






摘要
基于大型语言模型的角色扮演聊天机器人引起了人们的兴趣,但需要更好的技术来模仿特定的虚构人物。我们提出了一种算法,通过从脚本中提取字符的改进提示和记忆来控制语言模型。我们构建了ChatHaruhi,这是一个包含32个中文/英文电视/动漫角色的数据集,其中包含超过54k个模拟对话。自动和人工评估都表明,我们的方法在基线上提高了角色扮演能力。
代码: https://github.com/LC1332/ChatHaruhi-Suzumiya.
数据集:https://huggingface.co/datasets/silk-road/ChatHaruhi-54K-Role-Playing-Dialogue/viewer/default/train
在开源的角色扮演实现中,开发人员或用户使用类似的提示,将它们连续输入ChatGPT或作为系统暗示whisper输入语言模型:
“我希望你表现得像{series}中的{角色}。我希望你用{character}}会使用的语气、方式和词汇来回答和回答。不要写任何解释。只能像{character}这样回答。你必须了解{character}的所有知识。我的第一句话是“嗨。{character}”
随着ChatGPT或Claude(Anthropic, 2023)等更大的语言模型所展示的智能,在许多故事上训练,用户发现模型可以在这样的提示下表现出一定的角色扮演能力。然而,虽然简单,这样的实现有以下缺点:它们严重依赖于语言模型的现有记忆。如果语言模型自己对作品的记忆是模糊的,它就不能很好地模仿特定的人物。2. “知道所有关于角色的知识”的定义是模糊的,并不能很好地防范幻觉。3.即使有这样的提示,聊天机器人的会话风格仍然受到底层语言模型的严重影响。调整提示可能会缓解这种情况,但需要为每个字符微调提示。这些缺点明显限制了这种角色扮演聊天机器人的效用。
另一个简单的想法是根据角色的对话对模型进行微调。有了足够的数据,语言模型就可以捕捉到角色的语气,但这也会带来新的问题。在初步实验中,我们发现经过微调的聊天机器人产生了更多的幻觉。此外,对于许多次要字符,很难获得足够的数据进行微调。总之,更好的语言支持角色扮演和模仿经典人物的模型仍然是一个未解决的问题。
这个项目的主要目标是研究自然语言模型是否可以在对话中扮演动漫、电视或其他作品中的真实角色。在这个过程中,我们认为虚拟角色由三个核心部分组成:
1、知识和背景:每个虚拟角色都有自己的背景。《哈利波特》中的人物存在于哈利波特的魔法世界中。凉宫春日位于日本的一所高中。其他动画角色也有自己的世界建筑。因此,在构建聊天机器人时,我们希望它能够理解相应故事的设置。这对语言模型的记忆构成了重大考验,通常需要外部知识库。
2、个性:角色的个性也是动漫、电视甚至游戏作品中非常重要的一部分。个性必须在整个工作过程中保持一致。有些文学作品甚至在写其余部分之前先定义了人格。因此,我们希望聊天机器人能反映出原始的个性。
3、语言习惯:语言习惯是语言模型最容易模仿的。在近年来的大型模型中,在给定适当的上下文示例的情况下,语言模型可以产生模仿输出。在这里,我们希望与聊天机器人互动的粉丝能够“复制”经典片段,为他们提供更好的体验。
这个项目的关键思想是提取尽可能多的原始脚本,形成一个记忆数据库的角色。当用户提出新的问题时,系统会搜索相关的经典情节。结合角色设置提示,我们试图通过控制语言模型来更好地模仿角色。同时,受到CAMEL(Li et al ., 2023)和Baize(Xu et al ., 2023)的启发,我们设计了一个系统,可以自动生成符合角色个性的对话,即使角色的原始对话较少。这允许我们生成足够的数据来微调局部模型。
项目的主要贡献可以概括为以下几点:
1、基于大型的语言模型,作者提出了一套完整的角色扮演的算法系统。这套算法可以有效地组织角色的过往记忆,使得语言模型能够模仿特定影视、动漫角色的语气和知识进行对话。这套系统可以使用 OpenAI 的 ChatGPT 或者 Claude 这样的预训练大模型,也可以使用较小的 7B 规模的本地模型。
2、作者提出了一个角色扮演的数据集,这个数据集包括了超过 30 个不同的中文 / 英文影视角色。通过收集电影、小说、剧本的语料,并进行结构化的抽取,他们收集了超过 23000 条以上的对话信息。这些对话数据可以用来训练和检验角色扮演的语言模型。同时,使用作者提出的算法,借助 GPT3 和 GPT4,他们为这些角色额外模拟生成了超过 27000 条以上的对话。合并形成了 ChatHaruhi-54k 数据集。
3、为了检验和比较不同方式形成的角色扮演 ChatBot 的性能,他们使用自动测评和人工测评两个方式对角色扮演机器人进行了测评(部分测评结果还未公布)。在自动测评中,他们测试角色是否能够对剧本中的经典的剧情进行响应,给出和原剧本近似的回答。在人工测评中,他们提出了两个不同的指标,让被试去评估两个不同的指标:吻合度:机器人的回答是否符合角色的原来设定;回答质量:机器人的回答的语言质量是否较好。结果发现,在使用同样的基础语言模型的情况下,他们的算法可以给出更好的角色扮演的性能。
ChatBot Design
