






点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
潮平两岸阔,风正一帆悬。
1. 为"你"而写
这篇文章,是专门为那些 "刚学习" Python爬虫的朋友,而专门准备的文章。希望你看过这篇文章后,能够清晰的知道整个 "爬虫流程"。从而能够 "独立自主" 的去完成,某个简单网站的数据爬取。

好了,咱们就开始整个 “爬虫教学” 之旅吧!
2. 页面分析
① 你要爬取的网站是什么?
首先,我们应该清楚你要爬去的网站是什么?
由于这里我们想要爬取的是 “实习网” 中的数据,因此我们可以打开这个网站看看(如图所示)。
网站链接:https://www.shixi.com/search/index?
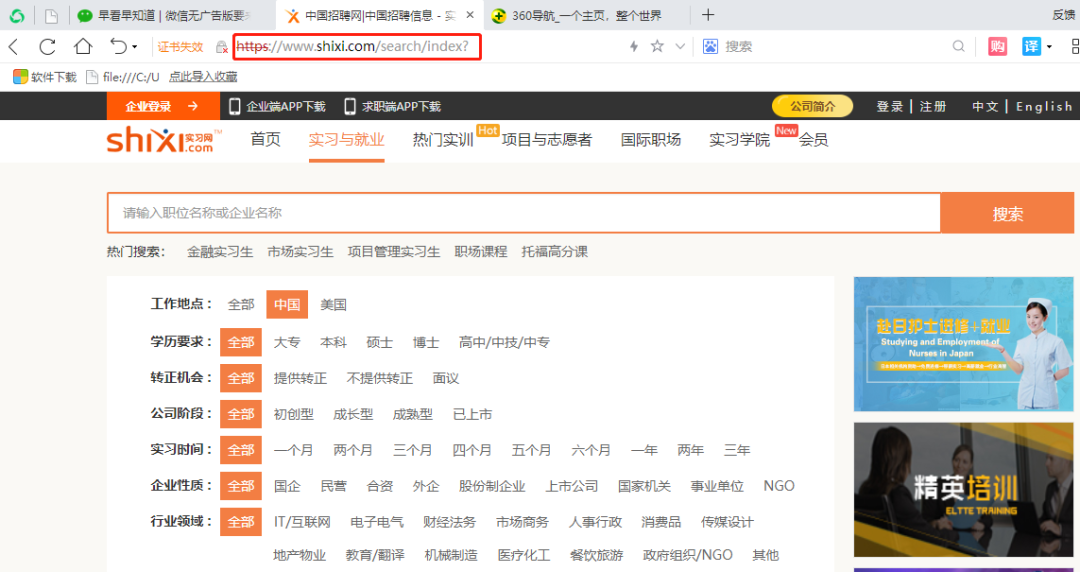
由于我们想要爬取 “数据分析” 岗位的数据。因此,直接在输入框输入数据分析即可。
