






 本文介绍Linux下的网络流量控制技术,重点讲解了使用TC工具进行流量整形、调度和限制的方法。通过实例展示了如何配置队列、分类及过滤器实现不同流量的优先级管理。
本文介绍Linux下的网络流量控制技术,重点讲解了使用TC工具进行流量整形、调度和限制的方法。通过实例展示了如何配置队列、分类及过滤器实现不同流量的优先级管理。
众所周知,在互联网诞生之初都是各个高校和科研机构相互通讯,并没有网络流量控制方面的考虑和设计,IP协议的原则是尽可能好地为所有数据流服务,不同的数据流之间是平等的。然而多年的实践表明,这种原则并不是最理想的,有些数据流应该得到特别的照顾, 比如,远程登录的交互数据流应该比数据下载有更高的优先级。
针对不同的数据流采取不同的策略,这种可能性是存在的。并且,随着研究的发展和深入, 人们已经提出了各种不同的管理模式。IETF已经发布了几个标准, 如综合服务(Integrated Services)、区分服务(Diferentiated Services)等。其实,Linux内核从2 2开始,就已经实现了相关的流量控制功能。本文将介绍Linux中有关流量控制的相关概念, 用于流量控制的工具TC的使用方法,并给出几个有代表性实例。
一、相关概念
由此可以看出, 报文分组从输入网卡(入口)接收进来,经过路由的查找, 以确定是发给本机的,还是需要转发的。如果是发给本机的,就直接向上递交给上层的协议,比如TCP,如果是转发的, 则会从输出网卡(出口)发出。网络流量的控制通常发生在输出网卡处。虽然在路由器的入口处也可以进行流量控制,Linux也具有相关的功能, 但一般说来, 由于我们无法控制自己网络之外的设备, 入口处的流量控制相对较难。本文将集中介绍出口处的流量控制。流量控制的一个基本概念是队列(Qdisc),每个网卡都与一个队列(Qdisc)相联系, 每当内核需要将报文分组从网卡发送出去, 都会首先将该报文分组添加到该网卡所配置的队列中, 由该队列决定报文分组的发送顺序。因此可以说,所有的流量控制都发生在队列中,详细流程图见图1。
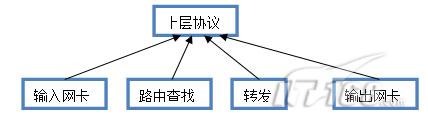
图1报文在Linux内部流程图
有些队列的功能是非常简单的, 它们对报文分组实行先来先走的策略。有些队列则功能复杂,会将不同的报文分组进行排队、分类,并根据不同的原则, 以不同的顺序发送队列中的报文分组。为实现这样的功能,这些复杂的队列需要使用不同的过滤器(Filter)来把报文分组分成不同的类别(Class)。这里把这些复杂的队列称为可分类(ClassfuI)的队列。通常, 要实现功能强大的流量控制, 可分类的队列是必不可少的。因此,类别(class)和过滤器(Filter)也是流量控制的另外两个重要的基本概念。图2所示的是一个可分类队列的例子。
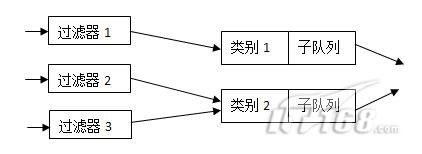
图2多类别队列
由图2可以看出,类别(CIass)和过滤器(Filter)都是队列的内部结构, 并且可分类的队列可以包含多个类别,同时,一个类别又可以进一步包含有子队列,或者子类别。所有进入该类别的报文分组可以依据不同的原则放入不同的子队列或子类别中,以此类推。而过滤器(Filter)是队列用来对数据报文进行分类的工具, 它决定一个数据报文将被分配到哪个类别中。
二、使用TC
在Linux中,流量控制都是通过TC这个工具来完成的。通常, 要对网卡进行流量控制的配置,需要进行如下的步骤:
◆ 为网卡配置一个队列;
◆ 在该队列上建立分类;
◆ 根据需要建立子队列和子分类;
◆ 为每个分类建立过滤器。
在Linux中,可以配置很多类型的队列,比如CBQ、HTB等,其中CBQ 比较复杂,不容易理解。HTB(HierarchicaIToken Bucket)是一个可分类的队列, 与其他复杂的队列类型相比,HTB具有功能强大、配置简单及容易上手等优点。在TC 中, 使用”major:minor”这样的句柄来标识队列和类别,其中major和minor都是数字。
对于队列来说,minor总是为0,即”major:0″这样的形式,也可以简写为”major: 比如,队列1:0可以简写为1:。需要注意的是,major在一个网卡的所有队列中必须是惟一的。对于类别来说,其major必须和它的父类别或父队列的major相同,而minor在一个队列内部则必须是惟一的(因为类别肯定是包含在某个队列中的)。举个例子,如果队列2:包含两个类别,则这两个类别的句柄必须是2:x这样的形式,并且它们的x不能相同, 比如2:1和2:2。
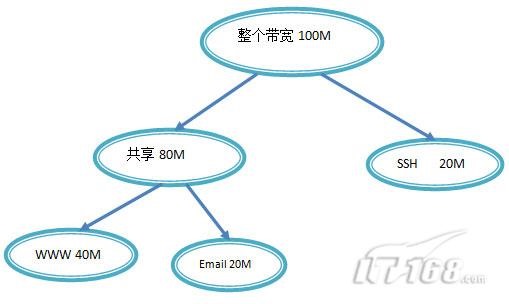
下面,将以HTB队列为主,结合需求来讲述TC的使用。假设eth0出口有100mbit/s的带宽, 分配给WWW 、E-mail和Telnet三种数据流量, 其中分配给WWW的带宽为40Mbit/s,分配给Email的带宽为40Mbit/s, 分配给Telnet的带宽为20Mbit/S。如图3所示。
需要注意的是, 在TC 中使用下列的缩写表示相应的带宽:
◆ Kbps kiIobytes per second, 即”千字节每秒 ;
◆ Mbps megabytes per second, 即”兆字节每秒 ,
◆ Kbit kilobits per second,即”千比特每秒 ;
◆ Mbit megabits per second, 即”兆比特每秒 。
三、创建HTB队列
有关队列的TC命令的一般形式为:
#tc qdisc [add|change|replace|link] dev DEV [parent qdisk-id|root][handle qdisc-id] qdisc[qdisc specific parameters]
首先,需要为网卡eth0配置一个HTB队列,使用下列命令:
#tc qdisc add dev eth0 root handle 1:htb default 11
这里,命令中的”add 表示要添加,”dev eth0 表示要操作的网卡为eth0。”root 表示为网卡eth0添加的是一个根队列。”handle 1: 表示队列的句柄为1:。”htb 表示要添加的队列为HTB队列。命令最后的”default 11 是htb特有的队列参数,意思是所有未分类的流量都将分配给类别1:11。
四、为根队列创建相应的类别
有关类别的TC 命令的一般形式为:
#tc class [add|change|replace] dev DEV parent qdisc-id [classid class-id] qdisc [qdisc specific parameters]
可以利用下面这三个命令为根队列1创建三个类别,分别是1:1 1、1:12和1:13,它们分别占用40、40和20mb[t的带宽。
#tc class add dev eth0 parent 1: classid 1:1 htb rate 40mbit ceil 40mbit
#tc class add dev eth0 parent 1: classid 1:12 htb rate 40mbit ceil 40mbit
#tc class add dev eth0 parent 1: cllassid 1:13 htb rate 20mbit ceil 20mbit
命令中,”parent 1:”表示类别的父亲为根队列1:。”classid1:11″表示创建一个标识为1:11的类别,”rate 40mbit”表示系统
将为该类别确保带宽40mbit,”ceil 40mbit”,表示该类别的最高可占用带宽为40mbit。
五、为各个类别设置过滤器
有关过滤器的TC 命令的一般形式为:
#tc filter [add|change|replace] dev DEV [parent qdisc-id|root] protocol protocol prio priority filtertype [filtertype specific parameters] flowid flow-id
由于需要将WWW、E-mail、Telnet三种流量分配到三个类别,即上述1:11、1:12和1:13,因此,需要创建三个过滤器,如下面的三个命令:
#tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 80 0xffff flowid 1:11
#tc filter add dev eth0 prtocol ip parent 1:0 prio 1 u32 match ip dport 25 0xffff flowid 1:12
#tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 23 oxffff flowid 1:13
这里,”protocol ip”表示该过滤器应该检查报文分组的协议字段。”pr[o 1″ 表示它们对报文处理的优先级是相同的,对于不同优先级的过滤器, 系统将按照从小到大的优先级。
顺序来执行过滤器, 对于相同的优先级,系统将按照命令的先后顺序执行。这几个过滤器还用到了u32选择器(命令中u32后面的部分)来匹配不同的数据流。以第一个命令为例,判断的是dport字段,如果该字段与Oxffff进行与操作的结果是8O,则”flowid 1:11″ 表示将把该数据流分配给类别1:1 1。更加详细的有关TC的用法可以参考TC 的手册页。
六、复杂的实例
在上面的例子中, 三种数据流(www、Email、Telnet)之间是互相排斥的。当某个数据流的流量没有达到配额时,其剩余的带宽并不能被其他两个数据流所借用。在这里将涉及如何使不同的数据流可以共享一定的带宽。
首先需要用到HTB的一个特性, 即对于一个类别中的所有子类别,它们将共享该父类别所拥有的带宽,同时,又可以使得各个子类别申请的各自带宽得到保证。这也就是说,当某个数据流的实际使用带宽没有达到其配额时, 其剩余的带宽可以借给其他的数据流。而在借出的过程中,如果本数据流的数据量增大,则借出的带宽部分将收回, 以保证本数据流的带宽配额。
下面考虑这样的需求, 同样是三个数据流WWW、E-mail和Telnet, 其中的Telnet独立分配20Mbit/s的带宽。另一方面,VWVW 和SMTP各自分配40Mbit/s。同时,它们又是共享的关系, 即它们可以互相借用带宽。如图3所示。
需要的TC命令如下:
#tc qdisc add dev eth0 root handle 1: htb default 21
#tc class add dev eth0 partent 1: classid 1:1 htb rate 20mbit ceil 20mbit
#tc class add dev eth0 parent 1: classid 1:2 htb rate 80mbit ceil 80mbit
#tc class add dev eth0 parent 1: classid 1:21 htb rate 40mbit ceil 20mbit
#tc class add dev eth0 parent 1:2 classid 1:22 htb rate 40mbit ceil 80mbit
#tc filter add dev eth0 protocol parent 10 prio 1 u32 match ip dport 80 0xffff flowid 1:21
#tc filter add dev eth0 protocol parent 1:0 prio 1 u32 match ip dport 25 0xffff flowid 1:22
#tc filter add dev eth0 protocol parent 1:0 prio 1 u32 match ip dport 23 0xffff flowid 1:1
这里为根队列1创建两个根类别,即1:1和1:2,其中1:1对应Telnet数据流,1:2对应80Mbit的数据流。然后,在1:2中,创建两个子类别1:21和1:22,分别对应WWW和E-mail数据流。由于类别1:21和1:22是类别1:2的子类别,因此他们可以共享分配的80Mbit带宽。同时,又确保当需要时,自己的带宽至少有40Mbit。
从这个例子可以看出,利用HTB中类别和子类别的包含关系,可以构建更加复杂的多层次类别树,从而实现的更加灵活的带宽共享和独占模式,达到企业级的带宽管理目的。
QOS 无非就是使用了linux的2个工具, tc 和 iptables ,不管管理界面做的多么垃圾还是多么强大,都是最终翻译成这2个工具的script去执行,并且无论多么NB的管理界面都有很大的局限性(整半天界面也就是实现了命令行下的几个参数的功能而已),所以无法完全发挥这2个工具的作用. 不要以为TOMATO的QOS就很NB,其实就是对这2个工具做了比较好的封装罢了, 都是linux,用好了,分不出什么高下的. 如果你懂linux shell编程, 并且懂数据挖掘与机器学习的理论 ,你完全可以根据一些算法写出带有人工智能特性的QOS脚本,wayos的QOS其实就是这么实现的而已. (美好的展望一下,不多说了,进入正题)
TC是干什么的呢:
TC就是建立数据通道的, 建立的通道有数据包管理方式, 通道的优先级, 通道的速率(这就是限速)
iptables又是干什么的呢?
