







elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库。
安装步骤:
1、到github网站下载源代码,网站地址为:https://github.com/medcl/elasticsearch-analysis-ik
右侧下方有一个按钮“Download ZIP”,点击下载源代码elasticsearch-analysis-ik-master.zip。
2、解压文件elasticsearch-analysis-ik-master.zip,进入下载目录,执行命令:
unzip elasticsearch-analysis-ik-master.zip
3、将解压目录文件中config/ik文件夹复制到ES安装目录config文件夹下。
4、因为是源代码,此处需要使用maven打包,进入解压文件夹F:\elasticsearch-analysis-ik-1.8.0\elasticsearch-analysis-ik-1.8.0中,执行命令:
mvn clean package
打包的时候比较慢,需要找个网速快的地方
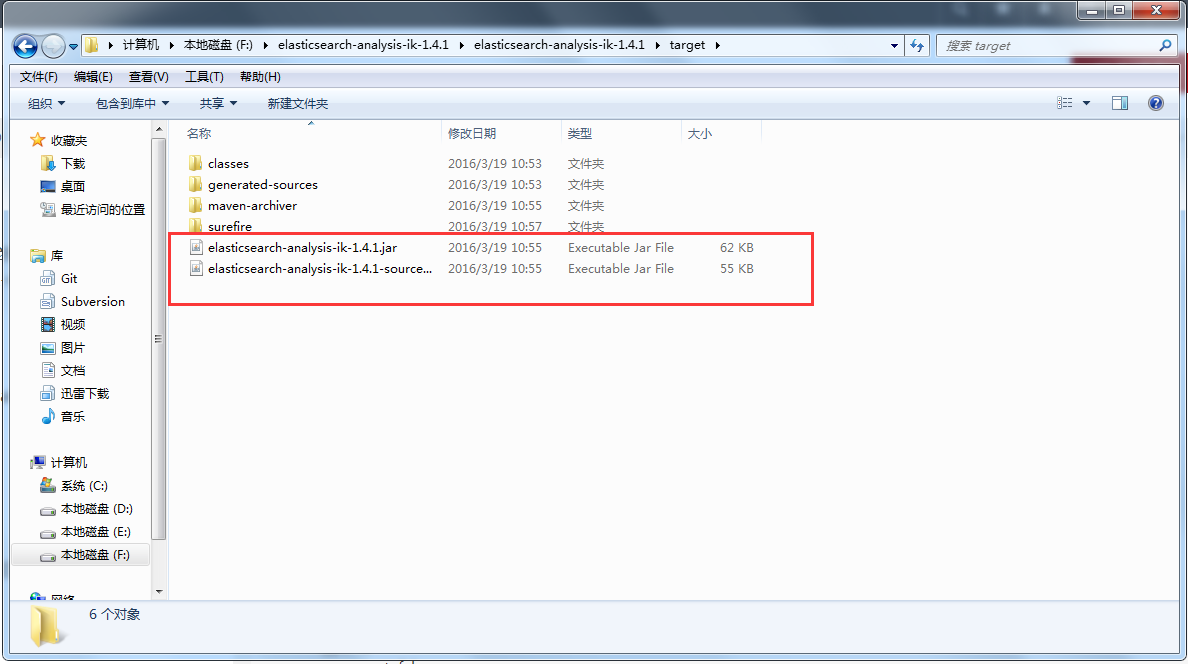
打包完多个target文件
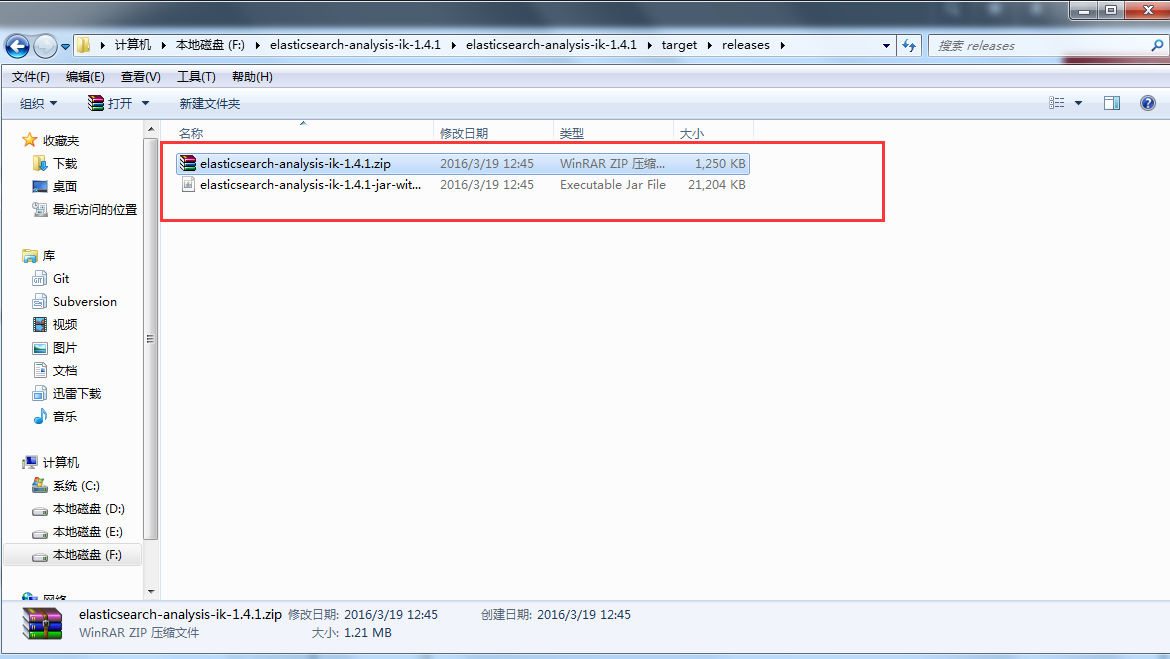
cd target/releases/
就会看到 elasticsearch-analysis-ik-1.4.1.zip和elasticsearch-analysis-ik-1.4.1-jar-with-dependencies.jar
