






1、摘要
大型语言模型 (LLM) 最近表现出令人印象深刻的执行算术和符号推理任务的能力,只要在测试时提供一些示例(“fewshot 提示”)。这种成功在很大程度上可以归功于提示方法,例如“chain-of-thought”,它使用 LLM 通过将问题分解为步骤来理解问题描述,以及解决问题的每个步骤。虽然 LLM 似乎擅长这种逐步分解,但 LLM 经常在解决方案部分犯逻辑和算术错误,即使问题已正确分解。在本文中,我们介绍了程序辅助语言模型 (PAL,ProgramAided Language models):一种使用 LLM 阅读自然语言问题并生成程序作为中间推理步骤的新方法,但将解决方案步骤卸载(offloads)到例如 Python 解释器运行。使用 PAL,将自然语言问题分解为可运行的步骤 remains LLM 只用于学习任务,而解决问题则委托给解释器。我们在 BIG-Bench Hard 和其他基准测试中的 13 项数学、符号和算法推理任务中展示了神经 LLM 和符号解释器symbolic interpreter之间的这种协同作用。在所有这些自然语言推理任务中,使用 LLM 生成代码并使用 Python 解释器进行推理会导致比大得多的模型更准确的结果。例如,使用 CODEX 的 PAL 在数学单词问题的 GSM8K 基准测试中实现了最先进的少样本准确率,超过了使用思维链的 PaLM-540B 绝对 15% top1。
2、介绍
事实上,即使在显式数学内容的 164B tokens上微调基于 PaLM 的模型,据报道其两个最常见的故障是“推理不正确”和“计算不正确”。
我们展示了 PAL 在 13 项算术和符号推理任务中的有效性。在所有这些任务中,使用 Codex 的 PAL(Chen 等人,2021a)优于更大的模型,例如使用思维链提示的 PaLM-540B。例如,在流行的 GSM8K 基准测试中,PAL 达到了最先进的精度,以绝对 15% 的 top1 精度超过了带有思想链的 PaLM-540B。当问题包含大量数字时,我们称之为 GSM-HARD 的数据集,PAL 绝对优于 COT 40%。我们相信,神经 LLM 和符号解释器之间(neural LLM and a symbolic interpreter)的这种无缝协同作用是迈向通用和强大的 AI 推理机的重要一步。

自然语言 (NL) 编程语言 (PL)
2.1 Program-aided Language Models
我们建议为给定的自然语言问题 x 生成思想 t 作为交错的自然语言 (NL) 和编程语言 (PL) 语句。我们不提供提示COT中示例的最终答案。我们让 LM 生成预测 t t e s t {t_{test}} ttest ,其中包含中间步骤及其相应的程序语句。
来自 PAL 提示符的单个示例的特写:

在 PAL 中,我们还使用相应的编程语句(例如网球 = 5 和购买的球 = 2 * 3)来扩充每个这样的 NL 步骤。这样,模型学习生成一个程序,它将提供测试问题的答案,而不是依赖 LLM 来正确执行计算。
我们提示语言模型使用注释语法(例如 Python 中的“# …”)生成 NL 中间步骤,这样它们将被解释器忽略。我们将生成的程序ttest传递给它对应的求解器,我们运行它,得到最终的运行结果ytest。在这项工作中,我们使用标准的 Python 解释器,但这可以是任何求解器、解释器或编译器。
2.2 制作PAL提示
在我们的实验中,我们尽可能利用现有工作的提示,否则随机选择与以前的工作相同数量(3-6)的示例来为每个基准创建固定提示。在所有情况下,我们都将自由格式的文本提示扩充为 PAL 风格的提示,并在需要时利用 for 循环和字典等编程结构。通常,编写 PAL 提示符既简单又快捷。
我们还确保提示中的变量名称有意义地反映了它们的角色。例如,一个描述篮子里苹果数量的变量应该有一个名字,比如 num apples in basket。这使生成的代码与问题中的实体保持链接。在第 6 节中,我们展示了这种有意义的变量名称是至关重要的。值得注意的是,还可以增量运行 PL 段并将执行结果反馈给 LLM 以生成 following blocks。为简单起见,在我们的实验中,我们使用了单个事后执行( single, post-hoc, execution)。
这项工作侧重于 COT 式推理链,但在下面我们展示了 PAL 还改进了 Least-toMost提示,它引入了将问题分解为子问题的推理链。