是决定哪个ip 或者 mac 或者某个应用, 走哪个通道的.
这就是QOS+限速的原理, 大伙明白了吧?
想深入的朋友请看
iptables权威指南1.1.9 http://man.chinaunix.net/network/iptables-tutorial-cn-1.1.19.html
tc命令的介绍和用法 http://wenku.baidu.com/view/324fc91a964bcf84b9d57b01.html
详细的我就不写了,看上面的好好学习,这里我就贴出来我的学习成果吧,直接可用的限速脚本:
以下说的是单位是kbps, 跟普通迅雷上看到的下载速度的换算关系是 除以8 1600/8 = 200K ,迅雷上看到的就是200KB/s
本帖隐藏的内容
#现在开始用TC建立数据的上行和下行通道
TCA=”tc class add dev br0″
TFA=”tc filter add dev br0″
tc qdisc del dev br0 root
tc qdisc add dev br0 root handle 1: htb
tc class add dev br0 parent 1: classid 1:1 htb rate 1600kbit #这个1600是下行总速度
$TCA parent 1:1 classid 1:10 htb rate 200kbit ceil 400kbit prio 2 #这个是10号通道的下行速度,最小200,最大400,优先级为2
$TCA parent 1:1 classid 1:25 htb rate 1000kbit ceil 1600kbit prio 1 #这是我自己使用的特殊25号通道,下行速度最小1000,最大1600,优先级为1, 呵呵,待遇就是不一样
$TFA parent 1:0 prio 2 protocol ip handle 10 fw flowid 1:10
$TFA parent 1:0 prio 1 protocol ip handle 25 fw flowid 1:25
tc qdisc add dev br0 ingress
$TFA parent ffff: protocol ip handle 35 fw police rate 800kbit mtu 12k burst 10k drop #这是我自己使用的35号上行通道,最大速度800
$TFA parent ffff: protocol ip handle 50 fw police rate 80kbit mtu 12k burst 10k drop #这是给大伙使用的50号上行通道,最大速度80
#好了,现在用iptables来觉得哪些人走哪些通道吧,哈哈,由于dd wrt的iptables不支持ip range,所以只能每个IP写一条语句,否则命令无效
iptables -t mangle -A POSTROUTING -d 192.168.1.22 -j MARK –set-mark 10 #ip为192.168.1.22的走10号通道
iptables -t mangle -A POSTROUTING -d 192.168.1.22 -j RETURN #给每条规则加入RETURN,这样效率会更高.
iptables -t mangle -A POSTROUTING -d 192.168.1.23 -j MARK –set-mark 25 #ip为192.168.1.23的走25号特殊通道,23是我的ip,所以特殊点
iptables -t mangle -A POSTROUTING -d 192.168.1.23 -j RETURN #给每条规则加入RETURN,这样效率会更高.
iptables -t mangle -A PREROUTING -s 192.168.1.22 -j MARK –set-mark 50 #ip为22的走50号上行通道
iptables -t mangle -A PREROUTING -s 192.168.1.22 -j RETURN #给每条规则加入RETURN,这样效率会更高.
iptables -t mangle -A PREROUTING -s 192.168.1.23 -j MARK –set-mark 35 #ip为23的走35号上行通道,我自己的IP.呵呵
iptables -t mangle -A PREROUTING -s 192.168.1.23 -j RETURN #给每条规则加入RETURN,这样效率会更高.
#其他的我就不写了,大家自己换IP吧,想让谁走哪个通道,就把IP改了执行,现在发发慈悲,让大家开网页的时候走我使用25和35号通道吧,当然你也可以不发慈悲
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 80 -j MARK –set-mark 35 #http的端口号80,所以dport是80,这是发起http请求的时候
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 80 -j RETURN
iptables -t mangle -A POSTROUTING -p tcp -m tcp –sport 80 -j MARK –set-mark 25 #http的端口号80,所以sport是80,这是http响应回来的时候
iptables -t mangle -A POSTROUTING -p tcp -m tcp –sport 80 -j RETURN
现在来看看如何限制TCP和UDP的连接数吧,很NB的(不知道标准版本和简化版是否支持,一下语句不保证可用,因个人路由器环境而定):
iptables -I FORWARD -p tcp -m connlimit –connlimit-above 100 -j DROP #看到了吧,在FORWARD转发链的时候,所有tcp连接大于100 的数据包就丢弃!是针对所有IP的限制
iptables -I FORWARD -p udp -m limit –limit 5/sec -j DROP #UDP是无法控制连接数的, 只能控制每秒多少个UDP包, 这里设置为每秒5个,5个已经不少了,10个就算很高了,这个是封杀P2P的利器,一般设置为每秒3~5个比较合理.
如何查看命令是否生效呢?:
执行 iptables -L FORWARD 就可以看到如下结果:
DROP tcp – anywhere anywhere #conn/32 > 100
DROP udp – anywhere anywhere limit: avg 5/sec bu
如果出现了这2个结果,说明限制连接数的语句确实生效了, 如果没有这2个出现,则说明你的dd-wrt不支持connlimit限制连接数模块.
现在我想给自己开个后门,不受连接数的限制该怎么做呢?看下面的:
iptables -I FORWARD -s 192.168.1.23 -j RETURN #意思是向iptables的FORWARD链的最头插入这个规则,这个规则现在成为第一个规则了,23是我的IP,就是说,只要是我的IP的就不在执行下面的连接数限制的规则语句了,利用了iptables链的执行顺序规则,我的IP被例外了.
告诉大家一个查看所有人的连接数的语句:
sed -n ‘s%.* src=192.168.[0−9.]∗192.168.[0−9.]∗.*%\1%p’ /proc/net/ip_conntrack | sort | uniq -c #执行这个就可以看到所有IP当前所占用的连接数
对于上面的脚本,有一些比较疑惑人的地方,现在来讲讲:
br0 : 这个是一个dd wrt的网桥, 这个网桥桥接了无线和有线的接口, 所以在这上面卡流量,就相当于卡了所有无线和有线的用户.具体信息可以输入ifconfig命令进行查看.
规则链顺序问题 : 在br0上iptables规则链的顺序是比较奇怪的, 正常的顺序 入站的数据包先过 PERROUTING链, 出站数据包先过POSTROUTING链,但是 dd wrt的br0网桥顺序与正常的顺序正好相反!
