







Hive简介:
1、Hive在hadoop生态圈中属于数据仓库的角色。他能够管理hadoop中的数据,同时可以查询hadoop中的数据。
2、Hive其本质来讲,是一个SQL解析引擎。Hive可以把SQL查询转换为MapReduce中的Job来运行(将HQL转化成MR程序)。
3、Hive有一套映射工具,可以把SQL转换为MapReduce中的Job,可以把SQL中的表、字段转换为HDFS中的文件(夹)以及文件中 的列。
映射工具称之为metastore,一般存放在derby、mysql数据库。
4、Hive在HDFS中的默认位置是/user/hive/warehouse,是由配置文件hive-site.xml中属性hive.metastore.warehouse.dir决定的 (简短点,可以修改为/hive)。
Hive的系统架构
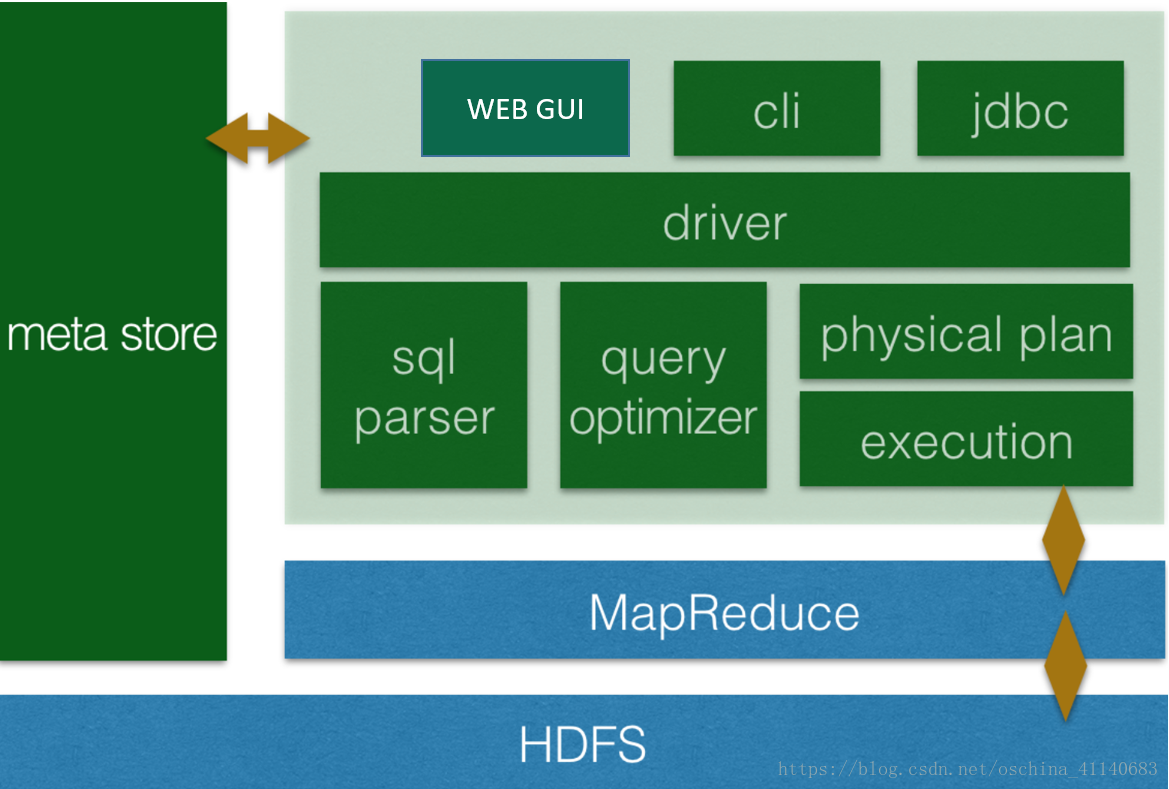
用户接口主要有三个:CLI,JDBC/ODBC和 WebUI
CLI,即Shell命令行;
JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似;
WebGUI是通过浏览器访问 Hive;
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等;
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行;
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)。
Hive的安装(Master)
1、下载Hive软件包:
Apache官网下载安装文件,即 http://mirror.bit.edu.cn/apache/hive/
2、安装
2.1、通过Xshell工具将apache-hive-2.3.3-bin.tar.gz软件上传至/usr/local/src目录;
2.1、解压缩、重命名、设置环境变量
## 解压软件包
cd /usr/local/src
tar -zxvf apache-hive-2.3.3-bin.tar.gz
## 安装目录
mv /usr/local/src/hive-2.3.3 /opt/
## 环境变量配置
vi /etc/profile
export HIVE_HOME=/opt/hive-2.3.3
export PATH=$PATH:${HIVE_HOME}/bin
## 配置生效
source /etc/profile2.2、配置Hive环境
$HIVE_HOME/conf/下,执行重命名
mv hive-default.xml.template hive-site.xml修改Hadoop的配置文件hadoop-env.sh,内容如下:
export HADOOP_CLASSPATH=.:CLASSPATH:CLASSPATH:HADOOP_CLASSPATH:$HADOOP_HOME/bin$HIVE_HOME/bin目录,修改文件hive-config.sh,增加内容:
export JAVA_HOME=/usr/java/default ## 请查看自己的安装路径
export HIVE_HOME=/opt/hive-2.3.3 ## 请查看自己的安装路径
export HADOOP_HOME=/opt/hadoop-2.7.3 ## 请查看自己的安装路径
安装Mysql数据库替换默认的Derby数据库:
A、确保Mysql安装正确且正常启动:
B、进入mysql shell界面:
