






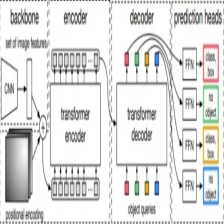
书接上回,上篇博客中我们学习到了Encoder模块,接下来我们来学习Decoder模块其代码是如何实现的。
其实Deformable-DETR最大的创新在于其提出了可变形注意力模型以及多尺度融合模块:
其主要表现在Backbone模块以及self-attention核cross-attention的计算上。这些方法都在DINO-DETR中得到继承,此外DAB-DETR中的Anchor Query设计与bounding box强化机制也有涉及。
Encoder模块
首先经过Encoder后的输出结果为 memory:torch.Size([2, 9620, 256]),其分别代表不同level的特征信息:tensor([ 0, 7220, 9044, 9500], device=‘cuda:0’)
memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten)
Two-Stage
核心思想:
Encoder会生成特征memory,再自己生成初步proposals(其实就是特征图上的点坐标 xywh)。
然后分别使用非共享检测头的分类分支对memory进行分类预测,得到对每个类别的分类结果;
再用回归分支进行回归预测,得到proposals的偏移量(xywh)。再用初步proposals偏移量 得到第一个阶段的预测proposals。
然后选取top-k个分数最高的那批预测proposals作为Decoder的参考点。
并且,Decoder的object query和 query pos都是由参考点通过位置嵌入(position embedding)再接上一个全连接层 + LN层处理生成的。
Two-Stage主要是应用在初始化参考点坐标上。
one-stage的参考点是get_reference_points函数生成的,而two-stage参考点是通过gen_encoder_output_proposals函数生成的。
one-stage初始化方法
def get_reference_points(spatial_shapes, valid_ratios, device):
"""
生成参考点 reference points 为什么参考点是中心点? 为什么要归一化?
spatial_shapes: 4个特征图的shape [4, 2]
valid_ratios: 4个特征图中非padding部分的边长占其边长的比例 [bs, 4, 2] 如全是1
device: cuda:0
"""
reference_points_list = []
# 遍历4个特征图的shape 比如 H_=100 W_=150
for lvl, (H_, W_) in enumerate(spatial_shapes):
# 0.5 -> 99.5 取100个点 0.5 1.5 2.5 ... 99.5
# 0.5 -> 149.5 取150个点 0.5 1.5 2.5 ... 149.5
# ref_y: [100, 150] 第一行:150个0.5 第二行:150个1.5 ... 第100行:150个99.5
# ref_x: [100, 150] 第一行:0.5 1.5...149.5 100行全部相同
ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_ - 0.5, H_, dtype=torch.float32, device=device),
torch.linspace(0.5, W_ - 0.5, W_, dtype=torch.float32, device=device))
# [100, 150] -> [bs, 15000] 150个0.5 + 150个1.5 + ... + 150个99.5 -> 除以100 归一化
ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, lvl, 1] * H_)
# [100, 150] -> [bs, 15000] 100个: 0.5 1.5 ... 149.5 -> 除以150 归一化
ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, lvl, 0] * W_)
# [bs, 15000, 2] 每一项都是xy
ref = torch.stack((ref_x, ref_y), -1)
reference_points_list.append(ref)
# list4: [bs, H/8*W/8, 2] + [bs, H/16*W/16, 2] + [bs, H/32*W/32, 2] + [bs, H/64*W/64, 2] ->
# [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 2]
reference_points = torch.cat(reference_points_list, 1)
# reference_points: [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 2] -> [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 1, 2]
# valid_ratios: [1, 4, 2] -> [1, 1, 4, 2]
# 复制4份 每个特征点都有4个归一化参考点 -> [bs, H/8*W/8+H/16*W/16+H/32*W/32+H/64*W/64, 4, 2]
reference_points = reference_points[:, :, None] * valid_ratios[:, None]
# 4个flatten后特征图的归一化参考点坐标
return reference_points
Two-Stage参考点初始化方法
def gen_encoder_output_proposals(self, memory, memory_padding_mask, spatial_shapes):
"""得到第一阶段预测的所有proposal box output_proposals和处理后的Encoder输出output_memory
memory: Encoder输出特征 [bs, H/8 * W/8 + ... + H/64 * W/64, 256]
memory_padding_mask: Encoder输出特征对应的mask [bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64]
spatial_shapes: [4, 2] backbone输出的4个特征图的shape
"""
N_, S_, C_ = memory.shape # bs H/8 * W/8 + ... + H/64 * W/64 256
base_scale = 4.0
proposals = []
_cur = 0 # 帮助找到mask中每个特征图的初始index
for lvl, (H_, W_) in enumerate(spatial_shapes): # 如H_=76 W_=112
# 1、生成所有proposal box的中心点坐标xy
# 展平后的mask [bs, 76, 112, 1]
mask_flatten_ = memory_padding_mask[:, _cur:(_cur + H_ * W_)].view(N_, H_, W_, 1)
valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1)
valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1)
# grid_y = [76, 112] 76行112列 第一行全是0 第二行全是1 ... 第76行全是75
# grid_x = [76, 112] 76行112列 76行全是 0 1 2 ... 111
grid_y, grid_x = torch.meshgrid(torch.linspace(0, H_ - 1, H_, dtype=torch.float32, device=memory.device),
torch.linspace(0, W_ - 1, W_, dtype=torch.float32, device=memory.device))
# grid = [76, 112, 2(xy)] 这个特征图上的所有坐标点x,y
grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
scale = torch.cat([valid_W.unsqueeze(-1), valid_H.unsqueeze(-1)], 1).view(N_, 1, 1, 2) # [bs, 1, 1, 2(xy)]
# [76, 112, 2(xy)] -> [1, 76, 112, 2] + 0.5 得到所有网格中心点坐标 这里和one-stage的get_reference_points函数原理是一样的
grid = (grid.unsqueeze(0).expand(N_, -1, -1, -1) + 0.5) / scale
# 2、生成所有proposal box的宽高wh 第i层特征默认wh = 0.05 * (2**i)
wh = torch.ones_like(grid) * 0.05 * (2.0 ** lvl)
# 3、concat xy+wh -> proposal xywh [bs, 76x112, 4(xywh)]
proposal = torch.cat((grid, wh), -1).view(N_, -1, 4)
proposals.append(proposal)
_cur += (H_ * W_)
# concat 4 feature map proposals [bs, H/8 x W/8 + ... + H/64 x W/64] = [bs, 11312, 4]
output_proposals = torch.cat(proposals, 1)
# 筛选一下 xywh 都要处于(0.01,0.99)之间
output_proposals_valid = ((output_proposals > 0.01) & (output_proposals < 0.99)).all(-1, keepdim=True)
#用log(x/1-x)
output_proposals = torch.log(output_proposals / (1 - output_proposals))
# mask的地方是无效的 直接用inf代替
output_proposals = output_proposals.masked_fill(memory_padding_mask.unsqueeze(-1), float('inf'))
# 再按条件筛选一下 不符合的用用inf代替
output_proposals = output_proposals.masked_fill(~output_proposals_valid, float('inf'))
output_memory = memory
output_memory = output_memory.masked_fill(memory_padding_mask.unsqueeze(-1), float(0))
output_memory = output_memory.masked_fill(~output_proposals_valid, float(0))
# 对encoder输出进行处理:全连接层 + LayerNorm
output_memory = self.enc_output_norm(self.enc_output(output_memory))
return output_memory, output_proposals
for循环里是对不同level的所有格点创建不同尺寸的anchor框,scale其实是对有效区域的处理,后续对output_proposals的处理是筛选掉边界附近的候选,输出是对应位置的特征和编码后的proposal, 对应位置的特征用于映射proposal的类别score以及校正偏差。值得注意的是proposal并没有直接使用原始坐标,而是进行了log的编码, 在forward中的two_stage情况提取reference_points是使用sigmoid函数进行了解码,我们假设偏置量为0,可以发现:
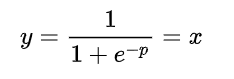
所谓的双阶段其实就是在Encoder后不是将数据直接送入Decoder,而是送入MLP与全连接层进行分类与回归后再送入Decoder。
enc_outputs_class = self.decoder.class_embed[self.decoder.num_layers](output_memory) #torch.Size([2, 9620, 91])
enc_outputs_coord_unact = self.decoder.bbox_embed[self.decoder.num_layers](output_memory) + output_proposals#torch.Size([2, 9620, 4])