在ddwrt上入站的数据包被当成出站的,出站的数据包被当成入站的,所以上面的脚本会那么写.
tc qdisc [ add | change | replace | link ] dev DEV [ parent qdisc-id | root ] [ handle qdisc-id ] qdisc [ qdisc specific parameters ]
tc class [ add | change | replace ] dev DEV parent qdisc-id [ classid class-id ] qdisc [ qdisc specific parameters ]
tc filter [ add | change | replace ] dev DEV [ parent qdisc-id | root ] protocol protocol prio priority filtertype [ filtertype specific parameters ] flowid flow-id
tc [-s | -d ] qdisc show [ dev DEV ]
tc [-s | -d ] class show dev DEV tc filter show dev DEV
简介
Tc用于Linux内核的流量控制。流量控制包括以下几种方式:
SHAPING(限制)
当流量被限制,它的传输速率就被控制在某个值以下。限制值可以大大小于有效带宽,这样可以平滑突发数据流量,使网络更为稳定。shaping(限制)只适用于向外的流量。
SCHEDULING(调度)
通过调度数据包的传输,可以在带宽范围内,按照优先级分配带宽。SCHEDULING(调度)也只适于向外的流量。
POLICING(策略)
SHAPING用于处理向外的流量,而POLICIING(策略)用于处理接收到的数据。
DROPPING(丢弃)
如果流量超过某个设定的带宽,就丢弃数据包,不管是向内还是向外。
流量的处理由三种对象控制,它们是:qdisc(排队规则)、class(类别)和filter(过滤器)。
QDISC(排队规则)
QDisc(排 队规则)是queueing discipline的简写,它是理解流量控制(traffic control)的基础。无论何时,内核如果需要通过某个网络接口发送数据包,它都需要按照为这个接口配置的qdisc(排队规则)把数据包加入队列。然 后,内核会尽可能多地从qdisc里面取出数据包,把它们交给网络适配器驱动模块。
最简单的QDisc是pfifo它不对进入的数据包做任何的处理,数据包采用先入先出的方式通过队列。不过,它会保存网络接口一时无法处理的数据包。
CLASS(类)
某些QDisc(排队规则)可以包含一些类别,不同的类别中可以包含更深入的QDisc(排队规则),通过这些细分的QDisc还可以为进入的队列的数据包排队。通过设置各种类别数据包的离队次序,QDisc可以为设置网络数据流量的优先级。
FILTER(过滤器)
filter(过 滤器)用于为数据包分类,决定它们按照何种QDisc进入队列。无论何时数据包进入一个划分子类的类别中,都需要进行分类。分类的方法可以有多种,使用 fileter(过滤器)就是其中之一。使用filter(过滤器)分类时,内核会调用附属于这个类(class)的所有过滤器,直到返回一个判决。如果 没有判决返回,就作进一步的处理,而处理方式和QDISC有关。
需要注意的是,filter(过滤器)是在QDisc内部,它们不能作为主体。
CLASSLESS QDisc(不可分类QDisc)
无类别QDISC包括:
[p|b]fifo
使用最简单的qdisc,纯粹的先进先出。只有一个参数:limit,用来设置队列的长度,pfifo是以数据包的个数为单位;bfifo是以字节数为单位。
pfifo_fast
在 编译内核时,如果打开了高级路由器(Advanced Router)编译选项,pfifo_fast就是系统的标准QDISC。它的队列包括三个波段(band)。在每个波段里面,使用先进先出规则。而三个 波段(band)的优先级也不相同,band 0的优先级最高,band 2的最低。如果band里面有数据包,系统就不会处理band 1里面的数据包,band 1和band 2之间也是一样。数据包是按照服务类型(Type of Service,TOS)被分配多三个波段(band)里面的。
red
red是Random Early Detection(随机早期探测)的简写。如果使用这种QDISC,当带宽的占用接近于规定的带宽时,系统会随机地丢弃一些数据包。它非常适合高带宽应用。
sfq
sfq是Stochastic Fairness Queueing的简写。它按照会话(session–对应于每个TCP连接或者UDP流)为流量进行排序,然后循环发送每个会话的数据包。
tbf
tbf是Token Bucket Filter的简写,适合于把流速降低到某个值。
不可分类QDisc的配置
如果没有可分类QDisc,不可分类QDisc只能附属于设备的根。它们的用法如下:
tc qdisc add dev DEV root QDISC QDISC-PARAMETERS
要删除一个不可分类QDisc,需要使用如下命令:
tc qdisc del dev DEV root
一个网络接口上如果没有设置QDisc,pfifo_fast就作为缺省的QDisc。
CLASSFUL QDISC(分类QDisc)
可分类的QDisc包括:
CBQ
CBQ 是Class Based Queueing(基于类别排队)的缩写。它实现了一个丰富的连接共享类别结构,既有限制(shaping)带宽的能力,也具有带宽优先级管理的能力。带 宽限制是通过计算连接的空闲时间完成的。空闲时间的计算标准是数据包离队事件的频率和下层连接(数据链路层)的带宽。
HTB
HTB 是 Hierarchy Token Bucket的缩写。通过在实践基础上的改进,它实现了一个丰富的连接共享类别体系。使用HTB可以很容易地保证每个类别的带宽,虽然它也允许特定的类可 以突破带宽上限,占用别的类的带宽。HTB可以通过TBF(Token Bucket Filter)实现带宽限制,也能够划分类别的优先级。
PRIO
PRIO QDisc不能限制带宽,因为属于不同类别的数据包是顺序离队的。使用PRIO QDisc可以很容易对流量进行优先级管理,只有属于高优先级类别的数据包全部发送完毕,才会发送属于低优先级类别的数据包。为了方便管理,需要使用 iptables或者ipchains处理数据包的服务类型(Type Of Service,ToS)。
操作原理
类(Class)组成一个树,每个类都只有一个父类,而一个类可以有多个子类。某些QDisc(例如:CBQ和HTB)允许在运行时动态添加类,而其它的QDisc(例如:PRIO)不允许动态建立类。
允许动态添加类的QDisc可以有零个或者多个子类,由它们为数据包排队。
此外,每个类都有一个叶子QDisc,默认情况下,这个叶子QDisc使用pfifo的方式排队,我们也可以使用其它类型的QDisc代替这个默认的QDisc。而且,这个叶子叶子QDisc有可以分类,不过每个子类只能有一个叶子QDisc。
当一个数据包进入一个分类QDisc,它会被归入某个子类。我们可以使用以下三种方式为数据包归类,不过不是所有的QDisc都能够使用这三种方式。
tc过滤器(tc filter)
如果过滤器附属于一个类,相关的指令就会对它们进行查询。过滤器能够匹配数据包头所有的域,也可以匹配由ipchains或者iptables做的标记。
服务类型(Type of Service)
某些QDisc有基于服务类型(Type of Service,ToS)的内置的规则为数据包分类。
skb->priority
序可以使用SO_PRIORITY选项在skb->priority域设置一个类的ID。
树的每个节点都可以有自己的过滤器,但是高层的过滤器也可以直接用于其子类。
如果数据包没有被成功归类,就会被排到这个类的叶子QDisc的队中。相关细节在各个QDisc的手册页中。
命名规则
所有的QDisc、类和过滤器都有ID。ID可以手工设置,也可以有内核自动分配。
ID由一个主序列号和一个从序列号组成,两个数字用一个冒号分开。
QDISC
一个QDisc会被分配一个主序列号,叫做句柄(handle),然后把从序列号作为类的命名空间。句柄采用象10:一样的表达方式。习惯上,需要为有子类的QDisc显式地分配一个句柄。
类(CLASS)
在同一个QDisc里面的类分享这个QDisc的主序列号,但是每个类都有自己的从序列号,叫做类识别符(classid)。类识别符只与父QDisc有关,和父类无关。类的命名习惯和QDisc的相同。
过滤器(FILTER)
过滤器的ID有三部分,只有在对过滤器进行散列组织才会用到。详情请参考tc-filters手册页。
单位
tc命令的所有参数都可以使用浮点数,可能会涉及到以下计数单位。
带宽或者流速单位:
kbps
千字节/秒
mbps
兆字节/秒
kbit
KBits/秒
mbit
MBits/秒
bps或者一个无单位数字
字节数/秒
数据的数量单位:
kb或者k
千字节
mb或者m
兆字节
mbit
兆bit
kbit
千bit
b或者一个无单位数字
字节数
时间的计量单位:
s、sec或者secs
秒
ms、msec或者msecs
分钟
us、usec、usecs或者一个无单位数字
微秒
TC命令
tc可以使用以下命令对QDisc、类和过滤器进行操作:
add
在一个节点里加入一个QDisc、类或者过滤器。添加时,需要传递一个祖先作为参数,传递参数时既可以使用ID也可以直接传递设备的根。如果要建立一个QDisc或者过滤器,可以使用句柄(handle)来命名;如果要建立一个类,可以使用类识别符(classid)来命名。
remove
删除有某个句柄(handle)指定的QDisc,根QDisc(root)也可以删除。被删除QDisc上的所有子类以及附属于各个类的过滤器都会被自动删除。
change
以替代的方式修改某些条目。除了句柄(handle)和祖先不能修改以外,change命令的语法和add命令相同。换句话说,change命令不能一定节点的位置。
replace
对一个现有节点进行近于原子操作的删除/添加。如果节点不存在,这个命令就会建立节点。
link
只适用于DQisc,替代一个现有的节点。
历史
tc由Alexey N. Kuznetsov编写,从Linux 2.2版开始并入Linux内核。
SEE ALSO
tc-cbq(8)、tc-htb(8)、tc-sfq(8)、tc-red(8)、tc-tbf(8)、tc-pfifo(8)、tc-bfifo(8)、tc-pfifo_fast(8)、tc-filters(8)
Linux从kernel 2.1.105开始支持QOS,不过,需要重新编译内核。运行make config时将EXPERIMENTAL _OPTIONS设置成y,并且将Class Based Queueing (CBQ), Token Bucket Flow, Traffic Shapers 设置为 y ,运行 make dep; make clean; make bzilo,生成新的内核。
在Linux操作系统中流量控制器(TC)主要是在输出端口处建立一个队列进行流量控制,控制的方式是基于路由,亦即基于目的IP地址或目的子网的网络号的流量控制。流量控制器TC,其基本的功能模块为队列、分类和过滤器。Linux内核中支持的队列有,Class Based Queue ,Token Bucket Flow ,CSZ ,First In First Out ,Priority ,TEQL ,SFQ ,ATM ,RED。这里我们讨论的队列与分类都是基于CBQ(Class Based Queue)的,而过滤器是基于路由(Route)的。
配置和使用流量控制器TC,主要分以下几个方面:分别为建立队列、建立分类、建立过滤器和建立路由,另外还需要对现有的队列、分类、过滤器和路由进行监视。
其基本使用步骤为:
1) 针对网络物理设备(如以太网卡eth0)绑定一个CBQ队列;
2) 在该队列上建立分类;
3) 为每一分类建立一个基于路由的过滤器;
4) 最后与过滤器相配合,建立特定的路由表。
先假设一个简单的环境
流量控制器上的以太网卡(eth0) 的IP地址为192.168.1.66,在其上建立一个CBQ队列。假设包的平均大小为1000字节,包间隔发送单元的大小为8字节,可接收冲突的发送最长包数目为20字节。
假如有三种类型的流量需要控制:
1) 是发往主机1的,其IP地址为192.168.1.24。其流量带宽控制在8Mbit,优先级为2;
2) 是发往主机2的,其IP地址为192.168.1.26。其流量带宽控制在1Mbit,优先级为1;
3) 是发往子网1的,其子网号为192.168.1.0,子网掩码为255.255.255.0。流量带宽控制在1Mbit,优先级为6。
1. 建立队列
一般情况下,针对一个网卡只需建立一个队列。
将一个cbq队列绑定到网络物理设备eth0上,其编号为1:0;网络物理设备eth0的实际带宽为10 Mbit,包的平均大小为1000字节;包间隔发送单元的大小为8字节,最小传输包大小为字节。
tc qdisc add dev eth0 root handle 1: cbq bandwidth 10Mbit avpkt 1000 cell 8 mpu
2. 建立分类
分类建立在队列之上。一般情况下,针对一个队列需建立一个根分类,然后再在其上建立子分类。对于分类,按其分类的编号顺序起作用,编号小的优先;一旦符合某个分类匹配规则,通过该分类发送数据包,则其后的分类不再起作用。
1) 创建根分类1:1;分配带宽为10Mbit,优先级别为8。
tc class add dev eth0 parent 1:0 classid 1:1 cbq bandwidth 10Mbit rate 10Mbit maxburst 20 allot 1514 prio 8 avpkt 1000 cell 8 weight 1Mbit