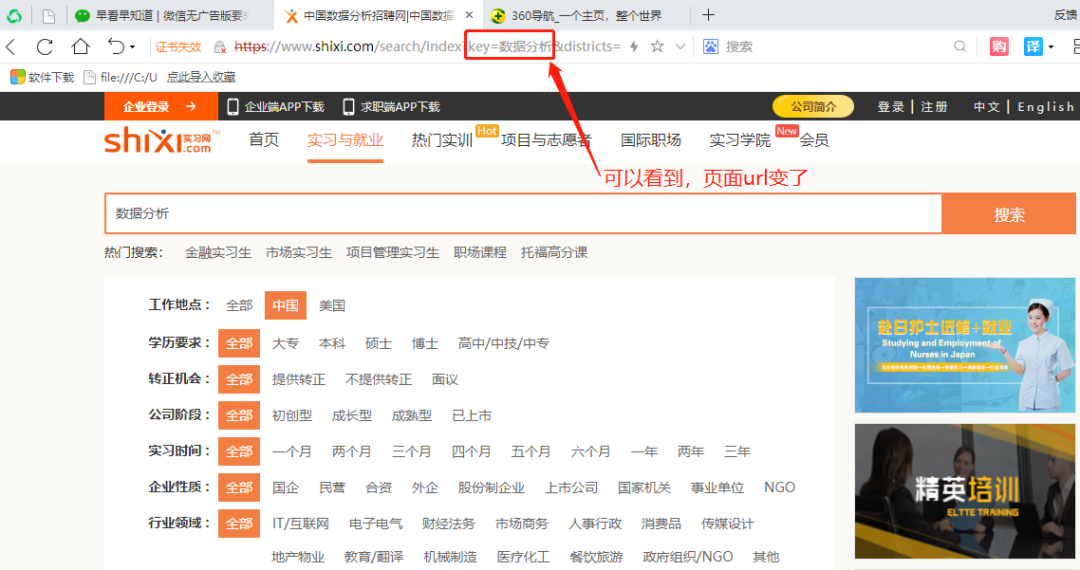
这里是我们要的最终页面链接。????????待爬取链接:
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90
观察下图,可以清楚看到有哪些数据,下面还有页面信息。我们需要了解这些: 一个页面中共有多少条数据。这个很重要,后面可以帮你检查,是否爬取到了每个页面的所有信息。
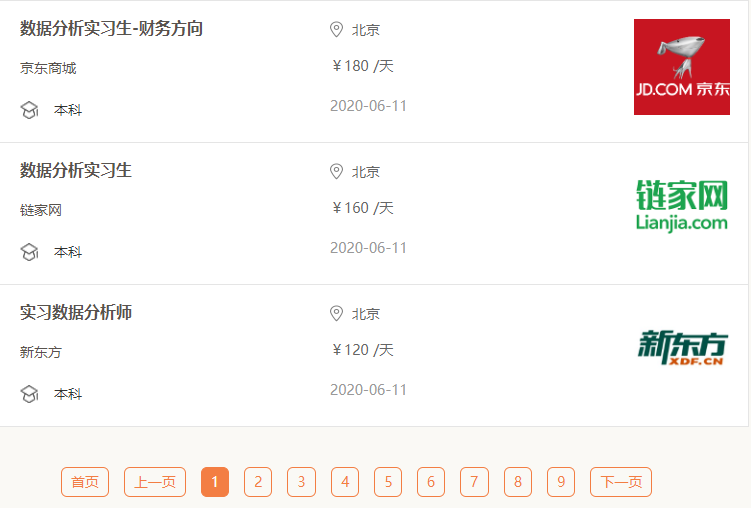
图中显示的是 “一级页面” 中的信息,点击任意一个 “岗位名”,会自动跳转到 “二级页面”。以点击 “数据分析实习生” 为例,原来二级页面是这样的。
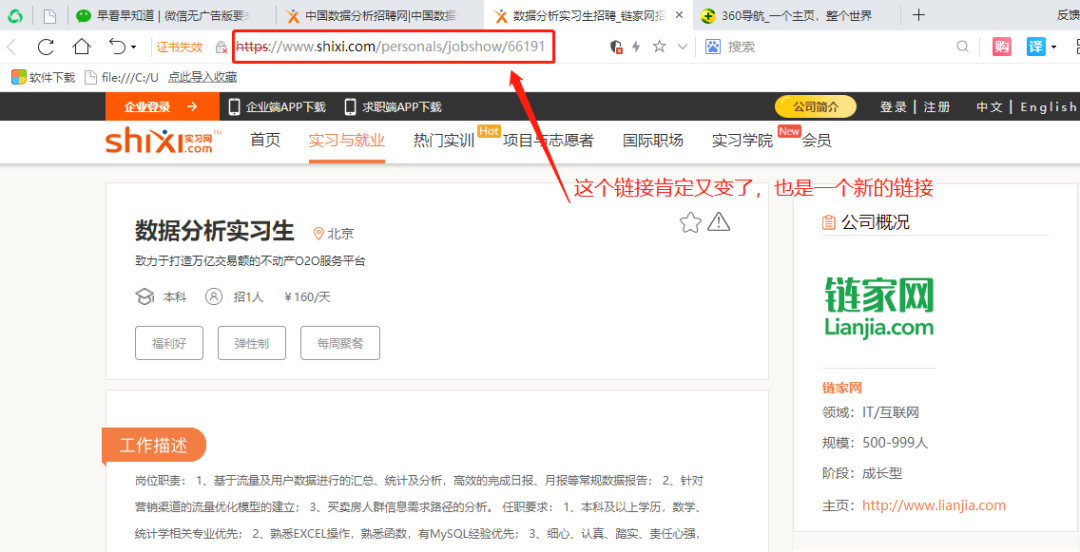
② 你要爬取页面上的哪些信息?
