“entry迭代器”
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
// Entry的迭代器
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
private abstract class HashIterator<E> implements Iterator<E> {
// 下一个元素
Entry<K,V> next;
// expectedModCount用于实现fail-fast机制。
int expectedModCount;
// 当前索引
int index;
// 当前元素
Entry<K,V> current;
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
// 将next指向table中第一个不为null的元素。
// 这里利用了index的初始值为0,从0开始依次向后遍历,直到找到不为null的元素就退出循环。
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
// 获取下一个元素
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
// 注意!!!
// 一个Entry就是一个单向链表
// 若该Entry的下一个节点不为空,就将next指向下一个节点;
// 否则,将next指向下一个链表(也是下一个Entry)的不为null的节点。
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
...
}Hashtable的实现方式:先从“后向往前”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
public Set
2.2.6 容量的初始值 和 增加方式都不一样
HashMap默认的容量大小是16;增加容量时,每次将容量变为“原始容量x2”。
Hashtable默认的容量大小是11;增加容量时,每次将容量变为“原始容量x2 + 1”。
HashMap默认的“加载因子”是0.75, 默认的容量大小是16。
// 默认的初始容量是16,必须是2的幂。
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}当HashMap的 “实际容量” >= “阈值”时,(阈值 = 总的容量 * 加载因子),就将HashMap的容量翻倍。
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}Hashtable默认的“加载因子”是0.75, 默认的容量大小是11。
// 默认构造函数。
public Hashtable() {
// 默认构造函数,指定的容量大小是11;加载因子是0.75
this(11, 0.75f);
}当Hashtable的 “实际容量” >= “阈值”时,(阈值 = 总的容量 x 加载因子),就将变为“原始容量x2 + 1”。
// 调整Hashtable的长度,将长度变成原来的(2倍+1)
// (01) 将“旧的Entry数组”赋值给一个临时变量。
// (02) 创建一个“新的Entry数组”,并赋值给“旧的Entry数组”
// (03) 将“Hashtable”中的全部元素依次添加到“新的Entry数组”中
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
int newCapacity = oldCapacity * 2 + 1;
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)(newCapacity * loadFactor);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}2.2.7 添加key-value时的hash值算法不同
HashMap添加元素时,是使用自定义的哈希算法。
Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
HashMap添加元素时,是使用自定义的哈希算法。
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// 将“key-value”添加到HashMap中
public V put(K key, V value) {
// 若“key为null”,则将该键值对添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若“该key”对应的键值对不存在,则将“key-value”添加到table中
modCount++;
addEntry(hash, key, value, i);
return null;
}Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
}
// 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若“Hashtable中不存在键为key的键值对”,
// (01) 将“修改统计数”+1
modCount++;
// (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// (03) 将“Hashtable中index”位置的Entry(链表)保存到e中
Entry<K,V> e = tab[index];
// (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。
tab[index] = new Entry<K,V>(hash, key, value, e);
// (05) 将“Hashtable的实际容量”+1
count++;
return null;
}2.2.8 部分API不同
Hashtable支持contains(Object value)方法,而且重写了toString()方法;
HashMap不支持contains(Object value)方法,没有重写toString()方法。
最后,再说说“HashMap和Hashtable”使用的情景。
其实,若了解它们之间的不同之处后,可以很容易的区分根据情况进行取舍。例如:
(01) 若在单线程中,我们往往会选择HashMap;而在多线程中,则会选择Hashtable。
(02),若不能插入null元素,则选择Hashtable;否则,可以选择HashMap。
但这个不是绝对的标准。例如,在多线程中,我们可以自己对HashMap进行同步,也可以选择ConcurrentHashMap。当HashMap和Hashtable都不能满足自己的需求时,还可以考虑新定义一个类,继承或重新实现散列表;当然,一般情况下是不需要的了。
3、HashMap和WeakHashMap异同
3.1 HashMap和WeakHashMap的相同点
- 它们都是散列表,存储的是“键值对”映射。
- 它们都继承于AbstractMap,并且实现Map基础。
- 它们的构造函数都一样。它们都包括4个构造函数,而且函数的参数都一样。
- 默认的容量大小是16,默认的加载因子是0.75。
- 它们的“键”和“值”都允许为null。
- 它们都是“非同步的”。
3.2 HashMap和WeakHashMap的不同点
HashMap实现了Cloneable和Serializable接口,而WeakHashMap没有。
HashMap实现Cloneable,意味着它能通过clone()克隆自己。
HashMap实现Serializable,意味着它支持序列化,能通过序列化去传输。HashMap的“键”是“强引用(StrongReference)”,而WeakHashMap的键是“弱引用(WeakReference)”。
WeakReference的“弱键”能实现WeakReference对“键值对”的动态回收。当“弱键”不再被使用到时,GC会回收它,WeakReference也会将“弱键”对应的键值对删除。
这个“弱键”实现的动态回收“键值对”的原理呢?其实,通过WeakReference(弱引用)和ReferenceQueue(引用队列)实现的。 首先,我们需要了解WeakHashMap中:
第一,“键”是WeakReference,即key是弱键。
第二,ReferenceQueue是一个引用队列,它是和WeakHashMap联合使用的。当弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。 WeakHashMap中的ReferenceQueue是queue。
第三,WeakHashMap是通过数组实现的,我们假设这个数组是table。
接下来,说说“动态回收”的步骤。
(01) 新建WeakHashMap,将“键值对”添加到WeakHashMap中。
