






主流监督式机器学习分类算法的性能比较
姓名:欧阳qq 学号:169559
摘要:机器学习是未来解决工程实践问题的一个重要思路。本文采比较了目前监督式学习中几种主流的分类算法(决策树、SVM、贝叶斯、KNN、随机森林、AdaBoost)对UCI波形数据集的分类效果。利用Python的Skilearn开源包搭建分类器,以UCI波形数据集中的前3000个样本作为训练集,后2000个作为测试集,分别在有噪声和无噪声条件下进行分类测试。测试结果表明SVM不管在无噪声还是在噪声条件下分类效果表现最佳,准确率分别为85.5%和85.8%。
关键词:机器学习;分类;Python;Skilearn
1 引言
当计算从大型计算机转移至个人电脑再转移到云的今天,我们可能正处于人类历史上最关键的时期。之所以关键,并不是因为已经取得的成就,而是未来几年里我们即将要获得的进步和成就。如今最令我激动的就是计算技术和工具的普及,从而带来了计算的春天。机器学习研究的主要问题有:分类,聚类、数据预处理、模式识别等,其中分类是机器学习的主要问题。
2 分类方法
一般说来,机器学习有三种算法:
2.1 监督式学习
监督式学习算法包括一个目标变量(因变量)和用来预测目标变量的预测变量(自变量)。通过这些变量我们可以搭建一个模型,从而对于一个已知的预测变量值,我们可以得到对应的目标变量值。重复训练这个模型,直到它能在训练数据集上达到预定的准确度。属于监督式学习的算法有:回归模型,决策树,随机森林,K邻近算法,逻辑回归等。
2.2 无监督式学习
与监督式学习不同的是,无监督学习中我们没有需要预测或估计的目标变量。无监督式学习是用来对总体对象进行分类的。它在根据某一指标将客户分类上有广泛应用。属于无监督式学习的算法有:关联规则,K-means聚类算法等。
2.3 强化学习
这个算法可以训练程序做出某一决定。程序在某一情况下尝试所有的可能行动,记录不同行动的结果并试着找出最好的一次尝试来做决定。属于这一类算法的有马尔可夫决策过程。
以下是最常用的机器学习算法,大部分数据问题都可以通过它们解决:
1).线性回归 (Linear Regression)
2).逻辑回归 (Logistic Regression)
3).决策树 (Decision Tree)
4).支持向量机(SVM)
5).朴素贝叶斯 (Naive Bayes)
6).K邻近算法(KNN)
7).K-均值算法(K-means)
8).随机森林 (Random Forest)
9).降低维度算法(Dimensionality Reduction Algorithms)
10).GradientBoost和Adaboost算法
关于算法的具体介绍,见:
http://scikit-learn.org/stable/supervised_learning.html#supervised-learning
2.4 分类器选择
由于本文采用的数据集为3个类别数据集,无噪声数据集和有噪声数据集中每个样本的维度分别为21和40,且为均为含标签数据样本。所以宜采用监督式多分类算法。上述分类算法中选择决策树、SVM、贝叶斯、KNN、随机森林、AdaBoost 进行分类效果比较。
3 结果
以下是分类算法的的正确率统计表和柱状图:
| 条件 分类器 | 无噪声 | 含噪声 |
| 决策树 | 0.758 | 0.755 |
| SVM | 0.855 | 0.858 |
| 贝叶斯 | 0.821 | 0.795 |
| KNN | 0.83 | 0.81 |
| 随机森林 | 0.805 | 0.814 |
| AdaBoost | 0.845 | 0.845 |
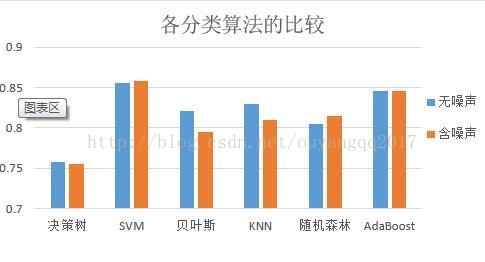
其中贝叶斯和KNN分类算法,对有噪声的分类效果明显较无噪声差,说明这两类分类器的抗干扰能力较差。
4 总结与展望:
从实验结果可看出,针对UCI数据集,SVM算法是目前主流的分类算法中效果最好的,且具有强抗干扰能力,未来将通过其他数据集对目前主流的分类算法进行性能比较。
Reference:
Gales and Young (2007). “The Application of HiddenMarkov Models in Speech Recognition”, Foundations and Trends in SignalProcessing, 1 (3), 195–304: section 2.2.
Jurafsky and Martin (2008). Speech and LanguageProcessing(2nd ed.): sections 6.1–6.5; 9.2; 9.4. (Errata at
Rabiner and Juang (1989). “An introduction to hidden Markovmodels”, IEEE ASSP Magazine, 3 (1), 4–16.