该队列的最大可用带宽为10Mbit,实际分配的带宽为10Mbit,可接收冲突的发送最长包数目为20字节;最大传输单元加MAC头的大小为1514字节,优先级别为8,包的平均大小为1000字节,包间隔发送单元的大小为8字节,相应于实际带宽的加权速率为1Mbit。
2)创建分类1:2,其父分类为1:1,分配带宽为8Mbit,优先级别为2。
tc class add dev eth0 parent 1:1 classid 1:2 cbq bandwidth 10Mbit rate 8Mbit maxburst 20 allot 1514 prio 2 avpkt 1000 cell 8 weight 800Kbit split 1:0 bounded
该队列的最大可用带宽为10Mbit,实际分配的带宽为 8Mbit,可接收冲突的发送最长包数目为20字节;最大传输单元加MAC头的大小为1514字节,优先级别为1,包的平均大小为1000字节,包间隔发送单元的大小为8字节,相应于实际带宽的加权速率为800Kbit,分类的分离点为1:0,且不可借用未使用带宽。
3)创建分类1:3,其父分类为1:1,分配带宽为1Mbit,优先级别为1。
tc class add dev eth0 parent 1:1 classid 1:3 cbq bandwidth 10Mbit rate 1Mbit maxburst 20 allot 1514 prio 1 avpkt 1000 cell 8 weight 100Kbit split 1:0
该队列的最大可用带宽为10Mbit,实际分配的带宽为 1Mbit,可接收冲突的发送最长包数目为20字节;最大传输单元加MAC头的大小为1514字节,优先级别为2,包的平均大小为1000字节,包间隔发送单元的大小为8字节,相应于实际带宽的加权速率为100Kbit,分类的分离点为1:0。
4)创建分类1:4,其父分类为1:1,分配带宽为1Mbit,优先级别为6。
tc class add dev eth0 parent 1:1 classid 1:4 cbq bandwidth 10Mbit rate 1Mbit maxburst 20 allot 1514 prio 6 avpkt 1000 cell 8 weight 100Kbit split 1:0
该队列的最大可用带宽为10Mbit,实际分配的带宽为 Kbit,可接收冲突的发送最长包数目为20字节;最大传输单元加MAC头的大小为1514字节,优先级别为1,包的平均大小为1000字节,包间隔发送单元的大小为8字节,相应于实际带宽的加权速率为100Kbit,分类的分离点为1:0。
3. 建立过滤器
过滤器主要服务于分类。一般只需针对根分类提供一个过滤器,然后为每个子分类提供路由映射。
1) 应用路由分类器到cbq队列的根,父分类编号为1:0;过滤协议为ip,优先级别为100,过滤器为基于路由表。
tc filter add dev eth0 parent 1:0 protocol ip prio 100 route
2) 建立路由映射分类1:2, 1:3, 1:4
tc filter add dev eth0 parent 1:0 protocol ip prio 100 route to 2 flowid 1:2
tc filter add dev eth0 parent 1:0 protocol ip prio 100 route to 3 flowid 1:3
tc filter add dev eth0 parent 1:0 protocol ip prio 100 route to 4 flowid 1:4
4.建立路由
该路由是与前面所建立的路由映射一一对应。
1) 发往主机192.168.1.24的数据包通过分类2转发(分类2的速率8Mbit)
ip route add 192.168.1.24 dev eth0 via 192.168.1.66 realm 2
2) 发往主机192.168.1.30的数据包通过分类3转发(分类3的速率1Mbit)
ip route add 192.168.1.30 dev eth0 via 192.168.1.66 realm 3
3)发往子网192.168.1.0/24的数据包通过分类4转发(分类4的速率1Mbit)
ip route add 192.168.1.0/24 dev eth0 via 192.168.1.66 realm 4
注:一般对于流量控制器所直接连接的网段建议使用IP主机地址流量控制限制,不要使用子网流量控制限制。如一定需要对直连子网使用子网流量控制限制,则在建立该子网的路由映射前,需将原先由系统建立的路由删除,才可完成相应步骤。
5. 监视
主要包括对现有队列、分类、过滤器和路由的状况进行监视。
1)显示队列的状况
简单显示指定设备(这里为eth0)的队列状况
tc qdisc ls dev eth0
qdisc cbq 1: rate 10Mbit (bounded,isolated) prio no-transmit
详细显示指定设备(这里为eth0)的队列状况
tc -s qdisc ls dev eth0
qdisc cbq 1: rate 10Mbit (bounded,isolated) prio no-transmit
Sent 76731 bytes 13232 pkts (dropped 0, overlimits 0)
borrowed 0 overactions 0 avgidle 31 undertime 0
这里主要显示了通过该队列发送了13232个数据包,数据流量为76731个字节,丢弃的包数目为0,超过速率限制的包数目为0。
2)显示分类的状况
简单显示指定设备(这里为eth0)的分类状况
tc class ls dev eth0
class cbq 1: root rate 10Mbit (bounded,isolated) prio no-transmit
class cbq 1:1 parent 1: rate 10Mbit prio no-transmit #no-transmit表示优先级为8
class cbq 1:2 parent 1:1 rate 8Mbit prio 2
class cbq 1:3 parent 1:1 rate 1Mbit prio 1
class cbq 1:4 parent 1:1 rate 1Mbit prio 6
详细显示指定设备(这里为eth0)的分类状况
tc -s class ls dev eth0
class cbq 1: root rate 10Mbit (bounded,isolated) prio no-transmit
Sent 17725304 bytes 32088 pkts (dropped 0, overlimits 0)
borrowed 0 overactions 0 avgidle 31 undertime 0
class cbq 1:1 parent 1: rate 10Mbit prio no-transmit
Sent 16627774 bytes 28884 pkts (dropped 0, overlimits 0)
borrowed 16163 overactions 0 avgidle 587 undertime 0
class cbq 1:2 parent 1:1 rate 8Mbit prio 2
Sent 628829 bytes 3130 pkts (dropped 0, overlimits 0)
borrowed 0 overactions 0 avgidle 4137 undertime 0
class cbq 1:3 parent 1:1 rate 1Mbit prio 1
Sent 0 bytes 0 pkts (dropped 0, overlimits 0)
borrowed 0 overactions 0 avgidle 159654 undertime 0
class cbq 1:4 parent 1:1 rate 1Mbit prio 6
Sent 5552879 bytes 8076 pkts (dropped 0, overlimits 0)
borrowed 3797 overactions 0 avgidle 159557 undertime 0
这里主要显示了通过不同分类发送的数据包,数据流量,丢弃的包数目,超过速率限制的包数目等等。其中根分类(class cbq 1:0)的状况应与队列的状况类似。
例如,分类class cbq 1:4发送了8076个数据包,数据流量为5552879个字节,丢弃的包数目为0,超过速率限制的包数目为0。
显示过滤器的状况
tc -s filter ls dev eth0
filter parent 1: protocol ip pref 100 route
filter parent 1: protocol ip pref 100 route fh 0xffff0002 flowid 1:2 to 2
filter parent 1: protocol ip pref 100 route fh 0xffff0003 flowid 1:3 to 3
filter parent 1: protocol ip pref 100 route fh 0xffff0004 flowid 1:4 to 4
这里flowid 1:2代表分类class cbq 1:2,to 2代表通过路由2发送。
显示现有路由的状况
ip route
192.168.1.66 dev eth0 scope link
192.168.1.24 via 192.168.1.66 dev eth0 realm 2
202.102.24.216 dev ppp0 proto kernel scope link src 202.102.76.5
192.168.1.30 via 192.168.1.66 dev eth0 realm 3
192.168.1.0/24 via 192.168.1.66 dev eth0 realm 4
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.66
172.16.1.0/24 via 192.168.1.66 dev eth0 scope link
127.0.0.0/8 dev lo scope link
default via 202.102.24.216 dev ppp0
default via 192.168.1.254 dev eth0
如上所示,结尾包含有realm的显示行是起作用的路由过滤器。
6. 维护
主要包括对队列、分类、过滤器和路由的增添、修改和删除。
增添动作一般依照”队列->分类->过滤器->路由”的顺序进行;修改动作则没有什么要求;删除则依照”路由->过滤器->分类->队列”的顺序进行。
1)队列的维护
一般对于一台流量控制器来说,出厂时针对每个以太网卡均已配置好一个队列了,通常情况下对队列无需进行增添、修改和删除动作了。
2)分类的维护
增添
增添动作通过tc class add命令实现,如前面所示。
修改
修改动作通过tc class change命令实现,如下所示:
tc class change dev eth0 parent 1:1 classid 1:2 cbq bandwidth 10Mbit rate 7Mbit maxburst 20 allot 1514 prio 2 avpkt 1000 cell 8 weight 700Kbit split 1:0 bounded
对于bounded命令应慎用,一旦添加后就进行修改,只可通过删除后再添加来实现。
删除
删除动作只在该分类没有工作前才可进行,一旦通过该分类发送过数据,则无法删除它了。因此,需要通过shell文件方式来修改,通过重新启动来完成删除动作。
3)过滤器的维护
增添
增添动作通过tc filter add命令实现,如前面所示。
修改
修改动作通过tc filter change命令实现,如下所示:
tc filter change dev eth0 parent 1:0 protocol ip prio 100 route to 10 flowid 1:8
删除
删除动作通过tc filter del命令实现,如下所示:
tc filter del dev eth0 parent 1:0 protocol ip prio 100 route to 10
4)与过滤器一一映射路由的维护
增添
增添动作通过ip route add命令实现,如前面所示。
修改
修改动作通过ip route change命令实现,如下所示:
ip route change 192.168.1.30 dev eth0 via 192.168.1.66 realm 8
删除
删除动作通过ip route del命令实现,如下所示:
ip route del 192.168.1.30 dev eth0 via 192.168.1.66 realm 8
ip route del 192.168.1.0/24 dev eth0 via 192.168.1.66 realm 4
C规则涉及到 队列(QUEUE) 分类器(CLASS) 过滤器(FILTER),filter划分的标志位可用U32或iptables的set-mark来实现 ) 一般是”控发”不控收 linux下有两块网卡,一个eth1是外网,另一块eth0是内网.在eth0上做HTB。(注 意:filter划分标志位可用u32打标功能或iptables的set-mark功能,如果用iptables来打标记的话,下行速LV在eth0处 控制,但打标应在进入eth0之前进行,所以,“-i eth1″;例子:
主要命令就下面三句:创建一个HTB的根
1.tc qdisc add dev eth0 root handle 1: htb default 20创建一个HTB的类,流量的限制就是在这里限制的,并设置突发.
