







大数据生态系统庞大,组件繁多,别说刚入门的新手,甚至工作好几年的大数据工程师都感觉大数据技术难度大、门槛高。笔者基于10多年的大数据经验,梳理了大数据核心的技术要点以及学习路径,希望能帮助大数据朋友更有条不紊地学习。
一. 技术要点
1. 脚本语言
脚本语言是数据处理的利器,毫不夸张地说是必备技能。大数据领域里常用的脚本语言有Linux shell和Python。
Linux shell因为灵活强大的特性在数据处理里被充分挖掘出来。Linux shell里的很多命令处理文本数据非常方便且高效,例如sort、grep、split、paste、awk等。sort支持按一列或多列作为整体进行排序、倒叙、数字列。grep支持忽略大小写、正则匹配等特性来检索数据。split支持数据切分。paste支持数据合并。awk以代码方式来自定义数据处理,拥有内置变量、内置函数,也可以自定义函数,非常灵活且强大。
Linux shell不能处理JSON格式的数据,可以借助python来实现。往往以Linux shell+Python组合实现数据处理。如果用过Hadoop streaming的话,就知道可以用Linux shell+Python实现很多功能。
2. 大数据分区思想
哈希+取模是理解大数据分治的核心思想。可以参考上一篇文章《聊一聊MapReduce计算模型》。
3. Hadoop
Hadoop包含了HDFS、MR引擎、YARN三部分子系统。很多人可能会觉得Hadoop都过时了,不需要去学习了。首先,要说“过时”也只能是MR引擎“过时”了,HDFS和YARN还在被广泛使用。其次,MR引擎虽然在文本处理领域被Spark代替了,但是在一些离线复杂的计算场景,如大规模矩阵运算,MR引擎依然有着无法比拟的优势。
HDFS是分布式文件系统,具备文件系统最基本的能力:管理元数据和数据。只不过在HDFS里,这两个职责分开了,元数据管理由NameNode负责;数据管理由DataNode负责。HDFS可以存储大文件,但这个大文件其实是被切分成很多块(Block)。为了考虑数据可靠性问题,一个块在物理存储时是多副本存储。这个“分区+多副本”的设计理念在很多大数据系统里都被使用,例如Kafka。
NameNode高可用其实包含了两大部分:可用性角色切换和HDFS元数据同步。
可用性切换通过两套ZKFC + NameNode实现,两个NameNode先后启动,都往Zookeeper上创建同一个临时节点,如果创建成功则称为Active Node,另外一个NameNode则切换为Standby。Standby的ZKFC负责监听NameNode在Zookeeper上创建的节点(临时节点)状态,若监听到节点被删除,则说明Active Node宕机,ZKFC通知StandBy NameNode切换为Active,并且创建Zookeeper临时节点。
可用性角色切换后,两个NameNode的数据应该是一致的,否则之前的Standby NameNode如果有数据缺失,切换后会导致HDFS文件缺失,这是不可接受的。为了保障HDFS元数据一致性,引入了JournalNode来同步增量变化的edit log。Standby NameNode从JournalNode获取增量的edit log,定期将现有的fsimage和edit log合并,形成新的fsimage,并通知Active NameNode拉取新的fsimage。
MR引擎包含了是MapReduce计算模型的实现,可参考《聊一聊MapReduce计算模型》。Map的输入是一对<K, V>,输出是一组<K, V>。Reduce的输入是一对<K, Multiple V>, Multiple V是同一个Key下所有V存放在一起。基于此,再对一个Key的所有Value进行规约运算。Reducer之间的数据没有交集,运算后直接输出到对应的分区文件。初学者有必要使用Java API练习MR框架,加深对MR运行原理的理解,学会通过Tracking url查看任务的运行情况。如果有兴趣,可以了解下Mapper和Reducer之间的Shuffle做了哪些事情。
YARN是Hadoop计算时的资源管理子系统,已经被很多其他大数据组件使用,如Spark、Flink等。YARN包含了ResourceManager和NodeManager,是一主多从的经典框架,以Container为基本单位去运行Task。当提交一个程序时,由ApplicationMaster请求分配和释放Container,由ResourceManager执行分配和回收Container,NodeManager以Container的方式去执行Task,可以是Map Task或Reduce Task。ApplicationMaster负责管理Map/Reduce Task, ApplicationMaster本身会占用一个Container。
4. Kafka
Kafka是分布式消息队列,包含了Topic-Partition-Replication三层概念。而读写Kafka的用户只需要关注到Topic。通过命令行和Java API可以实现对Topic、Partition、Replica的操作。
Kafka在写和读时,都会有对应的Offset,写Offset减去读Offset就是消费延迟,叫Lag。尤其是读,会根据groupId来管理读Offset。一个Topic的数据被不同业务方读取(重复消费),groupId不能一样,否则会出现相同groupId的消费者各自消费一部分数据的情况。groupId尽可能是一个随机无规律的字符串。
Kafka引入ISR机制实现了写吞吐量和多副本数据一致性的折中。对于一个Partition来说,ISR是所有副本的一个子集。所有副本是一主多从的模式,如果主Replica挂了,会从ISR里选择一个作为新主,因为ISR已经保证了有一部分Replica的数据是一致的。
5. 函数式编程及Scala
函数式编程是面向动作的编程范式,简洁明了,避免了很多有名函数的定义,也避免了定义很多临时类作为函数参数和返回结果。学习函数式编程其实是为了学习Spark、Flink、Kafka做准备的。因为Spark、Flink里的算子都是函数式编程。初学者可以从JDK8里的Java Stream入手,等熟悉了各种Stream API的用法及基本特性后,再学习Scala。
也许有人会问:Spark、Flink不也支持Java API吗,为什么还要学习Scala呢?只从应用的角度来说,Java API足够用了。但是从更长远的角度看,我们需要逐渐深入理解Kafka、Spark、Flink等大数据组件,更需要阅读里面的源码的,而源码是Scala写的。在大数据系统里,像Kafka、Spark、Flink都是用Scala实现的。其次,Scala生态中的akka被广泛用于Spark、Flink等大数据系统,其易用性、可靠性、高性能、可扩展性等特性已被反复验证,值得深入研究。Scal在国外的流行程度远超国内,国外的Scala著作丰富,社区活跃,值得关注和思考。强烈建议学习Scala !!