Renals and Hain (2010). “SpeechRecognition”,Computational Linguistics and Natural Language Processing
Handbook, Clark, Fox and Lappin (eds.),Blackwells.
附录:源码代码
数据集下载链接:http://archive.ics.uci.edu/ml/datasets/Waveform+Database+Generator+%28Version+1%29
(1)决策树:
#Import Library
#Import other necessary libraries like pandas,numpy...
from sklearn import tree
#Assumed you have, X (predictor) and Y (target) fortraining data set and x_test(predictor) of test_dataset
X= waveform_noise[0:3000, :40]
y= waveform_noise[0:3000, 40:41]
x_test=waveform_noise[4000:5000, :40]
y_test= waveform_noise[4000:5000, 40:41]
# Create tree object
model = tree.DecisionTreeClassifier(criterion='gini')# for classification, here you can change the algorithm as gini or entropy(information gain) by default it is gini
# model = tree.DecisionTreeRegressor() for regression
# Train the model using the training sets and checkscore
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
res=0;
acc=0;
for i in range(0, 1000):
ifpredicted[i] == y_test[i]:
res=res+1
(2)SVM
acc=res/len(y_test)
#Import Library
from sklearn import svm
#Assumed you have, X (predictor) and Y (target) fortraining data set and x_test(predictor) of test_dataset
X= waveform_noise[0:3000, :40]
y= waveform_noise[0:3000, 40:41]
x_test=waveform_noise[4000:5000, :40]
y_test= waveform_noise[4000:5000, 40:41]
# Create SVM classification object
model = svm.SVC() # there is various option associatedwith it, this is simple for classification. You can refer link, for mo# redetail.
# Train the model using the training sets and checkscore
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
res=0;
acc=0;
for i in range(0, 1000):
ifpredicted[i] == y_test[i]:
res=res+1
acc=res/len(y_test)
(3)贝叶斯 分类
#Import Library
from sklearn.naive_bayes import GaussianNB
#Assumed you have, X (predictor) and Y (target) fortraining data set and x_test(predictor) of test_dataset
X= waveform_noise[0:3000, :40]
y= waveform_noise[0:3000, 40:41]
x_test=waveform_noise[4000:5000, :40]
y_test= waveform_noise[4000:5000, 40:41]
model = GaussianNB() # there is other distribution formultinomial classes like Bernoulli Naive Bayes, Refer link
# Train the model using the training sets and checkscore
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
res=0;
acc=0;
for i in range(0, 1000):
ifpredicted[i] == y_test[i]:
res=res+1
acc=res/len(y_test)
(4)KNN
#Import Library
from sklearn.neighbors import KNeighborsClassifier
#Assumed you have, X (predictor) and Y (target) fortraining data set and x_test(predictor) of test_dataset
X= waveform_noise[0:3000, :40]
y= waveform_noise[0:3000, 40:41]
x_test=waveform_noise[4000:5000, :40]
y_test= waveform_noise[4000:5000, 40:41]
# Create KNeighbors classifier object model
model=KNeighborsClassifier(n_neighbors=6) # defaultvalue for n_neighbors is 5
# Train the model using the training sets and checkscore
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
res=0;
acc=0;
for i in range(0, 1000):
ifpredicted[i] == y_test[i]:
res=res+1
acc=res/len(y_test)
(5)随机森林
#Import Library
from sklearn.ensemble import RandomForestClassifier
#Assumed you have, X (predictor) and Y (target) fortraining data set and x_test(predictor) of test_dataset
X= waveform_noise[0:3000, :40]
y= waveform_noise[0:3000, 40:41]
x_test=waveform_noise[4000:5000, :40]
y_test= waveform_noise[4000:5000, 40:41]
# Create Random Forest object
model= RandomForestClassifier()
# Train the model using the training sets and checkscore
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
res=0;
acc=0;
for i in range(0, 1000):
ifpredicted[i] == y_test[i]:
res=res+1
acc=res/len(y_test)
(6)AdaBoost
#Import Library
from sklearn.ensemble import RandomForestClassifier
#Assumed you have, X (predictor) and Y (target) fortraining data set and x_test(predictor) of test_dataset
X= waveform_noise[0:3000, :40]
y= waveform_noise[0:3000, 40:41]
x_test=waveform_noise[4000:5000, :40]
y_test= waveform_noise[4000:5000, 40:41]
# Create Random Forest object
model= RandomForestClassifier()
# Train the model using the training sets and checkscore
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
res=0;
acc=0;
for i in range(0, 1000):
ifpredicted[i] == y_test[i]:
res=res+1
acc=res/len(y_test)














 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