3、实验设置
数据和上下文示例:
我们试验了三大类推理任务:(1) 来自广泛数据集的数学问题,包括 GSM8K(Cobbe 等人,2021 年)、SVAMP(Patel 等人,2021 年)、ASDIV(Miao 等人, 2020 年)和 MAWPS(Koncel-Kedziorski 等人,2016 年); (2) 来自 BIG-Bench Hard 的符号推理(Suzgun 等人,2022 年); (3) 和来自 BIG-Bench Hard 的算法问题 。所有数据集的详细信息显示在附录 H 中。对于 COT 提示可用的所有实验,我们使用与之前工作相同的上下文示例。否则,我们随机抽取一组固定的上下文示例,并且使用相同的PAL和COT。
Baselines:
我们考虑了三种提示策略: 直接提示——标准提示方法,使用成对的问题和立即回答(例如 11);思维链 (COT) 提示;和我们的 PAL 提示。我们使用 0 temperature(表示不引入任何随机性预测下一个单词)从语言模型执行贪婪解码。除非另有说明,否则我们使用 CODEX (code-davinci-002) 作为 PAL、DIRECT 和 COT 的后端 LLM。在可从以前的工作中获得其他基础 LM(例如 PaLM-540B)的结果的数据集中,我们将它们作为 COT PaLM-540B 包括在内。
3.1 数学推理
我们在八个数学单词问题数据集上评估 PAL。这些任务中的每个问题都是小学水平的代数应用题。图 3 显示了一个问题示例和 PAL 示例提示。我们发现使用显式 NL 中间步骤不会进一步有益于这些数学推理任务,因此我们只在提示中保留有意义的变量名称。

GSM-HARD LLMs 可以用小数字进行简单的计算。然而,在流行的 GSM8K 数学推理问题数据集中,50% 的数字是 0 到 8 之间的整数。这提出了 LLM 是否可以泛化到更大的非整数的问题?我们构建了一个更难的 GSM8K 版本,我们称之为 GSM-HARD,通过用更大的数字替换 GSM8K 问题中的数字。具体来说,问题中的一个数字被替换为最多 7 位的随机整数。
(虽然使用模式匹配替换问题中的数字很容易,但更具挑战性的方面是重新计算正确答案。 GSM8K 评估集包含 1319 个样本,执行手动重新计算的成本过高。相反,我们利用 PAL 来帮助获得正确答案。对于 GSM8K 上 PAL 正确的 71% 示例,我们利用生成的程序并将初始值替换为较大的值。例如,如果我们通过将 $23 美元替换为 $15687 美元来创建图 3 中问题的更难版本,我们相应地将 money initial=23 替换为 money initial=15678。运行该程序可以自动生成较难问题的正确答案。值得注意的是,此注释过程假定对 GSM8K 问题产生正确答案的程序表明程序本身的正确性。虽然由于可能存在虚假相关性而无法保证这一点,但我们手动检查了 25 个程序并发现它们都是正确的。对于不正确的 29% 的情况,我们再次运行 PAL 并执行温度为 0.7 的核采样 (Holtzman et al, 2019),如果找到任何正确的解决方案,则重复上述过程。最后,作者手动注释了 PAL 在 100 次迭代后无法解决的剩余 50 个案例的正确答案。)
3.2 符号推理
我们将 PAL 应用于 BIG-Bench Hard的三个符号推理任务,这些任务涉及对物体和概念的推理:COLORED OBJECTS 需要回答有关表面上彩色物体的问题。此任务需要跟踪每个对象的相对位置、绝对位置和颜色。图 4 显示了问题示例和 PAL 提示示例。另外两个任务类似。

图 4:彩色对象任务中 PAL 提示的示例。出于篇幅考虑,我们省略了创建列表对象的代码。
3.3 算法任务
最后,我们在算法推理上比较了 PAL 和 COT。在这些任务中,人类程序员可以根据问题的先验知识编写确定性程序。我们试验了两个算法任务:对象计数和重复复制。对象计数涉及回答有关属于特定类型的对象数量的问题。例如,如图 5 所示:“我有一把椅子,两个土豆,一个花椰菜,一个生菜头,两张桌子,……我有多少种蔬菜?”)。
OBJECT COUNTING 任务中 PAL 提示的示例。基本 LM 预期将输入转换为字典,其中键是实体,值是它们的数量,同时过滤掉非植物实体。最后,答案是字典值的总和。

