







引言:
elasticsearch 的出现使得我们的存储、检索数据更快捷、方便。但很多情况下,我们的需求是:现在的数据存储在mysql、oracle等关系型传统数据库中,如何尽量不改变原有数据库表结构,将这些数据的insert,update,delete操作结果实时同步到elasticsearch(简称ES)呢?
本文基于以上需求点展开实战讨论。
1.对delete操作的实时同步泼冷水
到目前为止,所有google,stackoverflow,elastic.co,github上面搜索的插件和实时同步的信息,告诉我们:目前同步delete还没有好的解决方案。
折中的解决方案如下:
方案探讨:https://discuss.elastic.co/t/delete-elasticsearch-document-with-logstash-jdbc-input/47490/9
http://stackoverflow.com/questions/34477095/elasticsearch-replication-of-other-system-data/34477639#34477639
方案一,
在原有的mysql数据库表中,新增一个字段status, 默认值为ok,如果要删除数据,实则用update操作,status改为deleted.
这样,就能同步到es中。es中以status状态值区分该行数据是否存在。deleted代表已删除,ok代表正常。
方案二,
使用go elasticsearch 插件实现同步,如:。但是我实操发现,该插件不稳定,bug较多。我也给源码作者提出了bug。
Bug详见:https://github.com/siddontang/go-mysql-elasticsearch/issues/46
关于删除操作的最终讨论解决方案(截止2016年6月24日):
首先,软件删除而非物理删除数据,新增一个 flag 列,标识记录是否已经被删除,这样,相同的记录也会存在于Elasticsearch。可以执行简单的term查询操作,检索出已经删除的数据信息。
其次,若需要执行cleanup清理数据操作(物理删除),只需要在数据库和ES中同时删除掉标记位deleted的记录即可。如:mysql执行:delete from cc where cc.flag=’deleted’; ES同样执行对应删除操作。
2.如何使用 插件实现insert,update 的同步更新操作?
我的上一篇博文:http://blog.csdn.net/laoyang360/article/details/51694519 做了些许探讨。
除了上篇文章提到的三个插件,这里推荐试用过比较好用的logstash的一款插件,名称为: logstash-input-jdbc
3.如何安装logstash-input-jdbc插件?
【注意啦,注意啦20170920】:logstash5.X开始,已经至少集成了logstash-input-jdbc插件。所以,你如果使用的是logstash5.X,可以不必再安装,可以直接跳过这一步。
参考:http://blog.csdn.net/yeyuma/article/details/50240595#quote
网友博文已经介绍很详细,不再赘述。
基本到这一步:
cd /opt/logstash/
sudo bin/plugin install logstash-input-jdbc
到此,基本就能成功。若不能请留言。
4,如何实现实时同步?
4.1 前提:mysql存在的数据库及表
数据库名为:test
test下表名为:cc
表中数据为:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4.2 需要两个文件:1)jdbc.conf; 2)jdbc.sql.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
[注意啦!注意啦!注意啦!]
cc.modified_at, 这个modified_at是我自己定义的更改时间字段,默认值default是now()当前时间。
而 :sql_last_value如果input里面use_column_value => true, 即如果设置为true的话,可以是我们设定的字段的上一次的值。
默认 use_column_value => false, 这样 :sql_last_value为上一次更新的最后时刻值。
也就是说,对于新增的值,才会更新。这样就实现了增量更新的目的。
有童鞋问,如何全量更新呢? 答案:就是去掉where子句即可。
步骤1:
在logstash的bin路径下新建文件夹logstash_jdbc_test,并将上两个文件 1)jdbc.conf,2)jdbc.sql.模板拷贝到里面。
步骤2:
按照自己的mysql地址、es地址、建立的索引名称、类型名称修改conf,以及要同步内容修改sql。
步骤3:
执行logstash, 如下:
[root@5b9dbaaa148a plugins]# ./logstash -f ./logstash_jdbc_test/jdbc.conf
步骤4:
验证同步是否成功。
可以通过: 如下图所示:
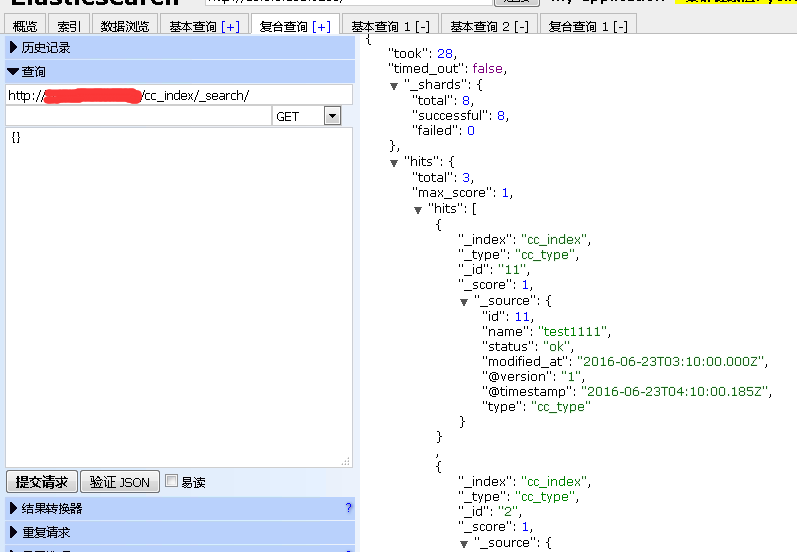
5,注意事项
如果你要测试go-mysql-elasticsearch可能会遇到下面三个Bug及解决方案如下:
【Bug1】
How to Setting The Binary Log Format
http://dev.mysql.com/doc/refman/5.7/en/binary-log-setting.html
【Bug2】
what is inner http status address
https://github.com/siddontang/go-mysql-elasticsearch/issues/11
【Bug3】
[2016/06/23 10:19:38] canal.go:146 [Error] canal start sync binlog err: ERROR 1236 (HY000): Misconfigured master - server id was not set