把elasticsearch-analysis-ik-1.4.1.zip 解压到 ES/plugins/analysis-ik/
5、将打包得到的jar文件elasticsearch-analysis-ik-1.4.1-jar-with-dependencies.jar复制到ES安装目录的lib目录下。
6、在ES的配置文件config/elasticsearch.yml中增加ik的配置,在最后增加:
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_max_word:
type: ik
use_smart: false
ik_smart:
type: ik
use_smart: true或
index.analysis.analyzer.ik.type : “ik”
注:
以上两种配置方式的区别:
a.第二种方式,只定义了一个名为 ik 的 analyzer,其 use_smart 采用默认值 false
b.第一种方式,定义了三个 analyzer,分别为:ik、ik_max_word、ik_smart,其中 ik_max_word 和 ik_smart 是基于 ik 这个 analyzer 定义的,并各自明确设置了 use_smart 的不同值。
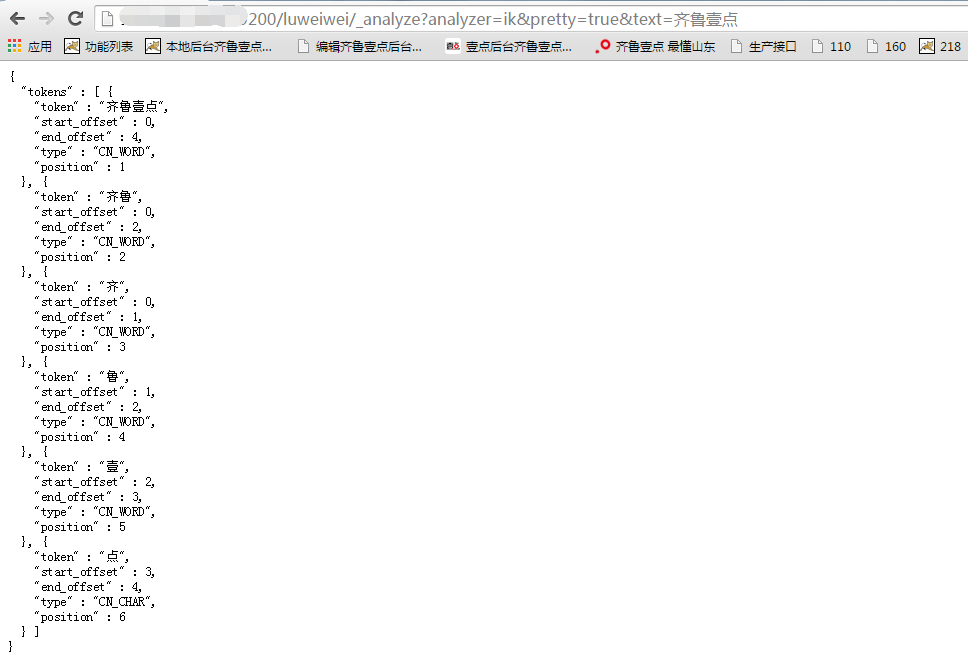