重复复制需要根据指令生成一个单词序列。例如,“重复duck这个词四次,但中途还要说quack”)。

4、结果
4.1 数学结果
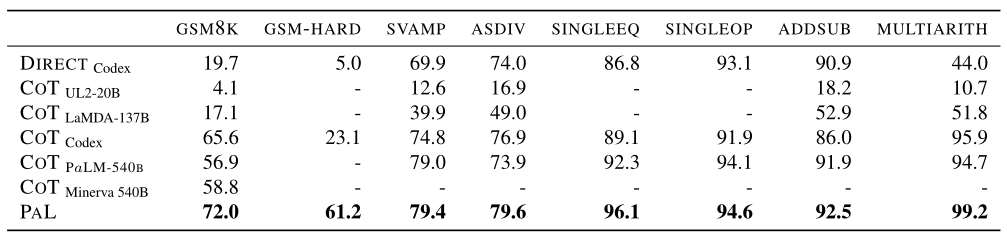
表 1 显示了以下结果:在所有任务中,使用 Codex 的 PAL 在所有数据集上设置了一个新的 few-shot state-of-the-art top1 解码,优于 COTCodex、COTPaLM-540B 和 COTMinerva 540B,后者在显式上进行了微调数学内容。
有趣的是,COT 在某些数据集(如 ASDIV)中也受益于 Codex 而不是 PaLM540B,但在其他数据集(如 SVAMP)中的表现比 PaLM-540B 差。然而,使用 PAL 进一步提高了所有数据集的求解率。
在 GSM-HARD(表 1)上,DIRECT 的准确率从 19.7% 急剧下降到 5.0%(相对下降 74%),COT 的准确率从 65.6% 下降到 20.1%(相对下降近 70%) ,而 PAL 保持稳定在 61.5%,仅下降 14.3%。即使我们将其提示替换为包含大量数字的提示(附录 B),COT 在 GSM-HARD 上的结果也没有改善。这表明 PAL 如何不仅提供更好的结果在标准基准上,但也更加稳健。事实上,由于 PAL 将计算卸载 offloads 到 Python 解释器,只要正确生成程序,任何复杂的计算都可以准确执行。
多样本生成:

正如 Wang 等人所发现的,可以通过对 k > 1 个输出进行采样并使用多数表决选择最终答案来进一步改进思维链式方法。因此,我们使用核采样(Holtzman 等人,2019 年)重复贪婪解码实验,其中 p = 0.95 和 k = 40,如 Lewkowycz 等人和temperature 0.7。如表 3 所示,这进一步将 GSM8K 上的 PAL 准确度从 72.0% 提高到 80.4%,使用相同数量的样本获得比 Minerva-540B 高 1.9% 的准确度。
4.2 符号推理和算法任务结果
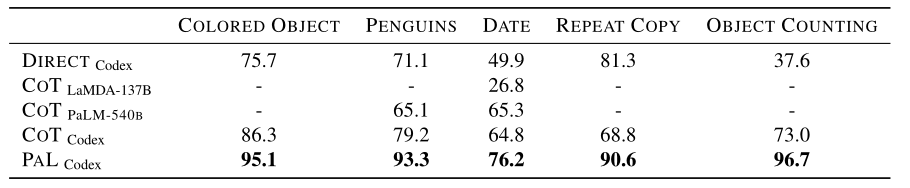
符号推理和算法任务的结果如表 2 所示。在彩色对象中,PAL 比strong COT 提高了 8.8%,比标准直接提示提高了 19.4%。在 PENGUINS 中,PAL 比 COT 提供了 14.1% 的绝对收益。在 DATE 中,PAL 比 COT Codex、PaLM-540B 和 LaMDA-137B 进一步提供了 11.4% 的增益。表 2 最右边的两列显示 PAL 接近解决 对象计数,达到 96.7%,比 COT 提高了绝对 23.7%。同样,PAL 在 重复复制 上的表现远远优于 COT 21.8%。令人惊讶的是,DIRECT 提示在 重复复制 上的表现优于 COT。然而,PAL 在 重复复制 中比 DIRECT 提高了 9.3%。
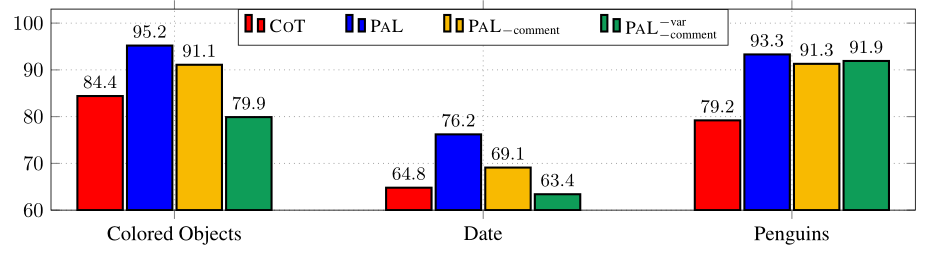
PAL 是否对问题的复杂性敏感?我们检查了 PAL 和 COT 的性能如何随着输入问题复杂性的增加而变化,以彩色对象问题中的对象数量来衡量。如图 6 所示,PAL 在所有输入长度上都优于 COT。随着问题中对象数量的增加,COT 的准确性不稳定并下降,而 PAL 始终保持接近 100%。