http://dba.stackexchange.com/questions/76089/error-1236-from-master-after-restored-replication
6,小结
实操发现: logstash-input-jdbc 能较好的实现mysql的insert、update的操作的增量、全量数据同步更新到ES。
但delete操作的实时同步没有很好的解决方案,如果你有,且都测试ok的话,请留言告诉我,不吝赐教!
1,
3,
一、安装 elastisearch, logstash
参考我的上一篇链接 :centos下 ELK部署文档
二、安装logstash-input-jdbc插件
logstash-input-jdbc插件是logstash 的一个个插件。
使用ruby语言开发。
下载插件过程中最大的坑是下载插件相关的依赖的时候下不动,因为国内网络的原因,访问不到亚马逊的服务器。
解决办法,改成国内的ruby仓库镜像。此镜像托管于淘宝的阿里云服务器上
1, 如果没有安装 gem 的话 安装gem
sudoyum install gem
替换淘宝
1,gemsources --add https://ruby.taobao.org/ --remove https://rubygems.org/ 2,gem sources -l *** CURRENT SOURCES *** https://ruby.taobao.org # 请确保只有 ruby.taobao.org 如果 还是显示 https://rubygems.org/ 进入 home的 .gemrc 文件 sudo vim ~/.gemrc 手动删除 https://rubygems.org/
2, 修改Gemfile的数据源地址。步骤:
1,whereis logstash # 查看logstash安装的位置, 我的在 /opt/logstash/ 目录 2, sudo vi Gemfile # 修改 source 的值 为: "https://ruby.taobao.org" 3, sudo vi Gemfile.jruby-1.9.lock # 找到 remote 修改它的值为: https://ruby.taobao.org
或者直接替换源这样你不用改你的 Gemfile 的 source。
sudogem install bundler $ bundle config mirror.https://rubygems.org https://ruby.taobao.org
安装logstash-input-jdbc
我一共试了三种方法,一开始都没有成功,原因如上,镜像的问题。一旦镜像配置成淘宝的了,理论上随便选择一种安装都可以成功,我用的是第三种。
第一种:
cd/opt/logstash/ sudo bin/plugin install logstash-input-jdbc 如果成功就成功了。
第二种:
1,进入源码地址的release页面logstash-input-jdbc
选择对应的版本。我的logstash版本是1.4.0,对应的插件版本是1.0.0
关于插件版本的选择 参考这里:这是ruby Gemfile所有插件的官方地址,参考logstash-core ,如果你的logstash版本跟他对应上,那么这个插件的版本就是你要的版本。
2,复制 1.0.0的下载地址
cd/opt/logstash sudo wget https://github.com/logstash-plugins/logstash-input-jdbc/archive/v1.0.0.zip sudo bin/plugin install v1.0.0.zip 如果成功了就成功了
3, 遗憾的是上两个步骤都没成功,我是手动装的。
参考
$cd /opt/logstash $ wget https://github.com/logstash-plugins/logstash-input-jdbc/archive/v1.0.0.zip $ unzip master.zip $ cd logstash-input-jdbc-master 注意,有坑: 1, 修该 里面的 Gemfile sudo vi Gemfile 修改 source 的值 为: "https://ruby.taobao.org" 2,修改 logstash-input-jdbc.gemspec sudo vi logstash-input-jdbc.gemspec 找到 s.files = `git ls-files`.split($\) 改为: s.files = [".gitignore", "CHANGELOG.md", "Gemfile", "LICENSE", "NOTICE.TXT", "README.md", "Rakefile", "lib/logstash/inputs/jdbc.rb", "lib/logstash/plugin_mixins/jdbc.rb", "logstash-input-jdbc.gemspec", "spec/inputs/jdbc_spec.rb"] OK! 继续..... $ gem build logstash-input-jdbc.gemspec (output: fatal: Not a git repository (or any of the parent directories): .git Successfully built RubyGem Name: logstash-input-jdbc Version: 1.0.0 File: logstash-input-jdbc-1.0.0.gem) $ mv logstash-input-jdbc-1.0.0.gem /opt/logstash/ $ cd .. $ bin/plugin install logstash-input-jdbc-1.0.0.gem 如果再不成功 我也没招了。
三、实现样例。
假如上面步骤都搞定了...重点来了 继续看...没搞定也可以接着看啦..hahahaha....实战......
