






Iptables:
关于filter和nat:
以下内容来自于: http://www.zsythink.net/?s=iptables,建议看原作者的链接 ,讲的特别好,我这里只是记录笔记。
2019/03/24更新:关于iptables的netfilter后续,常用ACL(访问控制列表)来控制路由器接口对某个ip段或tcp段的访问,也就是告诉路由器哪些数据允许出入,哪些数据拒绝出入。一个ACL中有多个rule时,冲突时rule标号小的命令有效。
例:
[R1]rip
[R1-rip-1]version 2
[R1-rip-1]nerwork 192.168.1.0
[R1-rip-1]network 192.168.4.0
[R1]acl 3000
[R1-acl-adv-3000]rule 20 permit ip source 192.168.1.1 0 destination 192.168.2.0 0.0.0.255 //在R1中创建ACL 3000,设置允许访问192.168.2.0网络
[R3]acl 3000
[R3-acl-adv-3000]rule 10 permit tcp source 192.168.1.1 0 destination 192.168.3.10 destination-port eq 80 //允许客户端访问服务器的WEB服务
[R3-acl-adv-3000]rule 20 deny ip source 192.168.1.1 0 destination 192.168.3.1 0//禁ping
[R3-GigabitEthernet0/0/0]traffic-filter inbound acl 3000 //进方向打开ACL,3000是扩展的网卡->协议栈->用户空间的web服务
网卡->协议栈->其他主机
每个链上的规则都存在于一些表中。
一共有四种表:filter表、nat表、mangle表和raw表。
规则由匹配条件和处理动作组成。

匹配条件:
基本匹配条件:源地址ip、目的地址ip
扩展匹配条件:源端口、目的端口
处理动作:ACCEPT、DROP、REJECT、SNAT(源地址转换)、MASQUERADE、DNAT(目的地址转换)、REDIRECT(本机做端口映射)、LOG(记录之后传递给下一条规则)
filter表中的规则可以被哪些链使用:INPUT、FORWARD、OUTPUT
nat表中的规则可以被哪些链使用:PREROUTING、OUTPUT、(POSTROUTING)
mangle表中的规则可以被哪些链使用:PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING
raw表中的规则可以被哪些链使用:PREROUTING、OUTPUT
iptables命令小结:
iptables -t filter -nvxL (链名如INPUT)//不使用-t命令则默认操作filter(过滤)表。
iptables (-t filter) -I INPUT -s 192.168.1.146 -j DROP//在156的主机上配置一条规则:拒绝146上的
所有报文访问当前机器。这样用146去ping156的主机发现没有结果。(-I是加在最前面,-A是加在最后面,先匹配
前面的规则再匹配后面的,因此如果加了拒绝又想再接受的话就需要在拒绝之前添加接受才可以成功)
iptables -I INPUT -s 192.168.1.146 -j ACCEPT
iptables --line -vnL INPUT //显示INPUT链的行号
iptables -t filter -D INPUT 3 //删除INPUT链的第三条规则
iptables -t 表名 -F 链名 //删除此链中的所有操作-R命令进行修改的时候-s不能省略。
iptables -t filter -R INPUT 1 -s 192.168.1.146 -j REJECT//将DROP修改为REJECT
service iptables save//ubuntu的在使用--dport之前一定要选定-p,也就是协议。
如:iptables -t filter -I INPUT -s 192.168.1.146 -p tcp (-m tcp)可省略 --dport 22 -j REJECT扩展模块:iprange(--src-range、--dst-range)
iptables -t filter -I INPUT -m iprange --src-range 192.168.1.127-192.168.1.146 -j DROPstring(--algo bm、--algo kmp)
iptables -t filter -I INPUT -m string --algo bm --string "OOXX" -j REJECT
time(--timestart、--timestop、weekdays、monthdays、datestart、datestop)
iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --timestart 09:00:00 --timestop
18:00:00 -j REJECT//约束自己每天上午9点到下午6点不能看网页
iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --weekdays 6,7 -j REJECT//周六日不
能看网页
同时的话是与的关系相当于:
iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --timestart 09:00:00 --timestop