将“键值对”添加到WeakHashMap中时,添加的键都是弱键。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
(02)当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到queue队列中。
例如,当我们在将“弱键”key添加到WeakHashMap之后;后来将key设为null。这时,便没有外部外部对象再引用该了key。
接着,当Java虚拟机的GC回收内存时,会回收key的相关内存;同时,将key添加到queue队列中。
(03) 当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的“弱键”;同步它们,就是删除table中被GC回收的“弱键”对应的键值对。
例如,当我们“读取WeakHashMap中的元素或获取WeakReference的大小时”,它会先同步table和queue,目的是“删除table中被GC回收的‘弱键’对应的键值对”。删除的方法就是逐个比较“table中元素的‘键’和queue中的‘键’”,若它们相当,则删除“table中的该键值对”。
3.3 HashMap和WeakHashMap的比较测试程序
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.WeakHashMap;
import java.util.Date;
import java.lang.ref.WeakReference;
/**
* @desc HashMap 和 WeakHashMap比较程序
*
* @author skywang
* @email kuiwu-wang@163.com
*/
public class CompareHashmapAndWeakhashmap {
public static void main(String[] args) throws Exception {
// 当“弱键”是String时,比较HashMap和WeakHashMap
compareWithString();
// 当“弱键”是自定义类型时,比较HashMap和WeakHashMap
compareWithSelfClass();
}
/**
* 遍历map,并打印map的大小
*/
private static void iteratorAndCountMap(Map map) {
// 遍历map
for (Iterator iter = map.entrySet().iterator();
iter.hasNext(); ) {
Map.Entry en = (Map.Entry)iter.next();
System.out.printf("map entry : %s - %s\n ",en.getKey(), en.getValue());
}
// 打印HashMap的实际大小
System.out.printf(" map size:%s\n\n", map.size());
}
/**
* 通过String对象测试HashMap和WeakHashMap
*/
private static void compareWithString() {
// 新建4个String字符串
String w1 = new String("W1");
String w2 = new String("W2");
String h1 = new String("H1");
String h2 = new String("H2");
// 新建 WeakHashMap对象,并将w1,w2添加到 WeakHashMap中
Map wmap = new WeakHashMap();
wmap.put(w1, "w1");
wmap.put(w2, "w2");
// 新建 HashMap对象,并将h1,h2添加到 WeakHashMap中
Map hmap = new HashMap();
hmap.put(h1, "h1");
hmap.put(h2, "h2");
// 删除HashMap中的“h1”。
// 结果:删除“h1”之后,HashMap中只有 h2 !
hmap.remove(h1);
// 将WeakHashMap中的w1设置null,并执行gc()。系统会回收w1
// 结果:w1是“弱键”,被GC回收后,WeakHashMap中w1对应的键值对,也会被从WeakHashMap中删除。
// w2是“弱键”,但它不是null,不会被GC回收;也就不会被从WeakHashMap中删除。
// 因此,WeakHashMap中只有 w2
// 注意:若去掉“w1=null” 或者“System.gc()”,结果都会不一样!
w1 = null;
System.gc();
// 遍历并打印HashMap的大小
System.out.printf(" -- HashMap --\n");
iteratorAndCountMap(hmap);
// 遍历并打印WeakHashMap的大小
System.out.printf(" -- WeakHashMap --\n");
iteratorAndCountMap(wmap);
}
/**
* 通过自定义类测试HashMap和WeakHashMap
*/
private static void compareWithSelfClass() {
// 新建4个自定义对象
Self s1 = new Self(10);
Self s2 = new Self(20);
Self s3 = new Self(30);
Self s4 = new Self(40);
// 新建 WeakHashMap对象,并将s1,s2添加到 WeakHashMap中
Map wmap = new WeakHashMap();
wmap.put(s1, "s1");
wmap.put(s2, "s2");
// 新建 HashMap对象,并将s3,s4添加到 WeakHashMap中
Map hmap = new HashMap();
hmap.put(s3, "s3");
hmap.put(s4, "s4");
// 删除HashMap中的s3。
// 结果:删除s3之后,HashMap中只有 s4 !
hmap.remove(s3);
// 将WeakHashMap中的s1设置null,并执行gc()。系统会回收w1
// 结果:s1是“弱键”,被GC回收后,WeakHashMap中s1对应的键值对,也会被从WeakHashMap中删除。
// w2是“弱键”,但它不是null,不会被GC回收;也就不会被从WeakHashMap中删除。
// 因此,WeakHashMap中只有 s2
// 注意:若去掉“s1=null” 或者“System.gc()”,结果都会不一样!
s1 = null;
System.gc();
/*
// 休眠500ms
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
// */
// 遍历并打印HashMap的大小
System.out.printf(" -- Self-def HashMap --\n");
iteratorAndCountMap(hmap);
// 遍历并打印WeakHashMap的大小
System.out.printf(" -- Self-def WeakHashMap --\n");
iteratorAndCountMap(wmap);
}
private static class Self {
int id;
public Self(int id) {
this.id = id;
}
// 覆盖finalize()方法
// 在GC回收时会被执行
protected void finalize() throws Throwable {
super.finalize();
System.out.printf("GC Self: id=%d addr=0x%s)\n", id, this);
}
}
}运行结果:
-- HashMap --
map entry : H2 - h2
map size:1
-- WeakHashMap --
map entry : W2 - w2
map size:1
-- Self-def HashMap --
map entry : CompareHashmapAndWeakhashmap$Self@1ff9dc36 - s4
map size:1
-- Self-def WeakHashMap --
GC Self: id=10 addr=0xCompareHashmapAndWeakhashmap$Self@12276af2)
map entry : CompareHashmapAndWeakhashmap$Self@59de3f2d - s2
map size:1













 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









