







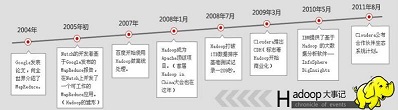
说到Hadoop的起源,不得不说到一个传奇的IT公司—全球IT技术的引领者Google。Google(自称)为云计算概念的提出者,在自身多年的搜索引擎业务中构建了突破性的GFS(Google File System),从此文件系统进入分布式时代。
除此之外,Google在GFS上如何快速分析和处理数据方面开创了MapReduce并行计算框架,让以往的高端服务器计算变为廉价的x86集群计算,也让许多互联网公司能够从IOE(IBM小型机、Oracle数据库以及EMC存储)中解脱出来,例如:淘宝早就开始了去IOE化的道路。然而,Google之所以伟大就在于独享技术不如共享技术,在2002-2004年间以三大论文的发布向世界推送了其云计算的核心组成部分GFS、MapReduce以及BigTable。Google虽然没有将其核心技术开源,但是这三篇论文已经向开源社区的大牛们指明了方向,一位大牛:Doug Cutting使用Java语言对Google的云计算核心技术(主要是GFS和MapReduce)做了开源的实现。
后来,Apache基金会整合Doug Cutting以及其他IT公司(如Facebook等)的贡献成果,开发并推出了Hadoop生态系统。Hadoop是一个搭建在廉价PC上的分布式集群系统架构,它具有高可用性、高容错性和高可扩展性等优点。由于它提供了一个开放式的平台,用户可以在完全不了解底层实现细节的情形下,开发适合自身应用的分布式程序。
2004年12月。Google发表了MapReduce论文,MapReduce允许跨服务器集群,运行超大规模并行计算。Doug Cutting意识到可以用MapReduce来解决Lucene的扩展问题。
Google发表了GFS论文。
Doug Cutting根据GFS和MapReduce的思想创建了开源Hadoop框架。
2006年1月,Doug Cutting加入Yahoo,领导Hadoop的开发。
Doug Cutting任职于Cloudera公司。
2009年7月,Doug Cutting当选为Apache软件基金会董事,2010年9月,当选为chairman。
各大企业开发自己的发行版,并为Apache Hadoop贡献代码。
来源:CUUG官网















 1616
1616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