C、新建hive数据库,用来保存hive的元数据
sql> create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
sql> create database amon DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
sql> create database hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
sql> create database monitor DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
sql> create database oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)D、将Hive数据库的所有表的所有权限赋给用户,配置mysql为hive-site.xml的连接密码,刷新系统权限关系表:
mysql> grant all on *.* to root@"%" Identified by "root";
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;注意:ubuntu系统默认情况下MySQL只允许本地登录,所以需要修改配置文件将地址绑定注释:
sudo vi /etc/mysql/my.cnf
找到 # bind-address = 127.0.0.1 ## 注释此行信息
E、修改hive-site.xml,设置MySQL为默认的meta数据库:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--hive metastore with mysql-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=UTC</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<!--cli header message-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
</configuration>F、Jar包拷贝:
拷贝Mysql的驱动Jar包至 hive的lib文件夹:
cp /usr/local/src/mysql-connector-java-5.1.38.jar $HIVE_HOME/lib/拷贝Hive的lib目录下的jline-xxx.jar包至 Hadoop的/opt/hadoop-2.7.3/share/hadoop/yarn/lib/目录:
cp /opt/hive-2.2.0/lib/jline-2.12.jar /opt/hadoop-2.7.3/share/hadoop/yarn/libG、修改hive-env.sh 环境:
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
HADOOP_HOME=/opt/hadoop-2.7.3H、初始化Mysql数据库:
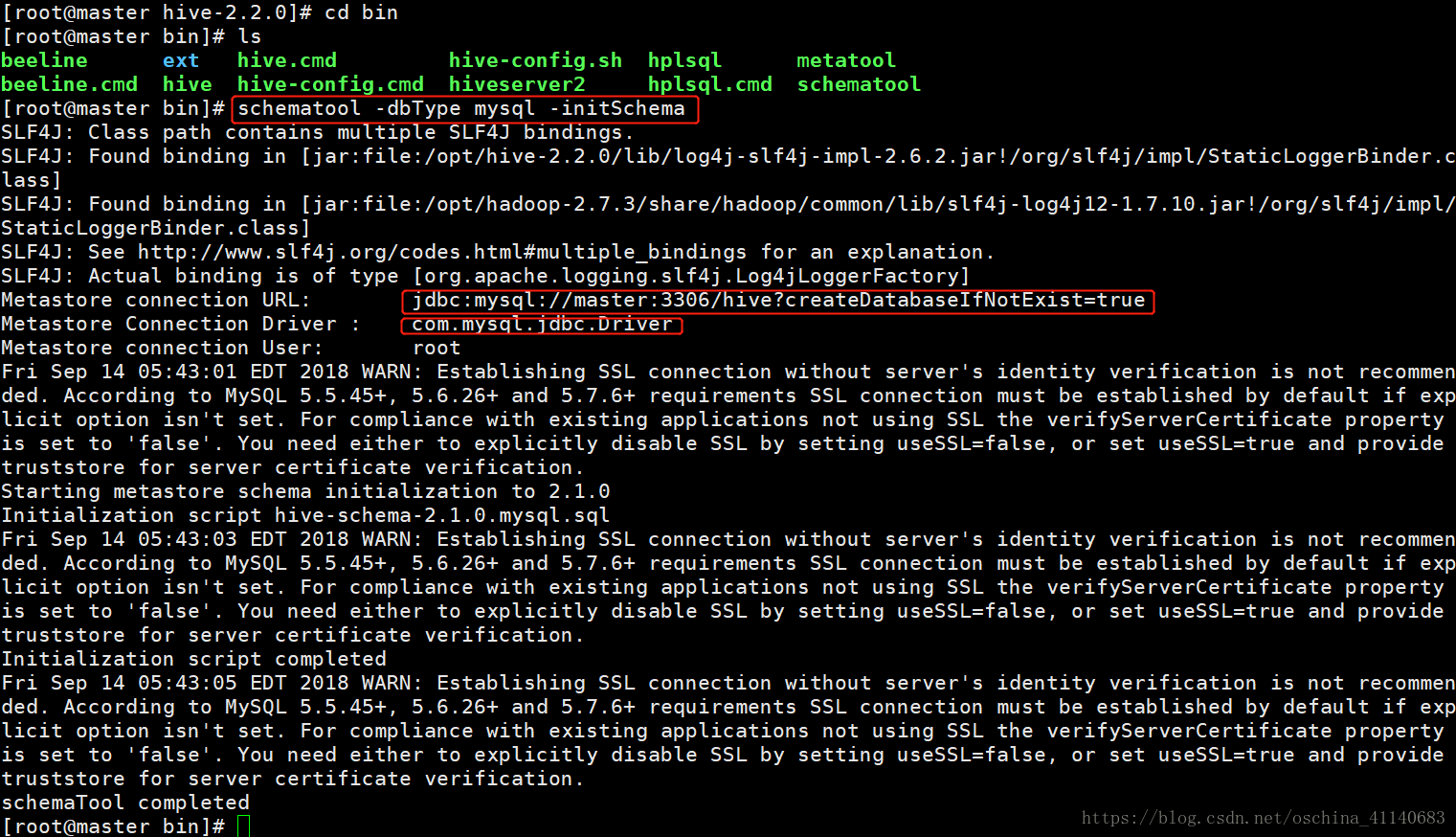
cd /opt/hive-2.3.3/bin
schematool -dbType mysql -initSchema
I、Master服务器执行 hive 命令,进入hive命令行模式;