6. Spark & Flink
Spark以RDD为数据抽象,支持transformation和action两种算子。任何一个Spark Job都可以表示为一个DAG, DAG在调度时切分成Stage。Stage包含TaskSet,TaskSet包含多个Task,Task就是在executor里执行的最小单元。Spark以batch方式实现对数据的操作,即使在SparkStreaming里,也是mini-batch方式。所以在实时性方面,Spark确实有天然的短板。
Flink以Stream为核心数据结构,加上Operator构成Dataflow。Dataflow也是以DAG的方式去调度执行。Flink支持流批一体,DataStream代表流,DataSet代表批,是有界的数据流。
Spark的根基是批,以批模拟流。Flink的根基是流,以流来模拟批。这里我们不捧谁或贬谁,只客观阐述两者的特性。在批处理或者离线数据处理场景,Spark更成熟易用。在流处理方面,Flink更胜一筹。所以动不动用谁替代谁是不成熟的,从二者开源时间线和业界实践来看,Flink更适合在流方面作为Spark的补充,Flink+Spark看起来是流+批的完美组合。后面我们会有一篇文章专门来阐述架构选型的事。
对于初学者,可以先挑其中一个学习入门,理解基本原理。
7. HBase
HBase是大数据领域不多见的K-V数据库,内部以列式存储来管理数据。
每一行数据都有rowkey, 批量的rowkey归属于一个Region,一个Region中的rowkey是有序的,每个Region包含了startRowkey和endRowKey。Region由RegionServer来管理。HBase中的一张表,可能包含多个Region,这多个Region的rowkey是全局有序的。当一个Region的规模增加到一定阈值,会分裂为两个Region。
一个Region由多个Store组成。每个Store对应HBase表中的CF(Column Family)。一个Store包含一个MemStore和多个StoreFile。数据写入HBase,先写到MemStore,当MemStore的数据累积到一定阈值,数据写入StoreFile,即HFile,存储在HDFS。站在HBase角度叫StoreFile, 站在HDFS角度叫HFile。HBase底层依赖了ZK,HDFS等基础系统。
8. 其他
在大数据技术栈里,有一些比较庞大且复杂的子领域,例如数据仓库、数据湖、OLAP。
这些大数据系统都由很多基础组件构成。如离线数据仓库包含了Hive、Spark、YARN、Airflow等。在OLAP领域,Apache Druid和ClickHouse是目前比较火热的两大阵营,技术成熟度和业界实践都是很不错的。但是系统都比较复杂,学习、理解的门槛都超过了前面单个大数据组件。如Druid依赖Zookeeper、HDFS,自身的组件包含了Broker、Coordinator、Overlord、MiddleManager、Historical Node等。可以先从应用入手,理解Ingestion和Query,理解DataSource、Interval、Segment等概念。
二. 学习路径
根据上述技术要点,可以按阶段、由浅入深地学习。
第一阶段:大数据入门准备: 1, 2, 5
第二阶段:夯实大数据基础: 3 -> 4, 7
第三阶段:挑战复杂系统:6, 8
实际学习过程,并不是全量覆盖,可以通过知识相关性找出一些独立的路径来执行,如下图所示。
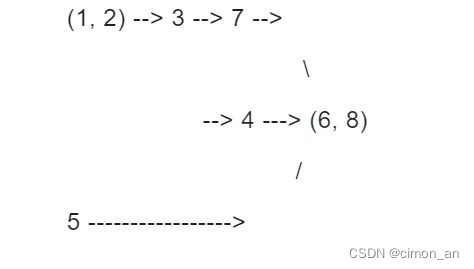
学习路径解释:
1)具备脚本技能和大数据分区思想后,可以学习Hadoop,会覆盖MR2,HDFS,YARN等知识。
2)有了Hadoop的基础,可以学习Kafka和HBase。
3)有了前面基础后,结合Scala知识,可以学习Spark或Flink,会覆盖到MR、批处理(HDFS)、Streaming(Kafka)。
欢迎关注公众号:职场嘚吧嘚
一个专注IT人才成长的平台。















 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