这里我们获取的不仅有一级页面中的信息,还有二级页面中的信息。
在一级页面中(如图所示),我们获取到的有 “公司名”、“岗位名”、“公司地址”、“学历”、“薪资”。

在二级页面中(如图所示),我们获取到的有 “岗位需求”、“公司类型”、“公司规模”。
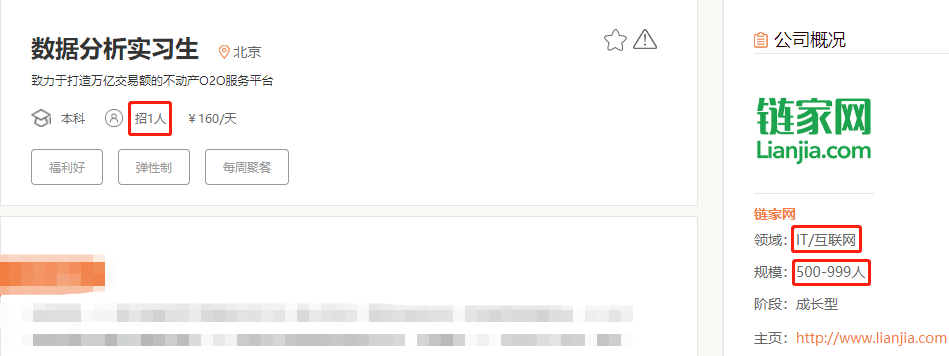
好了,这里一共有8个数据,是我们要获取的数据,这就是我们的 “爬虫目的”。
③ 页面是 “静态网页”,还是“动态网页”?
如果你请求某个网页,网页的信息是一次性给你的,那么它就是 “静态网页”。
如果你请求某个网页,网页中的信息,随着你鼠标往下滑动,而慢慢展现出来,那么它就是 “动态网页”,即 “Ajax技术”。
那么它们的区别就在于: 静态网页中的数据,是一次性给你。动态网页中的数据,是随着页面一步步加载出来,而逐步呈现的,也就是你用静态网页的爬虫技术,无法获取到里面所有的数据。
这里有一个很好 “检验” 是静态网页还是动态网页的方法,我给大家介绍一下 。
点击 “鼠标右键”,点击 “查看网页源代码”。
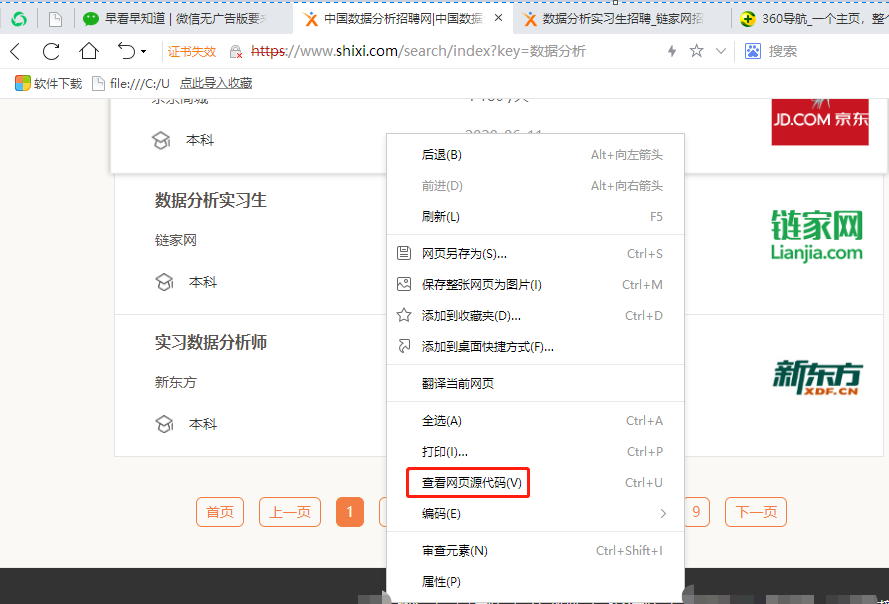
最终效果如下(部分截图):

这其实就是你请求这个网页,最终返回给你的信息。你要爬取的数据,如果在里面都能找到,大致可以判断是 “静态网页”,如果找不到,大致可以考虑是 “动态网页”。
怎么查找呢?
在上述页面,可以点击 “ctrl + f”,调出搜索框(如图所示),你将网页中的数据,粘贴进来,看看能否都能被搜索到。

当然,今天这堂课是小白教程,肯定教你的是一个 “静态网页”。但是没关系呀,这些知识你都知道了。
3. 如何定位数据
在正式写代码之前,你肯定要知道,你想要用哪种方式,来帮你解析数据。常见的Python爬虫解析数据的方法有:re正则表达式、xpath、beautifulsoup、pyquery等。
本文黄同学采用的将会是xpath解析法。
好了,我们接着就来定位数据吧!