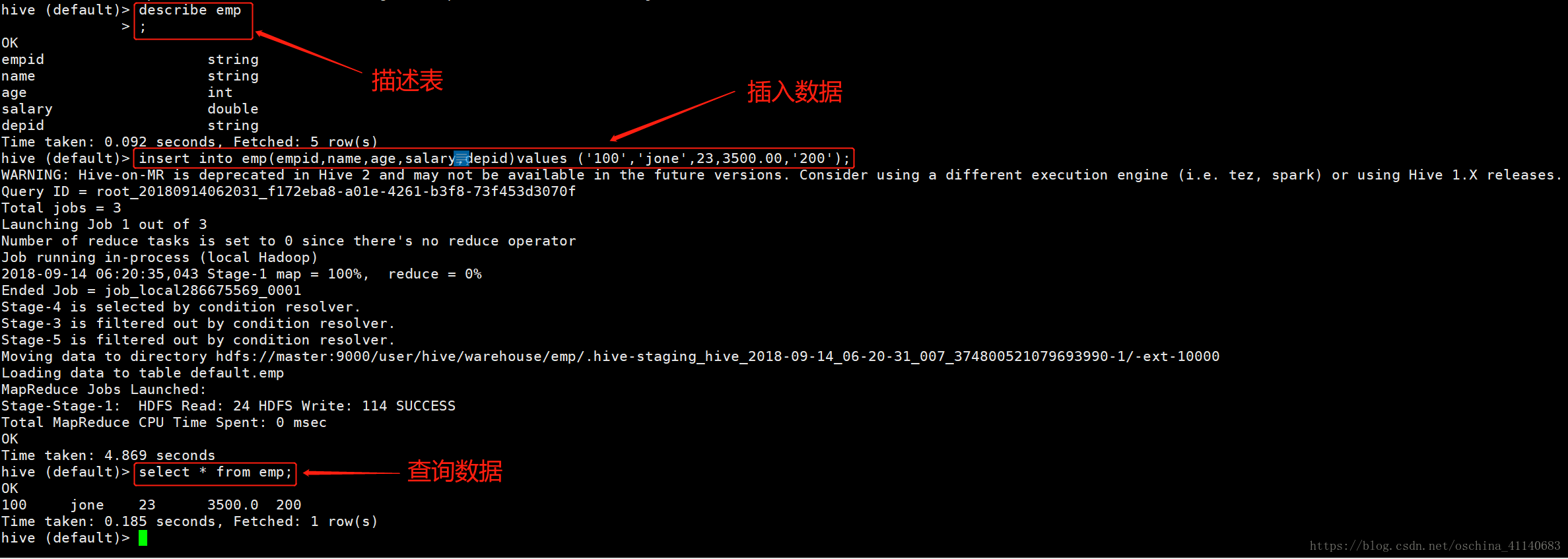
日志hive的简单配置
1、${HIVE_HOME} /conf/hive-log4j.properties 文件(日志参数设置):
cp hive-log4j.properties.template hive-log4j.properties2、自定义日志参数配置:

3、日志文件的位置:
cat hive-log4j.properties
...
hive.log.dir=${java.io.tmpdir}/${user.name} # 自定义目录
hive.log.file=hive.log # 即 /tmp/root/hive.log 文件
...
HIVE使用:
创建表:
a 内表
# 未分区
create table if not exists employee (eid int,ename String ,salary String,job String, role String)
comment 'employee details' row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
# 分区表
create table if not exists employee_static_zone (eid int,ename String ,salary String,job String) partitioned by (role String)
comment 'employee 静态分区表' row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
b 外表
create external table if not exists external_emp (eid int,ename String ,salary String,job String, role String) comment 'employee 外表' row format delimited fields terminated by '\t' location '/user/hive/external/external_emp_orc/';插入数据:
示例数据【存储在Linux本地/data/目录下(新建目录并上传文件)】:
1201 Gopal 45000 Technical manager
1202 Manisha 45000 Proof reader
1203 Masthanvali 40000 Technical writer
1204 Kiran 40000 Hr Admin
1205 Kranthi 30000 Op AdminLOAD DATA语句:
一般来说,在SQL创建表后,我们就可以使用INSERT语句插入数据。但在Hive中,可以使用LOAD DATA语句插入数据。
同时将数据插入到Hive,最好是使用LOAD DATA来存储大量记录。有两种方法用来加载数据:一种是从本地文件系统,第二种是从Hadoop文件系统。
语法
LOAD DATA [LOCAL] INPATH '文件路径' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
# LOCAL是标识符指定本地路径。它是可选的。
# OVERWRITE 是可选的,覆盖表中的数据。
# PARTITION 这是可选的
INSERT overwrite into table table_01 select [字段1,字段2,字段3...] from table_02 ;
