ElasticSearch JAVA API官网文档:https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/java-docs-index.html
一、生成JSON
创建索引的第一步是要把对象转换为JSON字符串.官网给出了四种创建JSON文档的方法:
1.1手写方式生成
String json = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
手写方式很简单,但是要注意日期格式:Date Formate
1.2使用集合
集合是key:value数据类型,可以代表json结构.
Map<String, Object> json = new HashMap<String, Object>();
json.put("user","kimchy");
json.put("postDate","2013-01-30");
json.put("message","trying out Elasticsearch");
1.3使用JACKSON序列化
ElasticSearch已经使用了jackson,可以直接使用它把javabean转为json.
ObjectMapper mapper = new ObjectMapper();
byte[] json = mapper.writeValueAsBytes(yourbeaninstance);
1.4使用ElasticSearch 帮助类
import static org.elasticsearch.common.xcontent.XContentFactory.*
XContentBuilder builder = jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
String json = builder.string()
二、创建索引
下面的例子把json文档写入所以,索引库名为twitter、类型为tweet,id为1:
import static org.elasticsearch.common.xcontent.XContentFactory.*
IndexResponse response = client.prepareIndex("twitter", "tweet", "1")
.setSource(jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
)
.get()
也可以直接传人JSON字符串:
String json = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
IndexResponse response = client.prepareIndex("twitter", "tweet")
.setSource(json)
.get();
可以调用response对象的方法获取返回信息:
// 索引名称
String _index = response.getIndex();
// 类型名称
String _type = response.getType();
// 文档id
String _id = response.getId();
// 版本(if it's the first time you index this document, you will get: 1)
long _version = response.getVersion();
// 是否被创建is true if the document is a new one, false if it has been updated
boolean created = response.isCreated();
更简单的可以直接System.out.println(response)查看返回信息.
三、java实现
新建一个java项目,导入elasticsearch-2.3.3/lib目录下的jar文件.新建一个Blog类:
public class Blog {
private Integer id;
private String title;
private String posttime;
private String content;
public Blog() {
}
public Blog(Integer id, String title, String posttime, String content) {
this.id = id;
this.title = title;
this.posttime = posttime;
this.content = content;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
创建java实体类转json工具类:
import java.io.IOException
import org.elasticsearch.common.xcontent.XContentBuilder
import org.elasticsearch.common.xcontent.XContentFactory
public class JsonUtil {
// Java实体对象转json对象
public static String model2Json(Blog blog) {
String jsonData = null
try {
XContentBuilder jsonBuild = XContentFactory.jsonBuilder()
jsonBuild.startObject().field("id", blog.getId()).field("title", blog.getTitle())
.field("posttime", blog.getPosttime()).field("content",blog.getContent()).endObject()
jsonData = jsonBuild.string()
//System.out.println(jsonData)
} catch (IOException e) {
e.printStackTrace()
}
return jsonData
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
添加数据,返回一个list:
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class DataFactory {
public static DataFactory dataFactory = new DataFactory();
private DataFactory() {
}
public DataFactory getInstance() {
return dataFactory;
}
public static List<String> getInitJsonData() {
List<String> list = new ArrayList<String>();
String data1 = JsonUtil.model2Json(new Blog(1, "git简介", "2016-06-19", "SVN与Git最主要的区别..."));
String data2 = JsonUtil.model2Json(new Blog(2, "Java中泛型的介绍与简单使用", "2016-06-19", "学习目标 掌握泛型的产生意义..."));
String data3 = JsonUtil.model2Json(new Blog(3, "SQL基本操作", "2016-06-19", "基本操作:CRUD ..."));
String data4 = JsonUtil.model2Json(new Blog(4, "Hibernate框架基础", "2016-06-19", "Hibernate框架基础..."));
String data5 = JsonUtil.model2Json(new Blog(5, "Shell基本知识", "2016-06-19", "Shell是什么..."));
list.add(data1);
list.add(data2);
list.add(data3);
list.add(data4);
list.add(data5);
return list;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
创建索引、添加数据:
import java.io.IOException
import java.net.InetAddress
import java.net.UnknownHostException
import java.util.Date
import java.util.List
import org.elasticsearch.action.index.IndexResponse
import org.elasticsearch.client.Client
import org.elasticsearch.client.transport.TransportClient
import org.elasticsearch.common.transport.InetSocketTransportAddress
import org.elasticsearch.common.xcontent.XContentBuilder
import static org.elasticsearch.common.xcontent.XContentFactory.*
public class ElasticSearchHandler {
public static void main(String[] args) {
try {
// client startup
Client client = TransportClient.builder().build()
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300))
List<String> jsonData = DataFactory.getInitJsonData()
for (int i = 0
IndexResponse response = client.prepareIndex("blog", "article").setSource(jsonData.get(i)).get()
if (response.isCreated()) {
System.out.println("创建成功!")
}
}
client.close()
} catch (UnknownHostException e) {
e.printStackTrace()
} catch (IOException e) {
e.printStackTrace()
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
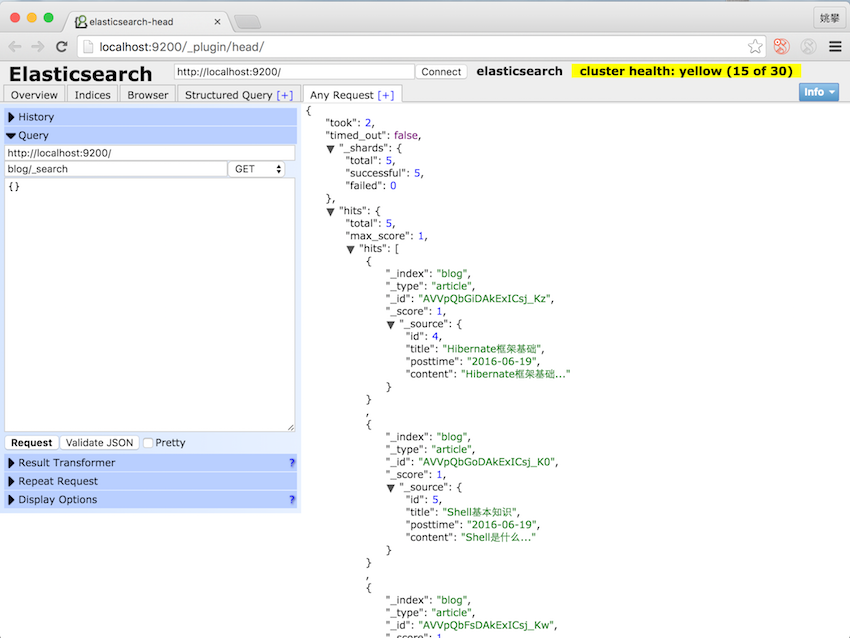
查看插入的数据:
2016.12.12 日更新
使用5.X版本的移步到这里:Elasticsearch 5.0下Java API使用指南
视频教程

课程地址:http://edu.csdn.net/course/detail/5578























 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









