






2017年11月5日,由中国新一代IT产业推进联盟指导,CIO时代学院主办,北京大学软件工程研究所、金融电子化杂志社联合主办,CIO时代APP承办的“第二届中国区块链与金融科技论坛”在北京大学隆重举行。偶数科技创始人兼CEO常雷在活动中带来了题为《基于新一代数据仓库技术的金融科技》的主题演讲。以下为演讲实录:
很高兴今天下午有机会可以跟大家交流一下我们做的一些工作。简单介绍下自己,之前我博士毕业后加入了EMC,当时EMC收购了Greenplum,这是当时一家研发数据库的创业公司。收购后,两个创始人来到中国建立研发中心,大家交流了我当时做的一个数据仓库研究系统,该系统结合了当时流行的大数据技术和关系数据库的技术。这个数据仓库系统也就是Apache HAWQ的前身。交流完后,他们觉得这个数据仓库系统很有意义,希望我能加入Greenplum然后把它产品化,所以我当时就加入了Greenplum,从事HAWQ产品化的工作。
随后几年做的事情,第一组建了中国Greenplum数据库的研发团队,第二把HAWQ从原型系统idea做成了产品。后来,HAWQ在许多世界500强企业里得到了广泛应用。2015年底,HAWQ成为了Apache的开源项目。去年年底,原来的HAWQ核心团队成立了偶数科技,继续专注于HAWQ的企业版研发。这个过程与Hadoop,Spark的发展都比较类似,比如Hadoop在雅虎里面先做出来,后来创始团队出来创建了Hortonworks,这个公司最近上市了。HAWQ的核心团队也是基于开源的产品来做商业化的工作。
今天的会议主题是“金融科技+区块链”。那么,数据库、金融科技和区块链到底是什么关系呢?区块链技术起源于数字货币,但区块链或分布式帐本都是分布式数据库,因此,它的渊源跟数据库关系是非常紧密的。比如做交易、智能合约等,都可以在分布式数据库里找到它的影子。所以,今天从数据库技术的视角来看区块链或金融科技整个的技术背景。希望给大家提供不同的技术视角。
一、数据仓库生态
整个数据生态系统是非常大的产业,因为大数据比较热,全球是1000-2000亿美金的市场。数据生态系统包括数据源、底层系统、上层各种大数据分析应用。一开始数据在数据源产生,比如它是交易型系统,Oracle或者是MySQL等等。还有其他产生数据的地方,比如说手机、ipad、web服务器等等。数据产生后,经过ETL或收集到数据仓库里面。随着大数据、人工智能、物联网的发展,包括区块链等技术的出现,数据越来越大,对数据仓库的要求越来越高。因此,数据仓库的技术革新是最多的。现在大家看到的Hadoop或Spark、HAWQ基本都属于数据平台的领域。平台上面会有数据治理、数据安全,以及风控等一些大数据应用。下面讲一下数据仓库的演进历程。
二、三代数据仓库的演进历程
从七八十年代到现在,数据仓库的演进大体分为三代。最早期的数据仓库是基于最传统的交易型数据库技术,比如:Oracle,它使用的是共享式存储,是EMC或IBM的高端存储。它的缺点是只能扩展到十几个节点,那么十几个节点后就会碰到存储瓶颈,价格也比较贵。