点击 “鼠标右键”,再点击 “审查元素”。【或者直接按电脑上的F12键】
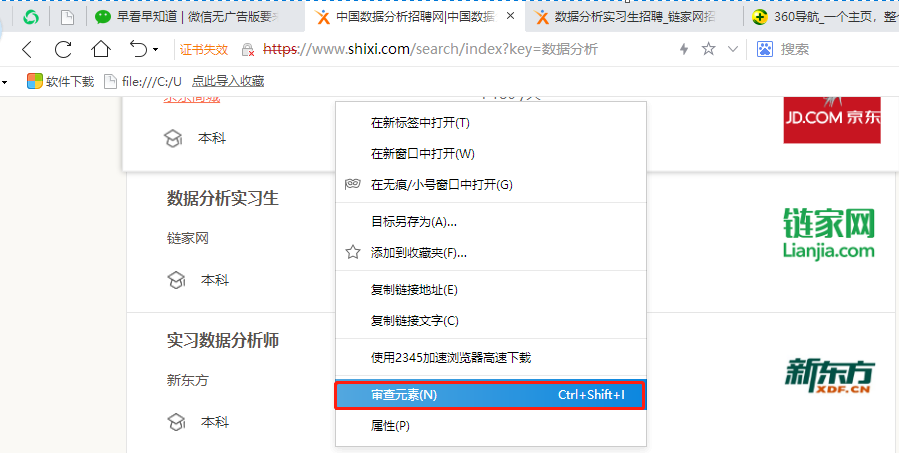
此时,会出现如下页面。

这其实是一个 “桥梁”,帮助我们建立起 “网页” 与 “源代码” 之间的关系定位。
那么,应该怎么使用它呢?(观察下图三个步骤)
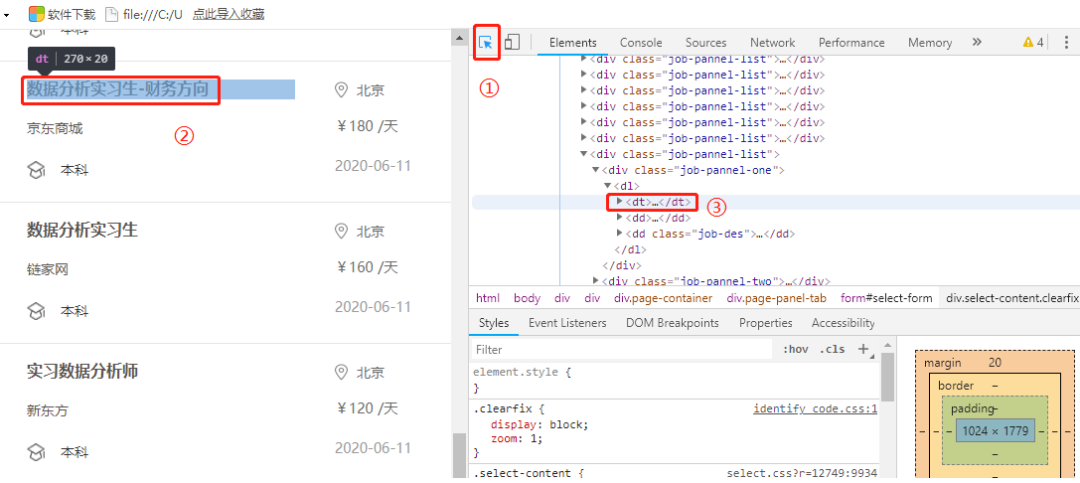
首先,单击①处。接着,光标指向你要定位的数据(②)。此时,在③处,他回自动跳转到你想要定位的数据,在源码中的位置。
这个对于我们写代码超极有帮助,也是最基本的操作。
关于怎么解析数据,我就不在详细说明。因为,这也不是今天这篇文章能够讲清楚的。
今天我就是想让你掌握 “爬虫技术” 的流程。因此,接下来我会为大家讲述整个代码的爬虫思路。
4. 爬虫代码讲解
这里我将会分步为大家讲解整个爬虫流程,这种文章只写这一篇,刚学Python的朋友,一定要看哦!