2.tc class add dev eth0 parent 1: classid 1:1 htb rate 200kbit(速率) ceil 200kbit burst 20k(突发流量)
创建一个过滤规则把要限制流量的数据过滤出来,并发给上面的类来限制速度3.tc filter add dev eth0 parent 1: prio 1(优先级) protocol ip u32 match ip sport 80 0xfff flowid 1:1
说明:让交互数据包保持较低的延迟时间,并最先取得空闲带宽,比如:
ssh telnet dns quake3 irc ftp控制 smtp命令和带有SYN标记的数据包,都应属于这一类。为了保证上行数据流不会伤害下行流,还要把ACK数据包排在队列前面,因为下行数据的ACK必须同上行流进行竟争。
TC+IPTABLES+HTB+SFQ
1 tcp/ip 协议规定,每个封包,都需要有ACKNOWLEDGE讯息的回传,也就是说,传输的资料需要有一个收到资料的讯息回复,才能决定后面的传输速度,并决定是 否重新传输遗失的资料,上行的带宽一部分就是用来传输这些ACK资料的.上行带宽点用大的时候,就会影响ACK资料的传送速度,并进而影响到下载速度,
2 试验证明,当上传满载时,下载速度变为原来速度的40%,甚至更低,,因为上载文件(包括ftp上传,发邮件SMTP),如果较大,一个的通讯量令带宽超 向包和,那么所有的数据包按照先进先出的原则进行排队和等待,这就可以解释为什么网内其中有人用ftp上载文件或发送大邮件的时候,整个网速变得很慢的原 因.
解决速度之道:
1 为了解决这些速度问题,对经过线路的数据进行了有规则的分流.把本来在宽带上的瓶颈转移到我们的LINUX路由器上,可以把带宽控制的比我们购买的带宽小一点. 这样,我们就可以方便的用tc技术对经过的数据进行分流与控制.
我们的想像就像马路上的车道一样,有高速道,还有小车道,大车道,需要高速的syn ack icmp ssh等走高速道,需要大量传输的ftp-data,smtp等走大车道,不能让它堵塞整条马路,各行其道.
linux下的TC(traffic control)就有这样的作用,只要控制得当,一定会有明显的效果.tc 和iptables结合是最好的简单运用的结合方法.
我 们设置过滤器以便用iptables对数据包进行分类,因为iptables更灵活,而且还可以为每个规则设置计数器,iptables用mangle链 来mark数据包,告诉了内核,数据包会有一个特定的FWMARK标记值(handle x fw) 表明它应该送给那个类(classid x:x),而prio是优先值,表明那些重要数据应该优先通过那个通道,首先选择队列(选择htb),
一般系统默认的是fifo的先进先出队列,就是说包是按照先来先处理的原则,如果有一个大的数据包在前面,那么后面的包只能等前面的发完后才能接着发了,这样就算后面既使是一个小小的ack包,也要等待了,这样上传就影响了下载,就算你有很大的下载带宽也无能为力.
HTB(Hierarchical token bucket,分层的令牌桶),就像CBQ一样工作,但是并不靠计算闲置时间来整形,它是一个分类的令牌桶过滤器.,它只有很少的参数.
结构简图: 1:
~~~~~~~~~~~~~~~~`~~~~~
~~~~~~~_________1:1~~~~~~~~~1:2________
|~~~|~~~~|~~~~|~~~~~|~~~~~~~~|~~~~~~~~|~~~~~~~|
1:11~~~1:12~~~~~~~~~~~~1:21~~~1:22~~~1:23~~1:24
优先顺序: 1:11 1:12 1:21 1:22 1:23 1:24
根据上面的例子,开始脚本:
关于参数的说明:
rate:是一个类保证得到的带宽值,如果有不只一个类,请保证所有子类总和是小于或等于父类,
ceil: ceil是一个类最大能得到带宽值.
prio: 是优先权的设置,数值越大,优先权越小,如果是分配剩余带宽,就是数值小的会最优先取得剩余的空闲的带宽权.
一般大数据的话,控制在50%-80%左右吧,而ceil最大建议不超过85%,以免某一个会话占用过多的带宽.
rate可按各类所需要分配:
1:11是很小而且最重要的数据包通道,当然要多分点,甚至必要时先全部占用,不过一般不会的,所以给全速.
1:12是很重要的数据道,给多点,最少给一半,但需要时可以再多一点
rate规划 1:2=1:21 +1:22 +1:23 +1:24 一般总在50%-80%左右.
1:21 http,pop是最常用的啦,为了太多人用,而导致堵塞,我们不能给得太多,也不能太少.
1:22 我打算给smtp用,优先低于1:21,以防发大的附件大量占用带宽.
1:23 我打算给ftp-data,和1:22一样,很可能大量上传文件,所以,rate不能给的太多,而当其他有剩时可以给大些,ceil设置大些.
1:24 是无所谓通道,就是一般不是我们平时工作上需要的通道,给小点防止这些人妨碍有正常工作需要的人.
上行uplink 320K,设置销低于理论值.
DEV=”PPP0″
UPLINK=300
下行downlink 3200K大概一半左右,以便能够得到更多的关发连接.
DOWNLINK=1500
1 曾加一个根队列,没有进行分类的数据包都走这个1:24是缺省类:
tc qdisc add dev $DEV parent 1: htb default 24
1.1 增加一个根队下面主干类1: 速率为$UPLINK k
tc cladd add dev $DEV parent 1: classid 1:1 htb rate ${UPLINK}kbit ceil ${UPLINK}kbit prio 0
1.1.1 在主干类1下建立第一叶子类,这是一个最高优先权的类,需要高优先和高速的包走这条通道,比如SYN ACK ICMP等.
tc class add dev $DEV parent 1:1 classid 1:11 htb rate ${$uplink}kbit ceil ${uplink}kbit prio 1
1.1.2 在主类1下建立第二叶子类,这是一个次高优先权的类,比如我们重要的CRM数据。
tc class add dev $DEV parent 1:1 classid 1:12 htb rate ${$uplink-150}kbit ceil ${uplink-50}kbit prio 2
1.2 在根类下建立次干类 classid 1:2 ,此次干类的下面全部优先权低于主干类,以防重要数据堵塞。
tc class add dev $DEV parent 1: classid 1:2 htb rate ${$UPLINK -150]kbit prio 3
1.2.1 在次干类下建立第一叶子类,可以跑例如http ,pop等。
tc class add dev $DEV parent 1:2 classid 1:21 htb rate 100kbit ceil ${$uplink -150}kbit prio 4
1.2.2 在次干类下建立第二叶子类,不要太高的速度,以防发大的附件大量占用带宽,便如smtp等。
tc class add dev $DEV parent 1:2 classid 1:22 htb rate 30kbit ceil ${uplink-160}kbit prio 5
1.2.3 在次干类下建立第三叶子类,不要太高的带宽,以防大量的数据堵塞网络,例如:ftp-data.