80年代出现了MPP系统,属于第二代数据仓库。第一个产品化的MPP是Teradata。硬件方面采取了大型机、小型机,以及一些专有硬件的技术。后来出现一些创业公司,比如在2000年左右比较著名的Greenplum、Vertica。它们是基于X86架构的MPP,大规模并行处理MPP系统。这几个创业公司最后都被巨头收购,比如Greenplum被EMC收购,Vertica被惠普收购。
第二代系统解决了可扩展性方面的部分问题,基本上可以到100个节点的规模,但是如果再往上就比较有难度。缺点是这种体系架构决定了可扩展性上不到几千个节点。因为它的工作模式是来了个查询之后,整个查询在所有节点上进行执行,就是每个节点到后来分别并行处理,处理其中一部分任务,这就带来一个缺点,比如:几个人干活容易协调,几千个人在一起干活协调起来很难。机器也一样,协调控制代价很高,各级节点上的负载也不一样。另外,如果执行一个小查询,到后来每个节点上都执行时,它的资源会造成大量浪费。这是第二代系统的缺点。
近些年出现了第三代系统,比如Hadoop上的SQL系统或cloud上的SQL系统,我们称之为新一代数仓。

一、新一代数仓的特点
第三代系统是从大型的互联网公司兴起的,比如Google。因为互联网公司数据量非常大,传统技术解决不了某些问题。他们首先把数据集中起来,形成了现在大家常见的文件系统,如:HDFS,包括其他的分布式文件系统。这些分布式文件系统积累了大量数据后,要做处理,所以有了MapReduce。因为MapReduce不好用,现在被证明了它已经被淘汰。到后来出现了基于MapReduce的SQL引擎,如:Hive。但这一代SQL引擎有不少的缺点,它解决了可扩展性问题,但兼容性稍差。另外,性能方面,Hadoop生态圈,如Hive,SparkSQL性能非常慢。兼容性和性能是第三代系统普遍存在的两个问题。
总体来说,第三代数据仓库可以分为三大类。第一大类:SQL on Hadoop。可以看到SQL on Hadoop是最多的。如SparkSQL、Hive,Presto,因为它的存储基本都在HDFS。第二类叫SQL on Object Store。第一个是Snowflake,,基于亚马逊的S3搭建了SQL on Object Store。S3是一个对象存储系统,它类似于文件系统,存储的是个对象,缺点是不能做简单的内部文件修改,优点是可扩展性包括存储计算分离的好处。另外,亚马逊自己开发的Athena,也基于S3。第三大类是从前面两类系统里发现一些缺陷后又演化出来的系统,比如HAWQ, Impala。客户在使用过程当中想用第三代技术替换传统的MPP或者共享存储,他们发现传统的存储不支持update和delete。如果做update和delete的话,性能会非常差以及混合工作负载性能非常差。所以HAWQ在新一代里面被叫作Hybrid。这时衍生出来自己独立的存储,存储是针对大规模分析处理、并针对NewSQL的工作负载做的存储,同时可以可插拔的访问其他存储。HAWQ, Impala 都属于第三类。
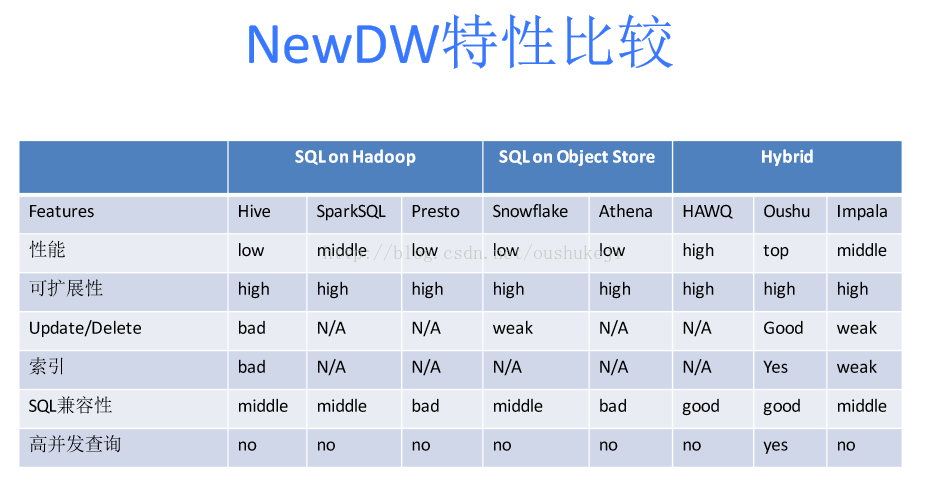
一、NewDW:Oushu Database的前世今生
HAWQ的定位是新一代数据仓库,采取了存储与计算分离的架构,而且可扩展性非常好,兼容性继承了Greenplum的兼容性。