目的 : 监听数据表的数据,当我有新增时增加到elasticsearch,当我修改时,update到elasticsearch。
第一 前提:
1, 我有mysql数据库,我有一张hotel 表, hotel_account表(此表里有hotel_id), 里面无数据。
2,已经启动 elasticsearch . 地址是
3,已经安装 logstash, 地址在 /opt/logstash
第二 准备
两个文件: jdbc.conf
jdbc.conf 内容:
注意 statement_filepath => "jdbc.sql" 这个名字要跟下面的sql文件的名字对应上。
重点字段说明:
schedule:设置监听间隔。可以设置每隔多久监听一次什么的。具体参考官方文档。
statement_filepath: 执行的sql 文件路径+名称
input {
jdbc {
jdbc_driver_library => "/opt/logstash/config/mysql-connector-java-5.1.18-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/bugreport"
jdbc_user => "root"
jdbc_password => "root"
# parameters => { "favorite_artist" => "B" }
schedule => "* * * * *"
statement => "select id,valid,name,profession_group,module,principal,position ,APK,interface,name_ch,product,pro_principal from tb_yl_cq_package"
# jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/bugreport"
# jdbc_user => "root"
# jdbc_password => "root"
# jdbc_driver_library => "/opt/logstash/config/mysql-connector-java-5.1.18-bin.jar"
# jdbc_driver_class => "com.mysql.jdbc.Driver"
# jdbc_paging_enabled => "true"
## jdbc_page_size => "5000"
# statement_filepath => "/opt/logstash/config/jdbc.sql"
# schedule => "* * * * *"
# type => "jdbc"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => ["172.17.0.18:8070"]
index => "bugreport-package"
document_id => "%{id}"
# cluster => "logstash-elasticsearch"
jdbc.sql
selecth.id as id, h.hotel_name as name, h.photo_url as img, ha.id as haId, ha.finance_person from hotel h LEFT JOIN hotel_account ha on h.id = ha.hotel_id where h.last_modify_time >= :sql_last_start
第三: 启动 logstash
sudo bin/logstash -f jdbc.conf
如果一切顺利 应该如图:

现在 logstash 已经开始监听mysql 的表了。查询哪些表 就在jdbc.sql 写sql语句就行了。
现在 手动的
INSERT INTO hotel(hotel_name, photo_url) VALUES("马二帅酒店","images/madashuai.img");
找到 hotel 的id
INSERTINTO hotel_account(hotel_id, finance_person) VALUES(15627, "马二帅");
大约30秒的时候查看es
很好马二帅酒店已经增加进来了。
现在修改下 hotel_account
UPDATEhotel_account SET finance_person = "马二帅修改为马小帅" where id = 1601;

修改也能监听到哦。
OK到此为止,使用logstash-input-jdbc插件增量监听es就介绍完咯
-----------------------------------
遇到如下问题: 关闭logstash,重启即可(bin/logstash agent --verbose --config conf/jdbc.conf --log logs/stdout.log
{:timestamp=>"2016-08-02T17:22:37.923000+0800", :message=>"A plugin had an unrecoverable error. Will restart this plugin.\n
ne charset=>\"UTF-8\", delimiter=>\"\\n\">>\n
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