# 内表
load data local inpath '/data/employee.txt' overwrite into table employee;
# 静态分区表
insert overwrite table employee_static_zone partition (role='Admin') select eid,ename,salary,job from employee where role = 'Admin';删除表
drop table if exists [tableName];修改表字段名 / 修改表字段类型
Alter table 表名 change column 原字段名称 现字段名称 数据类型清空表数据
# 删除表
DROP TABLE [IF EXISTS] table_name ;
# 删除表数据
TRUNCATE TABLE table_name;重命名表
Rename To… 语句
ALTER TABLE table_name RENAME TO new_table_name;增加/更新列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [CONMMENT col_comment], ...);
示例
hive> ALTER TABLE employee ADD COLUMNS (dept STRING COMMENT 'Department name');
hive> ALTER TABLE employee REPLACE COLUMNS ( eid INT empid Int, ename STRING name String);Hive Cli常见交互命令
# hive cli 帮助
bin/hieve -help
# 查看hive的函数的相关命令:
show functions;
desc function upper;
desc function extended upper;
# 在hive cli 交互窗口执行hdfs命令:
hive (default)> dfs -rm -r /user/ubuntu/xxx.log; # 删除操作
hive (default)> dfs -ls /; # 列表操作
# 在hive cli 交互窗口运行linux本地命令:
hive (default)> !ls /opt/datas
hive (default) >!clear ; #清屏
# 执行 hive sql 的五种方式:
# 方式一:在bash中直接通过hive -e命令,并用 > 输出流把执行结果输出到指定文件
${HIVE_HOME}/bin/hive -e "select * from db_hive.student"; # 库名.表名;
# 方式二:在bash中直接通过hive -f命令,执行文件中一条或者多条sql语句。并用 > 输出流把执行结果输出到制定文件
bin/hive -f /tmp/xxx.sql; # 文件路径;
bin/hive -f /tmp/xxx.sql > /tmp/xxx/result.txt; # 文件路径;
# xxx.sql内容:
select * from student where sex = '男';
select count(*) from student;
# 方式三:(UDF)
bin/hive -i <filename>
# 方式四:
hive (default)> source xxx/xxx.sql
# 方式五:
hive (default)> show databases;