18:00:00 --weekdays 6,7 -j REJECT
iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --datestart 2017-12-24 --datestop
2017-12-27 -j REJECT
connlimit(--connlimit-above 2)
limit(--limit 10/minute)限制ping的速率和数量,令牌桶算法
--tcp-flags
TCP的flags有C E U A P R S F
模拟第一次握手:
iptables -t filter -I INPUT -p tcp -m tcp -dport 22 --tcp-flags ALL SYN -j REJECT
iptables -t filter -I INPUT -p tcp -m tcp -dport 22 --tcp-flags SYN,ACK,FIN,RST,URG,PSH SYN -j REJECT
模拟第二次握手:
iptables -t filter -I INPUT -p tcp -m tcp -sport 22 --tcp-flags ALL SYN,ACK -j REJECT
-m udp扩展:适合udp端口
-m icmp(--icmp-type)扩展:
iptables -t filter -I INPUT -p icmp -j REJECT//我们无法ping通别人别人也无法ping通我们
iptables -t filter -I INPUT -p icmp --icmp-type 8/0 -j REJECT//我们能ping别人但别人不能ping
我们
-m state扩展:
报文一般来说有五种状态:
NEW、ESTABLISH、RELATED、INVALID、UNTRACKED
如果不希望收到外来的主动连接我们一般只要开通ESTABLISH和RELATED状态就好。
iptables -t filter -I INPUT -m state RELATED,ESTABLISH -j ACCEPT
设置黑白名单要修改默认的设置时最好使用-A,而不是-I,这样做了-F操作以后还能回到之前。也就是
iptables -P INPUT DROP改为iptables -A INPUT -j REJECT自定义链:
iptables -t filter -N IN_WEB自定义一条只管理80端口的链,可用iptables -nvL查看引用情况。给这条链设置规则跟INPUT、OUTPUT没什么区别。
现在用INPUT链去引用他:
iptables -I INPUT -p tcp --dport 80 -j IN_WEB,
这时候iptables -nvL发现一条引用。-j用于指定动作。
-E给链改名:iptables -t filter -E IN_WEB WEB
-X删除自定义链:
iptables -t filter -D INPUT 1
iptables -F WEB
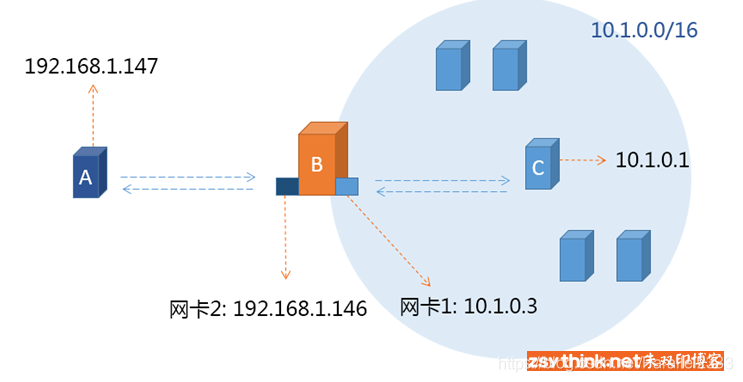
iptables -X WEBLinux主机默认不开启转发模式,这也就是平时能ping通内网网关ip而ping不通内网主机的原因,因为网关根本就没有将包进行转发给到内网主机。因此我们需要在主机B配置开启转发功能。需要在FORWARD链进行双向放行,这样可以传达出去也可以响应回来。
iptables -I FORWARD -s 10.1.0.0/16 -p tcp --dport 80 -j ACCEPT
iptables -I FORWARD -d 10.1.0.0/16 -p tcp --sport 80 -j ACCEPT
放行所有响应报文:
iptables -I FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
接着只用考虑请求报文的方向,我们要让内部能够向外请求sshd,则是
iptables -I FORWARD -s 10.1.0.0/16 -p tcp --dport 22 -j ACCEPT,也就是主机C可以访问主机A的22端口。SNAT动作:
iptables -t nat -A POSTROUTING -s 10.1.0.0/16 -j SNAR --to-source 192.168.1.146
可用iptables -t nat -nvL来查看
SNAT规则只能存在于POSTROUTING链(看版本:或者INPUT链中)
清空nat表:iptables -t nat -FDNAT动作:
iptables -t nat -I PREROUTING -d 192.168.1.146 -p tcp --dport 3389 -j DNAT --to-destination 10.1.0.6:3389
同时最好开启SNAT,也就是:
iptables -t nat -A POSTROUTING -s 10.1.0.0/16 -j SNAT --to-resource 192.168.1.146DNAT用法也相当于
iptables -t nat -I PREROUTING -d 192.168.1.146 -p tcp --dport 801 -j DNAT --to-destination 10.1.0.1:80这里等价于将对801端口的访问转发到10.1.0.1的80端口上。
DNAT规则只定义在PREROUTING链和OUTPUT链中。
