






14.Oracle内存结构
14-1 Oracle内存结构介绍
当实例启动时,Oracle数据库会分配一块内存区域并启动后台进程。内存区域会存放如下信息:
- 程序代码
- 每个连接的会话信息,即使不是当前活动会话
- 程序执行期间所需要的信息
- 进程间共享和传递的锁的信息
- 缓存的数据,比如数据块和重做记录,而那些数据磁盘上也有
14-1-1 基本的内存结构
Oracle数据库中基本的内存结构包括:
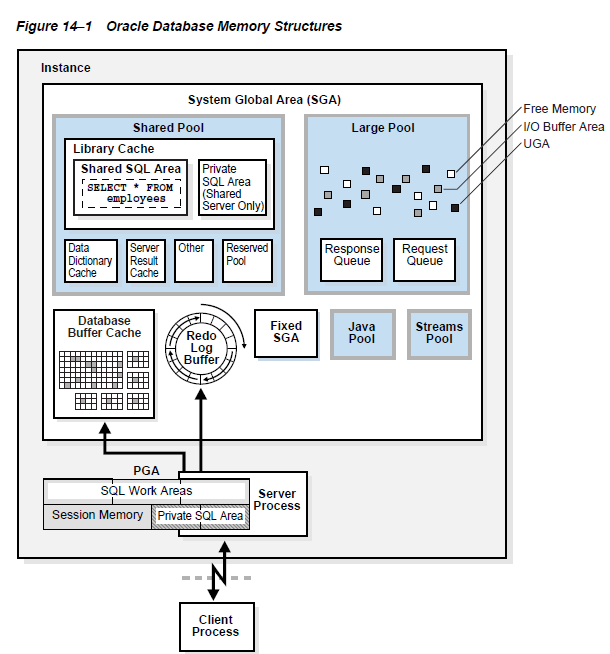
- 系统全局区(SGA)
SGA是一组共享内存结构,也被称作SGA组件。它包含了Oracle数据库实例的数据和控制信息。SGA被所有的服务和后台进程所共享。样例数据存储在了SGA中的缓存数据块和共享SQL区域。
- 程序全局区(PGA)
一个PGA是一块独占内存区域,Oracle进程以专有的方式用它来存放数据和控制信息。当Oracle进程启动时,PGA也就由Oracle数据库创建了。
- 用户全局区(UGA)
UGA的内存分配与用户会话有关。
- 软件代码区
这块区域内存的一部分,它用来存放正在执行或可被执行代码。Oracle数据库的代码就存放其中,当然,这和普通用户程序可不一样,它们放在更为专有并受保护的地方。
图14-1说明了内存结构之间的关系
14-1-2 Oracle数据库内存管理
内存管理包括针对按需改变的数据库,要将Oracle实例的内存结构维护成最佳大小。Oracle数据库是按照与内存相关的初始化参数来管理内存。基本的内存管理操作有以下几点:
- 自动内存管理
你可以为实例的内存指定一个目标大小。当SGA和PGA按照需求要重新分配内存时,数据库实例会依据你的目标内存大小自动地调整。
- 自动共享内存管理
这种管理模式只是部分自动管理。你可以为SGA设置一个目标大小然后为PGA设置一个总计大小(或者单个管理PGA)。
- 手动内存管理
你可以设置一些初始化参数来分别管理SGA和PGA。
如果你是用DBCA创建的数据库,并且选用基本安装,那么默认就是自动内存管理。
14-2 用户全局区(UGA)概览
UGA是会话内存,它是为会话变量而分配的。所谓会话变量是那些登录信息和其他数据库会话要求的信息。从本质上讲,UGA存放着会话状态。图14-2描述着UGA。
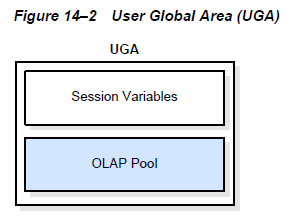
如果一个会话向内存加载一个PL/SQL包,然后UGA就包含这个包的状态,在一个特定时间里,这个状态包含所有包的变量值。当一个包的子程序改变变量时,包的状态就会改变。默认情况下,在会话的生命周期里,包的变量是唯一并存留的。
OLAP页池也存放在UGA中。这个池管理着OLAP的数据页,它们与数据块等同。一个OLAP会话开始时也就分配页池,当会话结束,页池也就被释放。一个OLAP会话会自动打开而不论用户查询一个多维对象。
在一个数据库会话中,UGA必须可用。正是由于这个原因,当使用共享服务连接时,UGA不能存放在PGA中因为PGA是指定的单个进程。因此,当使用共享服务连接时,UGA被存放在SGA中,这样任何共享服务进程都能访问它。当使用专有服务连接时,UGA被存放在PGA中。
14-3 程序全局区(PGA)概览
PGA是由正在运行的进程或线程所指定的内存,它不能被其他进程或线程所共享。因为PGA是进程专有的,它决不会被分配到SGA中。
PGA是一块堆内存,它包含了由专有或共享服务进程所生成的依赖会话变量。服务进程会分配内存到PGA中。
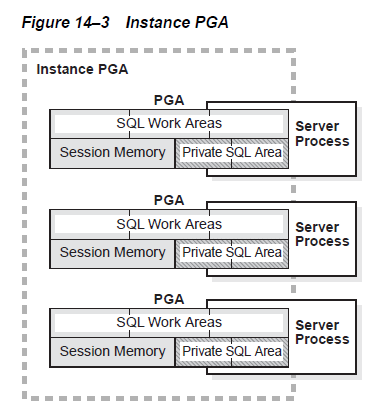
图14-3展示了一个非共享服务的实例的所有PGA。你可以为PGA配置一个目标大小的初始化参数。单个的PGA会根据需要随着目标大小而增长。
14-3-1 PGA内容