2013年发布了HAWQ第一个版本,性能是Hive的几百倍。现在看,性能还是比Hive要快非常多。2014年我们发表了SIGMOD文章,获得了数据库领域最顶级的世界级的会议认可。2015年我们开源为Apache的项目。2016年底,HAWQ核心团队创立偶数科技,专注于HAWQ企业版。
Oushu Database是HAWQ的企业版本,2017年我们发布了Oushu Database 3.0版本,采用了一个全新的执行器,性能是之前2.0版本的10倍。数据库里面最核心的是什么?研究最多的就是性能,而且性能也是最难的。虽然说数据库研究了很多年,但是性能方面,如果能利用好算法特性、新硬件特性,能把性能做的很快,那是非常重要的。
Oushu Database 3.0 全新执行器性能提升10倍
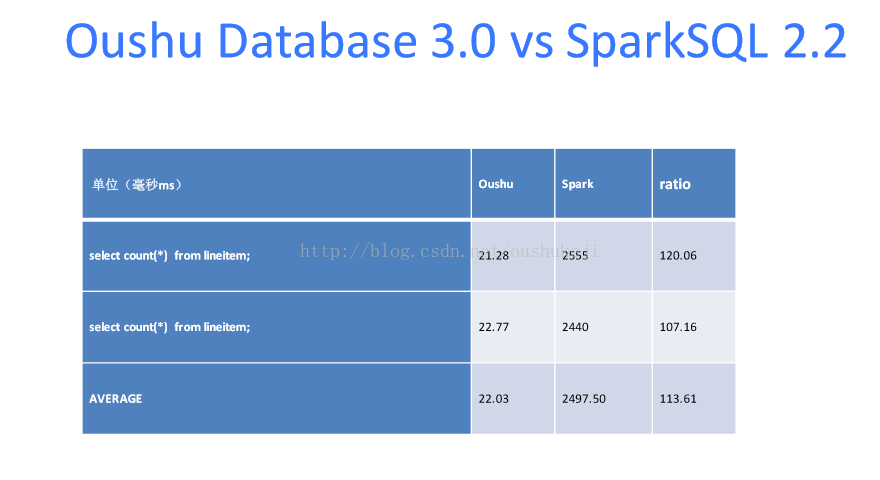
本来HAWQ的性能已经比Hive快很多,这时候你能把HAWQ的性能利用新的CPU的特性,比如说单指令多数据流,就是一条指令可以处理多条数据,这时候你利用并行机制包括新的硬件的特性,能够把性能提高10倍也是非常不容易的。可以说OushuDatabase3.0是目前世界上最快的数据仓库引擎。这里有一些Oushu Database3.0与Spark 2.2的一些性能对比的数据。
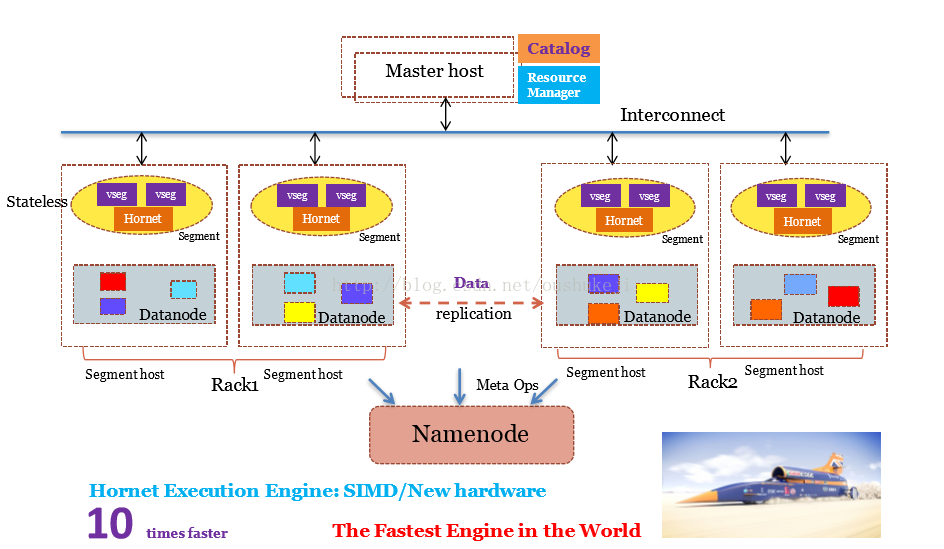
规划中的Oushu Database 4.0,已经考虑了AI的发展、区块链的发展。这是全球规模部署的架构,它没有主节点,任何节点是P2P的节点。一个节点加进来之后可以自动的识别周围的节点,自动加入里面去。
Oushu Database 4.0有两个特性值得关注。第一就是可以支持跨地理区域的部署。跨地理区域在传统的TP里面做的还是有的,比如说Oracle这些都支持。但是在分析类的数仓系统,尤其几百个、上千个PB这种大数据量,很难实现。所以,OushuDatabase 4.0基本上也是世界上第一个在做。
第二就是可以支持mixed workload,就相当于是一个混合工作负载,小查询、索引查询、点查询,或者是大的查询,它可以支持混合的工作负载。其实我们底下的存储层是一个全球分布的NewSQL 引擎,深度上看,你可以看到包括共识算法等等。大家知道,目前区块链技术存在每秒交易量低的瓶颈。但从数据库技术的角度来看,传统上就可以支持非常高的并发。那么,在全球规模部署的情况下然后支持高并发来解决区块链的问题,使用共识算法来解决区块链的问题,这是OushuDatabase 4.0的一个非常自然的延伸。

上图是HAWQ全球客户的列表,大公司基本都在用。GE有几百个节点的集群,使用HAWQ做工业大数据平台的底层支撑。纽交所也在用我们的产品,替换传统的Oracle做交易数据的分析处理。偶数科技,简而言之,主要做数据仓库+数据平台衍生的功能。公司核心成员基本来源于Greenplum、EMC和Google等公司。这是我今天报告的主要内容,谢谢大家。















 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