SNAT也就是源地址转换,常见于局域网访问互联网,DNAT也就是目的地址转换,常见于企业内部发布到互联网。由于是涉及到目标地址,所以需要端口号,传输去到特定的服务中。
还有MASQUERADE(动态SNAT地址,如果没需求不要用,因为SNAT更高效)
REDIRECT(重定向)
关于mangle:https://blog.csdn.net/lee244868149/article/details/45113585
//假设eth0是靠近内网的网关,eth1是20.0.0.1的网关,eth2是10.0.0.1的网关,默认走eth1,在192.168.10.1-192.168.10.100范围
内的主机走eth2:
ip route add default gw 20.0.0.1//路由表定义默认网关
ip route add table 10 via 10.0.0.1 dev eth2//路由表定义特定情况下的网关
ip rule add fwmark 10 table 10//将路由表和特定的标记关联起来
iptables -A PREROUTING -t mangle -i eth0 -s 192.168.10.1-192.168.10.100 -j MARK --set-mark 10//标记什么情况下走路由
表10的数据包关于raw:raw表主要用于解决链接数量过大的问题降低负载或一些其他原因屏蔽追踪。
1.web服务器负载过重解决方案:
//vi /etc/sysctl.conf:
(1)加大ip_conntrack_max值
(2)降低ip_conntrack timeout时间
net.ipv4.netfilter.ip_conntrack_tcp_timeout_established
net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait
net.ipv4.netfilter.ip_conntrack_tcp_timeout_close_wait
net.ipv4.netfilter.ip_conntrack_tcp_timeout_fin_wait
(3)iptables -t raw -A PREROUTING -p tcp --dport 80 -j NOTRACK
iptables -t raw -A PREROUTING -p tcp --sport 80 -j NOTRACK
iptables -A FORWARD -m state --state UNTRACKED -j ACCEPT2.跟踪调试数据包:
iptables -t raw -A OUTPUT -p icmp -j TRACE
iptables -t raw -A PREROUTING -p icmp -j TRACE
加载对应内核模组:modprobe ipt_LOG//调试信息在/var/log/kern.log
然后开始ping外部网址去log中查看对应信息。
可以看到数据包在哪个部分被截断,如果nat表截断就去nat的规则里查看问题所在。说到track就不得不提MARK,用于给数据包或数据链路打标记。MARK只能在mangle链上,用于打标记,前面也用了set-mark去路由不同标记的数据包去到不同的网关:
MARK流程:
iptables -A POSTROUTING -t mangle -j CONNMARK --restore-mark//如果有save-mark操作则将标记记录到数据包中。
iptables -A POSTROUTING -t mangle -m mark ! --mark 0 -j ACCEPT//接受所有打了标记的数据包
iptables -A POSTROUTING -m mark --mark 0 -p tcp --dport 21 -t mangle -j MARK --set-mark 1
iptables -A POSTROUTING -m mark --mark 0 -p tcp --dport 80 -t mangle -j MARK --set-mark 2
iptables -A POSTROUTING -m mark --mark 0 -t mangle -p tcp -j MARK --set-mark 3//三种标记操作
iptables -A POSTROUTING -t mangle -j CONNMARK --save-mark//将标记保存,这样当该链的下一个数据包走到第一条规则时,就会
被打上标记并命中第二步的ACCEPTtc:内容取自:https://blog.csdn.net/u011641885/article/details/45640313/
流量控制器上的以太网卡(eth0)的IP地址为 192.168.1.66, 在其上建立一个CBQ队列。
假设包的平均大小为1000字节,包间隔发送单元的大小为8字节,可接收冲突的发送最长包的数目为20字节。加入有三种类型的流量需要控制:
1)是发往主机1的,其IP地址为192.168.1.24。其流量带宽控制在8Mbit,优先级为 2;
2)是发往主机2的,其IP地址为192.168.1.30。其流量带宽控制在1Mbit,优先级为1;
3)是发往子网1的,其子网号为192.168.1.0。子网掩码为255.255.255.0。流量带宽控制在1Mbit,优先级为6。
建立队列:
tc qdisc add dev eth0 root handle 1: cbq bandwidth 10Mbit avpkt 1000 cell 8 mpu 64
建立分类:
tc class add dev eth0 parent 1:0 classid 1:1 cbq bandwidth 10Mbit rate 10Mbit maxburst 20 allot 1514 prio 8