① 导入相关库
import pandas as pd # 用于数据存储
import requests # 用于请求网页
import chardet # 用于修改编码
import re # 用于提取数据
from lxml import etree # 解析数据的库
import time # 可以粗糙模拟人为请求网页的速度
import warnings # 忽略代码运行时候的警告信息
warnings.filterwarnings("ignore")
② 请求一级页面的网页源代码
url = 'https://www.shixi.com/search/index?key=数据分析&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
这里我们仅仅讲述①②两处。在①处,有两个参数,一个是headers一个是verify。其中headers是一种反反扒的措施,让浏览器认为爬虫不是爬虫,而是人在用浏览器去正常请求网页。verify是忽略安全证书提示,有的网页会被认为是一个不安全的网页,会提示你,这个参数你记住就行。
在②处,我们已经获取到了网页的源码。但是由于网页源代码的编码方式和你所在电脑的解析方式,有可能不一致,返回的结果会导致乱码。此时,你就需要修改编码方式,chardet库可以帮你自动检测网页源码的编码(不懂得再下去研究一下这个库)。
③ 解析一级页面网页中的信息
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# 获取二级页面的链接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
此时,你可以看到,我直接采用xpath一个个去解析一级页面中的数据分析。在代码末尾,可以看到:我们获取到了二级页面的链接,为我们后面爬取二级页面中的信息,做准备。
④ 解析二级页面网页中的信息
demand_list = []
area_list = []
scale_list = []
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
记住:二级页面也是页面呀,你要想获取到其中的消息,就必须再次请求该网页。因此,你可以看到①②③处的代码,和上面写的代码,就是一模一样的。
⑤ 翻页操作
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=1
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=2
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=3
随意复制几个不同页面的url,观察它们的区别。这里可以看到,也就page参数后面的数字不同,是第几页,数字就是几。
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
由于我们爬取了60页 的数据,这里就构造出了60个url,他们都存在url_list这个列表中。
我们现在来看看整个代码吧,我就不再文字叙述了,直接在代码中写好了注释。
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# ① 请求获取一级页面的源代码
url = 'https://www.shixi.com/search/index?key=数据分析&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# ② 获取一级页面中的信息:一共有ⅠⅡⅢⅣⅤⅥ个信息。
# Ⅰ 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# Ⅱ 岗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# Ⅲ 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# Ⅳ 学历
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# Ⅴ 薪资
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# Ⅵ 获取二级页面的url
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# ③ 获取二级页面中的信息:一共有ⅠⅡⅢ三个信息。
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# Ⅰ 需要几人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# Ⅱ 公司领域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# Ⅲ 公司规模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 将每个页面获取到的所有数据,存储到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'岗位名':job_list,'地址':address_list,"学历":degree_list,
'薪资':salary_list,'岗位需求量':demand_list,'公司领域':area_list,'公司规模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=数据分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','岗位名','地址',"学历",'薪资','岗位需求量','公司领域','公司规模'])
# ⑤ 这里进行“翻页”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# ⑥ 保存最终数据
res.to_csv('aliang.csv',encoding='utf_8_sig')
最终爬取到的数据如下:
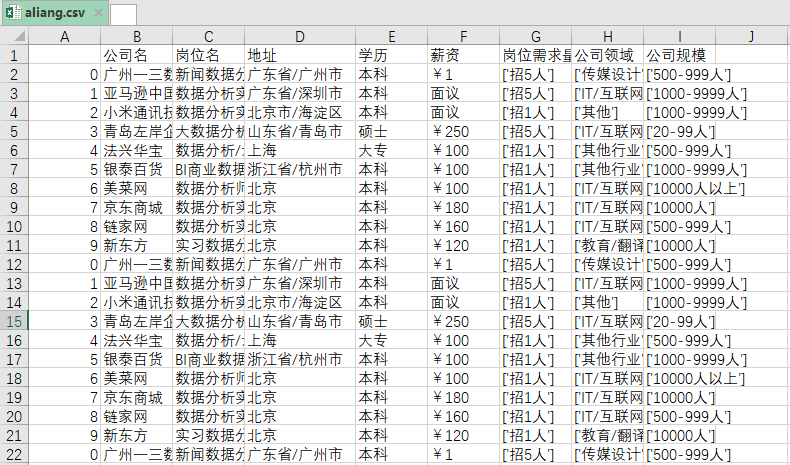
好了,本文就讲述到这里。其实对于一个爬虫小白来说内容已经够多了,好好下去消化。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~















 4792
4792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









