









因部门内一部分写c++而不会java的人想要将他们的程序改写成mapreduce程序运行在hadoop上,故作了几个简单的例子作说明。
本篇是hadoop streaming运行c++。
如果要在hadoop上运行C++ mapreduce程序,有三种解决方案:
- 使用JNI/JNA/JNR技术。这三种Java外部函数接口技术都是解决在Java程序中运行C++功能函数的需求,从而使得在Hadoop平 台下开发Java程序且能调用C++函数完成在Hadoop Java版应用中运行C++程序的目的。
- 用Hadoop Streaming技术。这项技术可以使得除了Java之外的多种其它语言如C/C++/Python/C#甚至shell脚本等运行在 Hadoop平台下,程序只需要按照一定的格式从标准输入读取数据、向标准输出写数据就可以在Hadoop平台上使用,原有的单机程序稍加改动就可以在 Hadoop平台进行分布式处理。
- 使用Hadoop Pipes技术。该技术只专注于在Hadoop平台下运行C++程序,只允许用户使用C++语言进行MapReduce程序设计。它采用的主要方法是将应用逻辑相关的C++代码放在单独的进程中,然后通过Socket让Java代码与 C++代码通信。从很大程度上说,这种方法类似于Hadoop Streaming,不同之处是通信方式不同:Streaming是标准输入输出,Pipes是socket。
在这里简单介绍hadoop streaming运行c++ mapreduce:
1、数据文件streamingtestdata.txt
zhangsan 15
lisi 15
zhangsan 16
lisi 16
wangwu 14
zhangsan 15
lisi 16以空格分开,将数据文件放入hdfs上:
hadoop fs -put /TestData/streamingtestdata.txt /OutTestData/streamingtestdata.txt2、c++的map程序——mapper.cpp
#include <string>
#include <iostream>
using namespace std;
int main(int argc, char** argv)//mapper将会被封装成一个独立进程,因而需要有main()函数
{
string name,age;
//读入姓名、年龄
while(cin >> name >> age)
{
//输出姓名、年龄、人数
cout << name << " " << age << " " << "1" << endl;
}
return 0;
}3、C++的reduce程序——reducer.cpp
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main(int argc, char** argv)//Reducer将会被封装成一个独立进程,因而需要有main()函数
{
string key, value;
int num;
//个数统计
map<string,int> count_stat;
map<string,int>::iterator it_count_stat;
//读入数据并插入map
while(cin >> key >> value >> num)
{
string tmp_key = key + " " + value;
//插入数据
it_count_stat = count_stat.find(tmp_key);
if(it_count_stat != count_stat.end())
{
(it_count_stat->second)++;
}
else
{
count_stat.insert(make_pair(tmp_key, 1));
}
}
//输出统计结果
for(it_count_stat = count_stat.begin(); it_count_stat != count_stat.end(); it_count_stat++)
{
cout<<it_count_stat->first<<" "<<it_count_stat->second<<endl;
}
return 0;
}4、编译map和reduce程序

5、本地测试

6、hadoop streaming运行
以空格’ ‘作为分隔符,并以前两个字段作为key,reduce任务3个:

运行成功:

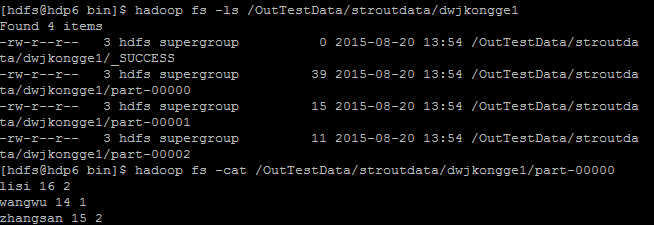
7、查看结果数据:















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