avpkt 1000 cell 8 width 1Mbit
tc class add dev eth0 parent 1:1 classid 1:2 cbq bandwidth 10Mbit rate 8Mbit maxburst 20 allot 1514 prio 2
avpkt 1000 cell 8 weight 800Kbit split 1:0 bounded//split是分类的分离点
tc class add dev eth0 parent 1:1 classid 1:3 cbq bandwidth 10Mbit rate 1Mbit maxburst 20 allot 1514 prio 1
avpkt 1000 cell 8 weight 100Kbit split 1:0
tc class add dev eth0 parent 1:1 classid 1:4 cbq bandwidth 10Mbit rate 1Mbit maxburst 20 allot 1514 prio 6
avpkt 1000 cell 8 weight 100Kbit split 1:0
建立过滤器:
tc filter add dev eth0 parent 1:0 protocol ip prio 100 route
tc filter add dev eth0 parent 1:0 protocol ip prio 100 route to 2 flowid 1:2
tc filter add dev eth0 parent 1:0 protocol ip prio 100 route to 3 flowid 1:3
tc filter add dev eth0 parent 1:0 protocol ip prio 100 route to 4 flowid 1:4
建立路由:
ip route add 192.168.1.24 dev eth0 via 192.168.1.66 realm 2
ip route add 192.168.1.30 dev eth0 via 192.168.1.66 realm 3
ip route add 192.168.1.0/24 dev eth0 via 192.168.1.66 realm 4
监视:
tc -s qdisc ls dev eth0
tc -s class ls dev eth0
tc -s filter ls dev eth0
ip route
网络协议栈:https://blog.csdn.net/zqixiao_09/article/list/2 博客里主要讲了关于二层、三层和netfilter。
二层桥:涉及到ARP表和交换表的自学习,找不到的通过ARP广播出去再单播回来即可。
路由交换表记录的是路由器(需开启混杂模式)的网卡eth和MAC,而ARP记录的是MAC和IP。
带VLAN的二层转发可以在VLAN组里进行广播,也就是一个VLAN组是一个广播域,不同VLAN需要三层转发进行互通,二层是互通不了的。
三层链路:邻居子系统在L2.5层,ARP协议就是邻居子系统架构的一种实现,负责探测ip和mac的邻居。网桥端口和vlan子接口是建立在物理接口上的虚拟接口,他们通过软件产生了br0、vlan0这种名字后最终还是会转化到eth0等接口上面去。链路层实现了网桥端口、vlan子接口、邻居子系统、网卡驱动和协议栈上层接口、L2隧道功能、以太网类型实现的链路层协议收发报文(vlan_skb_recv、ip_rcv、arp_recv、原始套接字packet_recv等)。发送到接口通过dev_queue_xmit、接收进来netif_receive_skb。
AF_INET(PF_INET)的序号为2,因此PRE_ROUTING的钩子函数挂载点是nf_hooks[2][0]
NF_IP_PRE_ROUTING:nf_hooks[2][0],ip_rcv() ip_rcv_finish()
NF_IP_LOCAL_IN:nf_hooks[2][1],ip_local_deliver() ip_local_deliver_finish()
NF_IP_FORWARD:nf_hooks[2][2],ip_forward() ipmr_queue_xmit()//多播相关
NF_IP_LOCAL_OUT:nf_hooks[2][3],ip_queue_xmit() ip_bulid_and_send_pkt()
NF_IP_POST_ROUTING:nf_hooks[2][4],ip_finish_output() ip_finish_output2() ip_mc_output()//克隆新的网络缓存skb
hook机制:NF_HOOK->nf_hook_slow()->nf_hookfn->okfn
nf_hook_slow()函数接收协议簇和Hook类型,根据这两个要素从nf_hooks中获得对应的前面注册好的Hook链表首部:
elem = &nf_hooks[pf][hook];
然后调用nf_iterate,遍历Hook链表,调用链表上所有的Hook函数。
#define NF_DROP 0
#define NF_ACCEPT 1
#define NF_STOLEN 2
#define NF_QUEUE 3//进入用户空间
#define NF_REPEAT 4
#define NF_STOP 5
接着就是路由转发问题等等。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