随后选择topk
topk = self.two_stage_num_proposals
topk_proposals = torch.topk(enc_outputs_class[..., 0], topk, dim=1)[1]#torch.Size([2, 300])
#torch.Size([2, 300])
topk_proposals = torch.topk(enc_outputs_class[..., 0], topk, dim=1)[1]
#torch.Size([2, 300, 4])
topk_coords_unact = torch.gather(enc_outputs_coord_unact, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4))
#torch.Size([2, 300, 4])
topk_coords_unact = topk_coords_unact.detach()
将其进行sigmoid,由于gen_encoder_output_proposals进行了log,此时sigmoid刚好可以变回初始值
reference_points = topk_coords_unact.sigmoid() #torch.Size([2, 300, 4])

随后得到初始化参考点坐标信息:
层归一化定义:
self.pos_trans_norm = nn.LayerNorm(d_model * 2)
#torch.Size([2, 300, 4])
init_reference_out = reference_points
#pos_trans_norm是层归一化,得到结果torch.Size([2, 300, 512])
pos_trans_out = self.pos_trans_norm(self.pos_trans(self.get_proposal_pos_embed(topk_coords_unact)))
query_embed, tgt = torch.split(pos_trans_out, c, dim=2)
最终得到:query_embed torch.Size([2, 300, 256]),tgt torch.Size([2, 300, 256])


Decoder模块
终于,进入了Decoder模块,我们首先来看其传入的参数:
tgt:torch.Size([2, 300, 256])
reference_points:torch.Size([2, 300, 4])
memory:torch.Size([2, 9620, 256])
spatial_shapes:
tensor([[76, 95],
[38, 48],
[19, 24],
[10, 12]], device='cuda:0')
level_start_index:tensor([ 0, 7220, 9044, 9500], device=‘cuda:0’)
query_embed:torch.Size([2, 300, 256])
mask_flatten:torch.Size([2, 9620])
hs, inter_references = self.decoder(tgt, reference_points, memory,
spatial_shapes, level_start_index, valid_ratios,
query_pos=query_embed if not self.use_dab else None,
src_padding_mask=mask_flatten)
进入Decoder层:
其后就与DAB-DETR一致了,只是将cross_attention替换为可变形注意力。
















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











