






过大或者过小
在计算机中,我们通常会去处小数操作,那么对于过小的数字,在计算机中有可能被表示为0,而对于有些深度学习的函数来说,一个数值为0和这个数值是一个很小的数值,结果会非常不同。
比如除0错误或者log 0。
另外一个情况就是过大。
softmax函数通常用来计算多项式概率分布,定义如下:
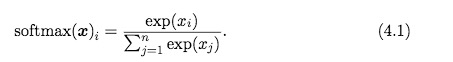
如果xi都为常数c,那么结果应该是1/n。但是如果c是一个无限小的负数,那么c的exp会是过小的数,那么softmax结果就是undefined。
解决方法就是定义softmax(z),然后z=x - maxi xi
不利条件(Poor Conditioning)
当输入微小变化就会导致输出快速变化,在科学计算领域会产生问题。
基于梯度的优化
机器学习常用到优化。优化是指通过增减x,达到或者f(x)的最大值或者最小值的目的。
这个函数一般被称为目标函数。又叫成本函数,损失函数。
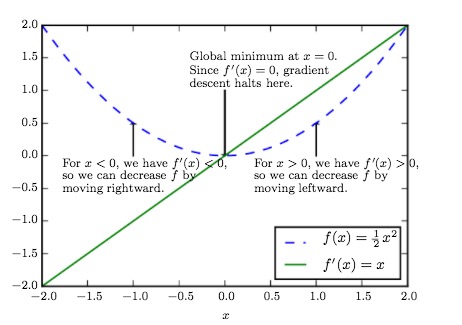
f(x)和它的导数函数(绿色)在x=0时找到最小值。
它的导出为0的点又叫关键点或者叫固定点。
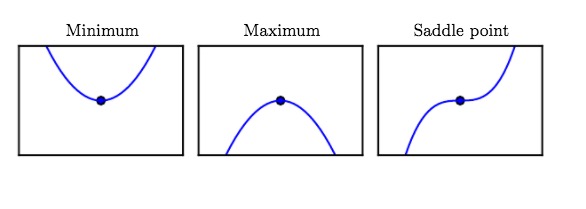
最小值,最大值,鞍型值。
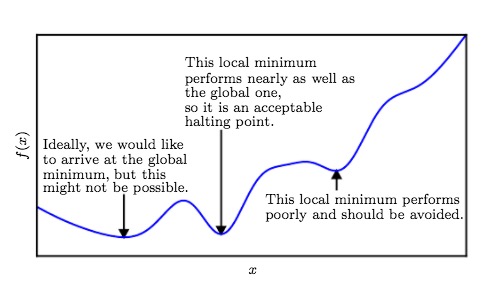
局部最小值和全局最小值:在机器学习领域,通常寻找全局最小值是很难的。如下图:
当有多个输入变量的时候,需要用到偏导。
推导出梯度下降公式:
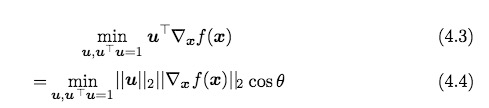
另外一种形式:

一种操作方法是取不同的ε(学习率),然后观察哪个ε使得上面公式最小。这种方法叫线性搜索。
有些时候可以直接跳到关键点(critical point),以减少迭代算法的计算量。
超越梯度-雅克比矩阵和海森矩阵
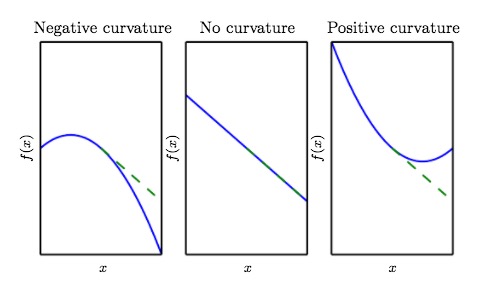
二阶倒数为负,则说明成本函数下降比实际要快。反之亦然。
海森矩阵:
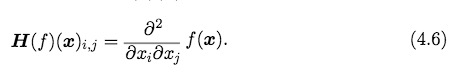
牛顿法
利普希茨连续
凸优化
约束优化
KKT
拉格朗日函数
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