14-3-1-1 私有SQL区(Private SQL Area)

- 运行时区(The run-time area)
- 持久区(The persistent area)
14-3-1-2 SQL工作区(SQL Work Areas)
一个工作区是由PGA分配的一块私有内存,它用于一些耗内存(memory-intensive)的操作。比如,一个排序操作会使用排序区来给一个数据集排序,同样,一个哈希联结操作会使用哈希区从左边输入数据来建立一张哈希表,然而,一个位图合并会使用位图合并区来合并数据,那些数据是从复杂的位图索引扫描检索得来。
样例14-1展示了一个雇员表和部门表使用查询计划来联结。
Example 14–1Query Plan for Table Join
SQL> SELECT *
2 FROM employees e JOIN departments d
3 ON e.department_id=d.department_id
4 ORDER BY last_name;

在样例14-1中,运行时监测着全表扫描的进程。该会话在哈希区执行了一个哈希联结用于合并两张表的数据。ORDER BY排序发生在排序区。
如果要处理大量数据以至于工作区不能负荷,那Oracle数据库会将输入的数据分成更小的片。在这种情况下,数据库会在内存中处理一些数据片,期间把剩余数据写入临时磁盘以便接下来处理。
当PGA内存设置为自动管理时,数据库会对工作区自动调优。你也可以手动控制和调优工作区。
通常,对于大的内存消耗,大的工作区对于提高性能是有意义的。理想情况下,工作区能够容纳输入的数据,辅助内存结构能由SQL发起者所分配。若不能做到,那响应时间就会延长,因为部分数据会缓存在磁盘中。在一些极端情况下,如果工作区太小以至于不能与输入的数据大小所比拟,那么数据库会执行来回多次的数据片交换,这样会极大地延长响应时间。
14-3-2 专有和共享服务模式下PGA使用情况
PGA内存分配是依据专有服务模式还是共享服务模式。表14-1展示了其中的不同。

14-4 系统全局区(SGA)概览
SGA是一块可读写的内存区域,它和Oracle后台进程共同组成了数据库实例。用户相关的服务进程会从SGA中读取信息。在数据库操作期间,服务进程会向SGA中写相关信息。
每个数据库实例有它自己的SGA。在实例启动时,Oracle数据库会自动为SGA分配内存并且在关闭时回收内存。当你使用SQL*PLUS或OEM启动实例时,SGA的相关大小会得以显示,如下
SQL> STARTUP
ORACLE instance started.
Total System Global Area 368283648 bytes
Fixed Size 1300440 bytes
Variable Size 343935016 bytes
Database Buffers 16777216 bytes
Redo Buffers 6270976 bytes
Database mounted.
Database opened.
正如图14-1所见,SGA由许多内存组件所组成,那些组件是内存池,它们用于满足不同的特定内存类别要求。除了重做日志缓存的内存分配和释放,其他SGA组件的相邻内存单位都是颗粒(granule)。颗粒的大小与操作系统平台有关,也视SGA大小而定。
你关于SGA组件信息,你可以查询V$SGASTAT视图。
SGA中大多数的重要的组件如下所示:
- 数据库高速缓冲区(Database Buffer Cache)
- 重做日志缓冲区(Redo Log Buffer)
- 共享池(Share Pool)
- 大池(Large Pool)
- Java池(Java Pool)
- 流池(Streams Pool)
- 固定的SGA(Fixed SGA)
14-4-1 数据库高速缓冲区(Database Buffer Cache)
- 使得物理I/O最优
- 在高速缓冲区中保留频繁使用的数据块,并且将频繁使用的数据块写入磁盘。
14-4-1-1 缓冲状态
- 未使用(Unused)
- 干净(Clean)
- 脏(Dirty)
14-4-1-2 缓冲模式
- 当前模式(Current mode)
- 一致模式(Consistent mode)
14-4-1-3 缓冲I/O
14-4-1-3-1 缓冲读(Buffer Writes)
数据库写进程(DBWn)会周期性地往磁盘写“冷”的和“脏”的缓冲数据。DBWn会在下面的情况下写缓冲数据:
- 一个服务进程不能找到干净的缓冲区来读入新块。















 1441
1441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