tc class add dev $DEV parent 1:2 classid 1:23 htb rate 15kbit ceil ${UPLINK-170}kbit prio 6
1.2.4 在次干类下建立第四叶子类。无所谓的数据通道,无需要太多的带宽,以防无所谓的人在阻碍正务。
tc class add dev $DEV parent 1:2 classid 1:24 htb rate 5kbit ceil ${UPLINK -250}kbit prio 7
在每个类下面再附加上另一个队列规定,随机公平队列(SFQ),不被某个连接不停占用带宽,以保证带宽的平均公平使用。
#SFQ(stochastic fairness queueing 随机公平队列),SFQ的关键词是“会话”(或称作流),主要针对一个TCP会话或者UDP流,流量被分成相当多数量的FIFO队列中,每个队列对应一个会话。
数据按照简单轮转的方式发送,每个会话都按顺序得到发送机会。这种方式非常公平,保证了每个会话都不会被其它会话所淹没,SFQ之所以被称为“随机”,是因为它并不是真的为每个会话创建一个队列,而是使用一个散列算法,把所有的会话映射到有限的几个队列中去。
#参数perturb是多少秒后重新配置一次散列算法,默认为10秒.
tc qdisc add dev $DEV parent 1:11 handle 111: sfq perturb 5
tc qidsc add dev $DEV parent 1:12 handle 112: sfq perturb 5
tc qdisc add dev $DEV parent 1:21 handle 121: sfq perturb 10
tc qidsc add dev $DEV parent 1:22 handle 122: sfq perturb 10
tc qidsc add dev $DEV parent 1:23 handle 123: sfq perturb 10
tc qidsc add dev $DEV parent 1:24 handle 124: sfq perturb 10
设置过滤器,handle是iptables作mark的值,让被iptables在mangle链做了mark的不同的值选择不同的通道classid,而prio是过滤器的优先级别
tc filter add dev $DEV parent 1:0 protocol ip prio 1 handle 1 fw classid 1:11
tc filter add dev $DEV parent 1:0 protocol ip prio 2 handle 2 fw classid 1:12
tc filter add dev $DEV parent 1:0 protocol ip prio 3 handle 3 fw classid 1:21
tc filter add dev $DEV parent 1:0 protocol ip prio 4 handle 4 fw classid 1:22
tc filter add dev $DEV parent 1:0 protocol ip prio 5 handle 5 fw classid 1:23
tc filter add dev $DEV parent 1:0 protocol ip prio 6 handle 6 fw classid 1:24
##################################################
##################################
下行的限制:
# 设置入队的规则,是因为把一些经常会造成下载大文件的端口进行控制,不让他们来得太快,导致堵塞,来得太快,就直接drop,就不会浪费和占用机器时间和力量去处理了.
1 把下行速率控制在大概1000-1500K(大约为带宽的50%),因为这个速度已经够用了,以便能够得到更多的并发下载连接.
tc qdisc add dev $DEV handle ffff: ingress
tc filter add dev $DEV parent ffff: protocol ip prio 50 handle 8 fw police rate ${downlink}kbit burst 10k drop flowid :8
如果内部网数据流不是很疯狂的话,就不用做下载的限制了,用#符号屏蔽上面两行既可.
如果要对任何进来的数据进行限速的话,可以用下面这句.
tc filter add dev $DEV parent ffff : protocol ip prio 10 u32 match ip src 0.0.0.0/0 police rate ${downlink}kbit burst 10k drop flowid :1
################################
开始给数据包打标记
把出去的不同类数据包(为dport)给mark上标记1—6,让它走不同的通道.
把进来的数据包(为sport)给mark上标记8,让它受到下行的限制,以免速度太快而影响全局.
每条规则下跟着return的意思是可以通过RETURN方法避免遍历所有的规则,加快了处理速度.
设置TOS的处理:
iptables -t mangle -A PREROUTING -m tos –tos Minimize-Delay -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -m tos –tos Minimize-Delay -j RETURN
iptables -t mangle -A PREROUTING -m tos –tos Minimize-Cost -j MARK –set-mark 4
iptables -t mangle -A PREROUTING –m tos –tos Minimize-Cost -j RETURN
iptables -t mangle -A PREROUTING -m tos –tos Maximize-Throughput -j MARK –set-mark 5
iptables -t mangle -A PREROUTING -m tos –tos Maximize-Througput -j RETURN
##提高TCP初始连接(也就是带有SYN的数据包)的优先权是非常明智的.
iptables -t mangle -A PREROUTING -p tcp -m tcp –tcp-flags SYN,RST,ACK SYN -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p tcp -m tcp –tcp-flags SYN,RST,ACK SYN -j RETURN
#想ICMP 想ping有良好的反应,放在第一类。
iptables -t mangle -A PREROUTING -p icmp -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -P icmp -j RETURN
#small packets (probably just ACKS)长度小于64的小包通常是需要快些的,一般是用来确认tcp的连接的,让它跟快些的通道吧。
iptables -t mangle -A PREROUTING -p tcp -m length –length :64 -j MARK –set-mark 2
iptables -t mangle -A PREROUTING -p tcp -m length –length:64 -j RETURN
#ftp放第二类,因为一般是小包,ftp-data放在第5类,因为一般是大时数据的传送。
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport ftp -j MARK –set-mark 2
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport ftp -j RETURN
iptables -t mangle -A PRETOUTING -p tcp -m tcp –dport ftp-data -j MARK –set-mark 5
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport ftp -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport ftp -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport ftp-data -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport ftp-data -j RETURN
###提高SSH数据包的优先权:放在第1类,要知道SSH是交互式的和重要的,不容待慢:
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 22 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport -j RETURN
##SMTP邮件,放在第4类,因为有时有人发送很大的邮件,为避免它堵塞,让它跑第4道吧
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 25 -j MARK –st-mark 4
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 25 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 25 -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 25 -j RETURN
##name-domain server:放在第1类,这样连接带有域名的连接才能快速找到对应有的地址,提高速度
iptables -t mangle -A PREROUTING -p udp -m udp –dport 53 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -P udp -m udp –dport 53 -j RETURN
###HTTP: 放在第3类,是最常用的,最多人用的
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 80 -j MARK –set-mark 3
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 80 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 80 -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 80 -j RETURN
###pop邮件放在第3类:
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 110 -j MARK –set-mark 3
iptables -t mangle -A PREROUTING -p tcp -m tcp –dprot 110 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 110 -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 110 -j RETURN
###MICSOSOFT-SQL-SERVE:放在第2类,我这里认为较重要,一定保证速度和优先的
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 1433 -j MARK –set-mark 3
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 1433 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 1433 -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 1433 -j RETURN
##https:放在第3类
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 443 -j MARK –set-mark 3
iptables -t mangle -A PREROUTING -p tcpm -m tcp –dport 443 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 443 -j MAKR –set-mark 8
iptables -t mangle -A PREROUTING -P tcp -m tcp –sport 443 -j RETURN
###voip用,提高,语音要保持高速才不会断续
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 1720 -j MARK–SET-MARK 1
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 1720 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 1720 -j MAKR –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 1720 -j RETURN
###VPN 用作voip的,也要走高速路,才不会断续
iptables -t mangle -A PREROUTING -p udp -m udp –dport 7707 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p udp -m udp –dport 7707 -j RETURN
###放在第1类,因为我觉得客观存在要我心中很重要,优行:
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 7070 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport -j RETURN
##提高本地数据包的优先权:放在第1类
iptables -t mangle -A OUTPUT -p tcp -m tcp –dport 22 -j MARK –set-mark 1
iptables -t mangle -A OUTPUT -p tcp -m tcp –dport 22 -j RETURN
iptables -t mangle -A OUTPUT -p icmp -j MARK –set-mark 1
iptables -t mangle -A OUTPUT -p icmp -j RETURN
###本地small packet (probably just ACKS)
iptables -t mangle -A OUTPUT -p tcp -m length –length :64 –set-mark 2
iptables -t mangle -A OUTPUT -p tcp -m length –length :64 -j RETURN
#################################################
## 向PRETOUTRIN中添加完mangle规则后,用这条规则结束prerouting表:也就是说前面没有打过标记的数据包就交给1:24来处理实际 上是不必要的,因为1:24是缺省类,但仍然打上标记是为了保持整个设置 的协调一致,而且这样,还能看到规则的数据包计数:
iptables -t mangle -A PREROUTING -i $DEV -j MARK –set-mark 6
###对某人限制:iptables -t mangle -I PREROUTING 1 -s 192.168.xx.xx -j MAKR –set-mark 6
###iptables -t mangle -I PREROUTING 2 -s 192.168.xx.xx -j RETURN
###################################################
u32的应用:
tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 …… 这就是所谓的u32匹配,可以匹配数据包的任意部分.
根据源/目的地址: match ip src 0.0.0.0/0
match ip dst 1.2.3.0/24
单个IP地址可以用/32来表示
根据源/目的端口可以这样表示: match ip sport 80 0xffff
match ip dport 80 0xffff
根据IP协议: match ip protocol (udp tcp icmp gre ipsec)
比如icmp协议是1 match ip protocol 1 0xff
举例:
tc filter add dev $DEV parent 1:0 protocol ip prio 1 u32 match ip dst 4.3.2.1/32 flowid 10:1
tc filter add dev $DEV parent 1:0 protocol ip prio 1
u32 match ip src 4.3.2.1/32 match ip sport 80 0xffff flowid 10:1
#!/bin/bash
#脚本文件名: tc2
#########################################################################################
#用TC(Traffic Control)解决ADSL宽带速度技术 Ver. 1.0 by KindGeorge 2004.12.27 #
#########################################################################################
#此脚本经过实验通过,更多的信息请参阅http://lartc.org
#tc+iptables+HTB+SFQ
#
#一.什么是ADSL? ADSL(Asymmetric Digital Subscriber Loop,非对称数字用户环路)
#用最简单的话的讲,就是采用上行和下行不对等带宽的基于ATM的技术.
#举例,我们最快的其中一条ADSL带宽是下行3200Kbit,上行只有320Kbit.带宽通常用bit表示.
#
#1、下行3200K 意味着什么?
#因为 1Byte=8Bit ,一个字节由8个位(bit)组成,一般用大写B表示Byte,小写b表示Bit.