5、分析
PAL 是否适用于较弱的 LM?
在所有实验中,PAL 使用 code-davinci-002 模型;但是 PAL 可以使用较弱的代码模型吗?当两种提示方法都使用相同的较弱基础 LM code-cushman-001 和 code-davinci-001 时,我们将 PAL 与 COT 进行了比较。如图 7 所示,尽管 code-cushman-001 和 code-davinci-001 的绝对准确度较低,但 PAL 相对于 COT 的相对改进在各个模型中保持一致。这表明 PAL 可以与较弱的模型一起工作,同时它的好处也可以优雅地扩展到更强的模型。

PAL 是否适用于自然语言NL的 LM?
我们还使用 text-davinci 系列对 PAL 进行了实验。图 8 显示了以下有趣的结果:当基础 LM 的“代码建模能力”较弱时(使用 text-davinci-001),COT 的性能优于 PAL。然而,一旦 LM 的代码建模能力足够高(使用 text-davinci-002 和 text-davinci-003),PAL 就优于 COT,PAL text-davinci-003 的性能几乎与 PAL code-davinci-002 一样。
这表明 PAL 不限于代码的 LM,如果它们具有足够高的编码能力,它可以与主要针对自然语言训练的 LM 一起工作。

PAL 更好是因为 Python prompt还是因为解释器interpreter?
我们尝试生成 Python 代码,同时要求神经 LM 也“执行”它,而不使用解释器。我们创建了类似于 PAL 的提示,只是它们确实包含最终答案。
这导致 GSM8K 的解算率为 23.2,远低于 PAL(72.0),仅比 DIRECT 高 4.5 分。这些结果强化了我们的假设,即 PAL 的主要优势来自与interpreter的协同作用,而不仅仅是来自更好的提示prompt。
变量名重要吗?
在我们所有的实验中,我们在 PAL 提示中使用了有意义的变量名称,以简化模型将变量定位到它们所代表的实体。然而,对于 Python 解释器来说,变量名是没有意义的。为了衡量有意义的变量名称的重要性,我们试验了两种提示变体:
- PAL-comment – 没有中间 NL 注释的 PAL 提示符。
- PAL-var-comment – PAL 提示符,没有中间 NL 注释,变量名被随机字符替换。
结果如图 9 所示。在 COLORED OBJECTED 和 DATE 中,删除中间 NL 注释但保留有意义的变量名称(PAL-comment)——与完整的 PAL 提示相比,结果略有减少,但它仍然比基线 COT 获得更高的准确性.删除变量名(PAL-var-comment)会进一步降低准确性,并且性能比 COT 差。由于变量名在代码质量中起着重要作用,有意义的变量名预计只会简化 Codex 的推理,因为 Codex 是在大多数有意义的名称上训练的。
6、结论
我们介绍了 PAL,一种新的自然语言推理方法,使用程序作为中间推理步骤。与现有的基于 LM 的推理方法不同,主要思想是将求解和计算offload到外部 Python 解释器,而不是使用 LLM 来理解问题和求解。鉴于正确预测的程序步骤,这将导致最终答案保证准确。我们在 BIG-Bench Hard 和其他基准测试的 13 个任务中展示了 LLM 和 Python 解释器之间的这种无缝协同作用。在所有这些基准测试中,PAL 优于更大的 LLM,例如 PaLM-540B,后者使用流行的“思想链”方法,并在所有这些上设置了新的最先进的精度。我们相信这些结果为未来的神经符号 AI 推理器开启了激动人心的方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