其实,ik_max_word 等同于 ik。ik_max_word 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;而 ik_smart 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
因此,建议在设置 mapping 时,用 ik 这个 analyzer,以尽可能地被搜索条件匹配到。
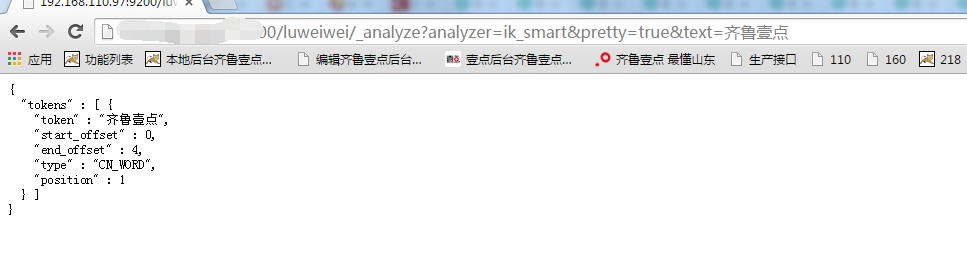
不过,如果你想将 /index_name/_analyze 这个 RESTful API 做为分词器用,用来提取某段文字中的主题词,则建议使用 ik_smart 这个 analyzer;
使用ik和ik_max_word 效果一样:
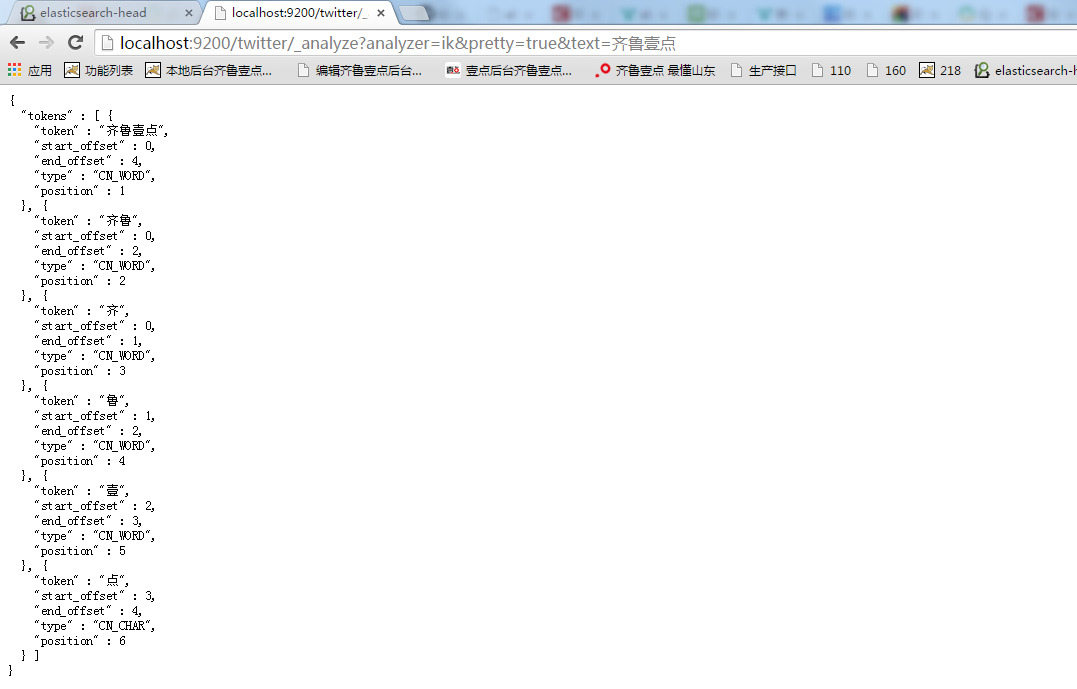
使用ik_smart (将’齐鲁壹点’ 加入词典)
7、重新启动elasticsearch服务,这样就完成配置了,收入命令:
http://localhost:9200/twitter/_analyze?analyzer=ik_smart&pretty=true&text=%E9%BD%90%E9%B2%81%E5%A3%B9%E7%82%B9
注:pretty=true表示格式化输出
注: twitter是索引名称















 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