#所以 3200K=3200Kbps=3200K bits/s=400K bytes/s.
#2、 上行320K 意味着什么?
# 320K=320Kbps=320K bits/s=40K bytes/s.
#就是说,个人所能独享的最大下载和上传速度,整条线路在没任何损耗,最理想的时候,
#下载只有400K bytes/s,上传只有最大40K bytes/s的上传网速.
#这些都是理想值,但现实总是残酷的,永远没有理想中那么好.至少也有损耗,何况内部网有几十台
#电脑一起疯狂上网.
#
#3.ADSL上传速度对下载的影响
#(1)TCP/IP协议规定,每一個封包,都需要有acknowledge讯息的回传,也就是说,传输的资料,
#需要有一个收到资料的讯息回复,才能决定后面的传输速度,並决定是否重新传输遗失
#的资料。上行的带宽一部分就是用來传输這些acknowledge(确认)資料模鄙闲懈涸毓?
#大的时候,就会影响acknowledge资料的传送速度,并进而影响到下载速度。这对非对称
#数字环路也就是ADSL这种上行带宽远小于下载带宽的连接来说影响尤为明显。
#(2)试验证明,当上传满载时,下载速度变为原来速度的40%,甚至更低.因为上载文件(包括ftp
#上传,发邮件smtp),如果较大,一个人的通讯量已经令整条adsl变得趋向饱和,那么所有的数据
#包只有按照先进先出的原则进行排队和等待.这就可以解释为什么网内其中有人用ftp上载文件,
#或发送大邮件的时候,整个网速变得很慢的原因。
#
#二.解决ADSL速度之道
#1. 为解决这些速度问题,我们按照数据流和adsl的特点,对经过线路的数据进行了有规则的分流.
#把本来在adsl modem上的瓶颈转移到我们linux路由器上,可以把带宽控制的比adsl modem上的小一点,
#这样我们就可以方便的用tc技术对经过的数据进行分流和控制.
#我们的想象就象马路上的车道一样,有高速道,还有小车道,大车道.需要高速的syn,ack,icmp等走
#高速道,需要大量传输的ftp-data,smtp等走大车道,不能让它堵塞整条马路.各行其道.
#2. linux下的TC(Traffic Control)就有这样的作用.只要控制得当,一定会有明显的效果.
#tc和iptables结合是最好的简单运用的结合方法.
#我们设置过滤器以便用iptables对数据包进行分类,因为iptables更灵活,而且你还可以为每个规则设
#置计数器. iptables用mangle链来mark数据包,告诉了内核,数据包会有一个特定的FWMARK标记值(hanlde x fw),
#表明它应该送给哪个类( classid x : x),而prio是优先值,表明哪些重要数据应该优先通过哪个通道.
#首先选择队列,cbq和htb是不错的选择,经过实验,htb更为好用,所以以下脚本采用htb来处理
#3. 一般系统默认的是fifo的先进先出队列,就是说数据包按照先来先处理的原则,如果有一个大的数
#据包在前面,#那么后面的包只能等前面的发完后才能接着发了,这样就算后面即使是一个小小的ack包,
#也要等待了,这样上传就影响了下载,就算你有很大的下载带宽也无能为力.
#HTB(Hierarchical Token Bucket, 分层的令牌桶)
#更详细的htb参考 http://luxik.cdi.cz/~devik/qos/htb/
#HTB就象CBQ一样工作,但是并不靠计算闲置时间来整形。它是一个分类的令牌桶过滤器。它只有很少的参数
#他的分层(Hierarchical)能够很好地满足这样一种情况:你有一个固定速率的链路,希望分割给多种不同的
#用途使用,为每种用途做出带宽承诺并实现定量的带宽借用。
#4. 结构简图:
#~~~~~~ |
#~~~~~ __1:__
#~~~~ |~~~~~ |
#~ _ _ _1:1~~~ 1:2_ _ _ _ _ _ _ _
# | ~ ~ | ~ ~ ~ | ~ ~ | ~ ~ | ~ ~ |
#1:11~1:12~~1:21~1:22~1:23~1:24
#优先顺序是1:11 1:12 1:21 1:22 1:23 1:24
#
#——————————————————————————————–
#5.根据上面的例子,开始脚本
#通常adsl用pppoe连接,的得到的是ppp0,所以公网网卡上绑了ppp0
#关于参数的说明
#(1)rate: 是一个类保证得到的带宽值.如果有不只一个类,请保证所有子类总和是小于或等于父类.
#(2)ceil: ceil是一个类最大能得到的带宽值.
#(3)prio: 是优先权的设置,数值越大,优先权越小.如果是分配剩余带宽,就是数值小的会最优先取得剩余
#的空闲的带宽权.
#具体每个类要分配多少rate,要根据实际使用测试得出结果.
#一般大数据的话,控制在50%-80%左右吧,而ceil最大建议不超过85%,以免某一个会话占用过多的带宽.
#rate可按各类所需分配,
#1:11 是很小而且最重要的数据包通道,当然要分多点.甚至必要时先全部占用,不过一般不会的.所以给全速.
#1:12 是很重要的数据道,给多点,最少给一半,但需要时可以再多一点.
#rate 规划 1:2 = 1:21 + 1:22 + 1:23 + 1:24 一般总数在50%-80%左右
#1:21 http,pop是最常用的啦,为了太多人用,而导致堵塞,我们不能给得太多,也不能太少.
#1:22 我打算给smtp用,优先低于1:21 以防发大的附件大量占用带宽,
#1:23 我打算给ftp-data,和1:22一样,很可能大量上传文件,所以rate不能给得太多,而当其他有剩时可以给大些,ceil设置大些
#1:24 是无所谓通道,就是一般不是我们平时工作上需要的通道了,给小点,防止这些人在妨碍有正常工作需要的人
#上行 uplink 320K,设置稍低于理论值
DEV=”ppp0″
UPLINK=300
#下行downlink 3200 k 大概一半左右,以便能够得到更多的并发连接
DOWNLINK=1500
echo “==================== Packetfilter and Traffic Control 流量控制 By 网络技术部 Ver. 1.0====================”
start_routing() {
echo -n “队列设置开始start……”
#1.增加一个根队列,没有进行分类的数据包都走这个1:24是缺省类:
tc qdisc add dev $DEV root handle 1: htb default 24
#1.1增加一个根队下面主干类1: 速率为$UPLINK k
tc class add dev $DEV parent 1: classid 1:1 htb rate ${UPLINK}kbit ceil ${UPLINK}kbit prio 0
#1.1.1 在主干类1下建立第一叶子类,这是一个最高优先权的类.需要高优先和高速的包走这条通道,比如SYN,ACK,ICMP等
tc class add dev $DEV parent 1:1 classid 1:11 htb rate $[$UPLINK]kbit ceil ${UPLINK}kbit prio 1
#1.1.2 在主类1下建立第二叶子类 ,这是一个次高优先权的类。比如我们重要的crm数据.
tc class add dev $DEV parent 1:1 classid 1:12 htb rate $[$UPLINK-150]kbit ceil ${UPLINK-50}kbit prio 2
#1.2 在根类下建立次干类 classid 1:2 。此次干类的下面全部优先权低于主干类,以防重要数据堵塞.
tc class add dev $DEV parent 1: classid 1:2 htb rate $[$UPLINK-150]kbit prio 3
#1.2.1 在次干类下建立第一叶子类,可以跑例如http,pop等.
tc class add dev $DEV parent 1:2 classid 1:21 htb rate 100kbit ceil $[$UPLINK-150]kbit prio 4
#1.2.2 在次干类下建立第二叶子类。不要太高的速度,以防发大的附件大量占用带宽,例如smtp等
tc class add dev $DEV parent 1:2 classid 1:22 htb rate 30kbit ceil $[$UPLINK-160]kbit prio 5
#1.2.3 在次干类下建立第三叶子类。不要太多的带宽,以防大量的数据堵塞网络,例如ftp-data等,
tc class add dev $DEV parent 1:2 classid 1:23 htb rate 15kbit ceil $[$UPLINK-170]kbit prio 6
#1.2.4 在次干类下建立第四叶子类。无所谓的数据通道,无需要太多的带宽,以防无所谓的人在阻碍正务.
tc class add dev $DEV parent 1:2 classid 1:24 htb rate 5kbit ceil $[$UPLINK-250]kbit prio 7
#在每个类下面再附加上另一个队列规定,随机公平队列(SFQ),不被某个连接不停占用带宽,以保证带宽的平均公平使用:
#SFQ(Stochastic Fairness Queueing,随机公平队列),SFQ的关键词是“会话”(或称作“流”) ,
#主要针对一个TCP会话或者UDP流。流量被分成相当多数量的FIFO队列中,每个队列对应一个会话。
#数据按照简单轮转的方式发送, 每个会话都按顺序得到发送机会。这种方式非常公平,保证了每一
#个会话都不会没其它会话所淹没。SFQ之所以被称为“随机”,是因为它并不是真的为每一个会话创建
#一个队列,而是使用一个散列算法,把所有的会话映射到有限的几个队列中去。
#参数perturb是多少秒后重新配置一次散列算法。默认为10
tc qdisc add dev $DEV parent 1:11 handle 111: sfq perturb 5
tc qdisc add dev $DEV parent 1:12 handle 112: sfq perturb 5
tc qdisc add dev $DEV parent 1:21 handle 121: sfq perturb 10
tc qdisc add dev $DEV parent 1:22 handle 122: sfq perturb 10
tc qdisc add dev $DEV parent 1:23 handle 133: sfq perturb 10
tc qdisc add dev $DEV parent 1:24 handle 124: sfq perturb 10
echo “队列设置成功.done.”
echo -n “设置包过滤 Setting up Filters……”
#这里设置过滤器,handle 是iptables作mark的值,让被iptables 在mangle链做了mark的不同的值选择不同的通
#道classid,而prio 是过滤器的优先级别.
tc filter add dev $DEV parent 1:0 protocol ip prio 1 handle 1 fw classid 1:11
tc filter add dev $DEV parent 1:0 protocol ip prio 2 handle 2 fw classid 1:12
tc filter add dev $DEV parent 1:0 protocol ip prio 3 handle 3 fw classid 1:21
tc filter add dev $DEV parent 1:0 protocol ip prio 4 handle 4 fw classid 1:22
tc filter add dev $DEV parent 1:0 protocol ip prio 5 handle 5 fw classid 1:23
tc filter add dev $DEV parent 1:0 protocol ip prio 6 handle 6 fw classid 1:24
echo “设置过滤器成功.done.”