hive (default)> create database db_hive;
hive (default)> use default;
hive (default)> show tables;
# 方式六
# 在hive中输入hive-sql语句,通过使用INSERT OVERWRITE LOCAL DIRECTORY结果到本地系统和HDFS文件系统
insert overwrite directory 'hdfs://master:9000/user/hive/warehouse/t_student' select * from student1;hive cli DDL/DML
-- 查看数据库(默认的数据库为default)
show databases;
show databases like "db*";
desc database db_hive_01;
-- 创建和使用数据库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
create database db_hive_01;
create database if not exists db_hive_01;
create database if not exists db_hive_01 comment 'Hive数据库01';
create database if not exists db_hive_01 comment 'Hive数据库01' location '/user/hive/warehouse/db_hive_01.db';
# 进入数据库;
use db_hive_01;
# 修改数据库
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role;
# (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...);
# (Note: SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path;
# (Note: Hive 2.2.1, 2.4.0 and later)
# 删除数据库
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
drop database if exists db_hive_01 cascade;
# 如果数据库中存在表和数据,则删除需要cascade关键字,这样数据库的目录及其子目录也将被删掉;--------------------------------------------------------------------------------------------------------------------------
<!-- 数据库集成配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://nns:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=UTC</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
参考链接:https://blog.csdn.net/helloxiaozhe/article/details/80749094;














 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