########## downlink ##########################################################################
#6. 下行的限制:
#设置入队的规则,是因为把一些经常会造成下载大文件的端口进行控制,不让它们来得太快,导致堵塞.来得太快
#的就直接drop,就不会浪费和占用机器时间和力量去处理了.
#(1). 把下行速率控制在大概1000-1500k左右,因为这个速度已经足够用了,以便能够得到更多的并发下载连接
tc qdisc add dev $DEV handle ffff: ingress
tc filter add dev $DEV parent ffff: protocol ip prio 50 handle 8 fw police rate ${DOWNLINK}kbit burst 10k drop flowid :8
}
#(2).如果内部网数据流不是很疯狂的话,就不用做下载的限制了,用#符号屏蔽上面两行即可.
#(3).如果要对任何进来数据的数据进行限速的话,可以用下面这句:
#tc filter add dev $DEV parent ffff: protocol ip prio 10 u32 match ip src 0.0.0.0/0 police rate ${DOWNLINK}kbit burst 10k drop flowid :1
###############################################################################################
#7. 开始给数据包打标记,往PREROUTING链中添加mangle规则:
start_mangle() {
echo -n “开始给数据包打标记……start mangle mark……”
#(1)把出去的不同类数据包(为dport)给mark上标记1–6.让它走不同的通道
#(2)把进来的数据包(为sport)给mark上标记8,让它受到下行的限制,以免速度太过快而影响全局.
#(3)每条规则下根着return的意思是可以通过RETURN方法避免遍历所有的规则,加快了处理速度
##设置TOS的处理:
#iptables -t mangle -A PREROUTING -m tos –tos Minimize-Delay -j MARK –set-mark 1
#iptables -t mangle -A PREROUTING -m tos –tos Minimize-Delay -j RETURN
#iptables -t mangle -A PREROUTING -m tos –tos Minimize-Cost -j MARK –set-mark 4
#iptables -t mangle -A PREROUTING -m tos –tos Minimize-Cost -j RETURN
#iptables -t mangle -A PREROUTING -m tos –tos Maximize-Throughput -j MARK –set-mark 5
#iptables -t mangle -A PREROUTING -m tos –tos Maximize-Throughput -j RETURN
##提高tcp初始连接(也就是带有SYN的数据包)的优先权是非常明智的:
iptables -t mangle -A PREROUTING -p tcp -m tcp –tcp-flags SYN,RST,ACK SYN -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p tcp -m tcp –tcp-flags SYN,RST,ACK SYN -j RETURN
######icmp,想ping有良好的反应,放在第一类吧.
iptables -t mangle -A PREROUTING -p icmp -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p icmp -j RETURN
# small packets (probably just ACKs)长度小于64的小包通常是需要快些的,一般是用来确认tcp的连接的,
#让它跑快些的通道吧.也可以把下面两行屏蔽,因为再下面有更多更明细的端口分类.
iptables -t mangle -A PREROUTING -p tcp -m length –length :64 -j MARK –set-mark 2
iptables -t mangle -A PREROUTING -p tcp -m length –length :64 -j RETURN
#ftp放第2类,因为一般是小包, ftp-data放在第5类,因为一般是大量数据的传送.
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport ftp -j MARK –set-mark 2
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport ftp -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport ftp-data -j MARK –set-mark 5
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport ftp-data -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport ftp -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport ftp -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport ftp-data -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport ftp-data -j RETURN
##提高ssh数据包的优先权:放在第1类,要知道ssh是交互式的和重要的,不容待慢哦
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 22 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 22 -j RETURN
#
##smtp邮件:放在第4类,因为有时有人发送很大的邮件,为避免它堵塞,让它跑4道吧
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 25 -j MARK –set-mark 4
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 25 -j RETURN
#iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 25 -j MARK –set-mark 8
#iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 25 -j RETURN
## name-domain server:放在第1类,这样连接带有域名的连接才能快速找到对应的地址,提高速度的一法
iptables -t mangle -A PREROUTING -p udp -m udp –dport 53 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p udp -m udp –dport 53 -j RETURN
#
## http:放在第3类,是最常用的,最多人用的,
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 80 -j MARK –set-mark 3
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 80 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 80 -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 80 -j RETURN
##pop邮件:放在第3类
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 110 -j MARK –set-mark 3
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 110 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 110 -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 110 -j RETURN
## https:放在第3类
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 443 -j MARK –set-mark 3
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 443 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 443 -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 443 -j RETURN
## Microsoft-SQL-Server:放在第2类,我这里认为较重要,一定要保证速度的和优先的.
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 1433 -j MARK –set-mark 2
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 1433 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 1433 -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 1433 -j RETURN
## voip用, 提高,语音通道要保持高速,才不会断续.
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 1720 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 1720 -j RETURN
iptables -t mangle -A PREROUTING -p udp -m udp –dport 1720 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p udp -m udp –dport 1720 -j RETURN
## vpn ,用作voip的,也要走高速路,才不会断续.
iptables -t mangle -A PREROUTING -p udp -m udp –dport 7707 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p udp -m udp –dport 7707 -j RETURN
## 放在第1类,因为我觉得它在我心中很重要,优先.
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 7070 -j MARK –set-mark 1
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 7070 -j RETURN
## WWW caching service:放在第3类
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 8080 -j MARK –set-mark 3
iptables -t mangle -A PREROUTING -p tcp -m tcp –dport 8080 -j RETURN
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 8080 -j MARK –set-mark 8
iptables -t mangle -A PREROUTING -p tcp -m tcp –sport 8080 -j RETURN
##提高本地数据包的优先权:放在第1
iptables -t mangle -A OUTPUT -p tcp -m tcp –dport 22 -j MARK –set-mark 1
iptables -t mangle -A OUTPUT -p tcp -m tcp –dport 22 -j RETURN
iptables -t mangle -A OUTPUT -p icmp -j MARK –set-mark 1
iptables -t mangle -A OUTPUT -p icmp -j RETURN
#本地small packets (probably just ACKs)
iptables -t mangle -A OUTPUT -p tcp -m length –length :64 -j MARK –set-mark 2
iptables -t mangle -A OUTPUT -p tcp -m length –length :64 -j RETURN
#(4). 向PREROUTING中添加完mangle规则后,用这条规则结束PREROUTING表:
##也就是说前面没有打过标记的数据包将交给1:24处理。
##实际上是不必要的,因为1:24是缺省类,但仍然打上标记是为了保持整个设置的协调一致,而且这样
#还能看到规则的包计数。
iptables -t mangle -A PREROUTING -i $DEV -j MARK –set-mark 6
echo “标记完毕! mangle mark done!”
}
#—————————————————————————————————–
#8.取消mangle标记用的自定义函数
stop_mangle() {
echo -n “停止数据标记 stop mangle table……”
( iptables -t mangle -F && echo “ok.” ) || echo “error.”
}
#9.取消队列用的
stop_routing() {
echo -n “(删除所有队列……)”
( tc qdisc del dev $DEV root && tc qdisc del dev $DEV ingress && echo “ok.删除成功!” ) || echo “error.”
}
#10.显示状态
status() {
echo “1.show qdisc $DEV (显示上行队列):———————————————-”
tc -s qdisc show dev $DEV
echo “2.show class $DEV (显示上行分类):———————————————-”
tc class show dev $DEV
echo “3. tc -s class show dev $DEV (显示上行队列和分类流量详细信息):——————”
tc -s class show dev $DEV
echo “说明:设置总队列上行带宽 $UPLINK k.”
echo “1. classid 1:11 ssh、dns、和带有SYN标记的数据包。这是最高优先权的类包并最先类 ”
echo “2. classid 1:12 重要数据,这是较高优先权的类。”
echo “3. classid 1:21 web,pop 服务 ”
echo “4. classid 1:22 smtp服务 ”
echo “5. classid 1:23 ftp-data服务 ”
echo “6. classid 1:24 其他服务 ”
}
#11.显示帮助
usage() {
echo “使用方法(usage): `basename $0` [start | stop | restart | status | mangle ]”
echo “参数作用:”
echo “start 开始流量控制”
echo “stop 停止流量控制”
echo “restart 重启流量控制”
echo “status 显示队列流量”
echo “mangle 显示mark标记”
}
#———————————————————————————————-
#12. 下面是脚本运行参数的选择的控制
#
kernel=`eval kernelversion`
case “$kernel” in
2.2)
echo ” (!) Error: won’t do anything with 2.2.x 不支持内核2.2.x”
exit 1
;;
2.4|2.6)
case “$1” in
start)
( start_routing && start_mangle && echo “开始流量控制! TC started!” ) || echo “error.”
exit 0
;;
stop)
( stop_routing && stop_mangle && echo “停止流量控制! TC stopped!” ) || echo “error.”
exit 0
;;
restart)
stop_routing
stop_mangle
start_routing
start_mangle
echo “流量控制规则重新装载!”
;;
status)
status
;;
mangle)
echo “iptables -t mangle -L (显示目前mangle表表标记详细):”
iptables -t mangle -nL
;;
*) usage
exit 1
;;
esac
;;
*)
echo ” (!) Error: Unknown kernel version. check it !”
exit 1
;;
esac

















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