给定一个特定的角色R和一个查询问题q,我们希望能够根据角色的知识背景、个性和语言习惯生成答案a。其中Θ表示语言模型参数,这些参数在推理期间是静态的。在ChatGPT发布后,用户发现他们可以指定一个特定的系统提示sR = '我想让你扮演系列中的角色…‘,所以:
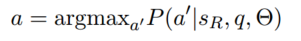
这表明语言模型具有一定的角色扮演能力。然而,角色的记忆完全依赖于参数Θ。如果模型的知识有限,甚至不包含期望的字符R,则往往无法达到理想的效果。
D(q, R) = (u1, v(u1; R)), …,(uM, v(uM; R))
其中um是由R以外的字符提出的任何问题,而v(um;R)是人物R对问题的回答。我们希望通过将角色的经典对话输入到上下文中,使模型能够更好地发挥角色R的作用。
对于具有更大世界观的角色,为了使D(q, R)的内容与q的内容更相关,我们在这里使用句子嵌入从更大的记忆库U中搜索M个最相关的问答。这里U是小说/电影中其他角色与R互动的所有句子的集合。
searching mechanism um(q). 感觉比较关键
当然,在实践中,我们还需要额外记录对话历史H,以确保对话的连续性,因为还需要考虑之前对话的上下文:
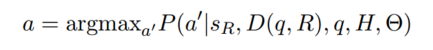

图4:ChatHaruhi的核心对话系统,由系统提示符、为用户查询q检索到的字符记忆D(q, R)和对话历史H组成。
3.1系统提示
有两个重要方面需要提升:
1、不会重复行: 对于像ChatGPT和LLaMA2这样经历了大量从人类反馈(RLHF)中强化学习的模型,由于这些语言模型经常面临“给我m个不同的选项”、“生成m个标题”等任务,因此这些语言模型的输出往往不会重复上下文中的内容。 我们在初步实验中也观察到了这一现象。因此,我们提出的方法是在提示sR中强调模型是在cosplay一个特定的角色。并强调语言模型可以重用小说或电影中的经典台词。
2、字符强调不够突出:由于RLHF,每个语言模型都有自己特定的语言偏好。即使给定D(q, R)来模仿,模型的输出仍然受到语言模型本身的影响。我们发现在sR结尾补充角色的个性会产生更好的效果。
基于以上两点,我们常用的字符设置提示模板sR如下:
I want you to act like {character} from {series}.You are now cosplay {character} If others’ questions are related with the novel,please try to reuse the original lines from the novel. I want you to respond and answer like {character} using the tone, manner and vocabulary {character} would use.
You must know all of the knowledge of {character}.
{Supplementary explanation of the character’s personality}
请注意,我们已经加强了对语言模型的要求,以重用故事中的句子。我们发现,语言模型的最终输出对补充解释的效果非常敏感。包括在补充说明中添加某些言语符号也能反映在最终输出。
3.2 每个角色的对话
为了更好地再现小说/电视剧/电影中人物的行为,我们在d中加入了大量的经典剧本节选。这里需要指出的是,除了少数人物(如相声演员于谦),并非所有的对话都是很好的问答形式。在这里,我们实际使用的D是故事形式,如下:
D(q, R) = {d1, d2,…, dM}
我们确保在dm中至少有一个(um, v(um;R))。在u和v的信息之间,可能有旁白,也可能有更多其他角色的对话,或者是一个角色的动作信息。我们放宽这个条件,这样每个故事dm都能更好地保留对话的情节。有时围绕对话的叙述和动作是不可避免的。放宽条件也有利于准备更多的脚本数据,这将在后面的新颖文本提取中提到。
3.3 原创对话搜索
在实践中,一个角色R的所有故事中的令牌总数通常远远超过语言模型的成熟范围。在这里,我们使用一种搜索方法来减少每次输入的原始对话框的数量。
对于查询q,我们将使用句子嵌入模型f()来提取所有d∈D的嵌入f(d)。在类似地提取查询q的f(q)之后,我们从D中提取(在余弦相似性方面)最接近f(q)的M个样本。这形成了本次对话的参考语境D(q,R)
对于每个对话M引用的原始对话摘录的数量,我们实际上会根据搜索到的令牌数量进行动态调整。在具体实现中,如果使用OpenAI的turbo-3.5模型,我们将把D中的token总数限制在1500以内。
因此,在构建对话记忆库时,我们建议每个故事的长度不要太长,以免在搜索时占用其他故事的空间。
对于嵌入模型,我们使用OpenAI的text-embedding-ad-002模型。同时,对于汉语问题,我们使用Luotuo-Bert-Medium,因为后者是从前者中提炼出来的模型,具有相同的分布。这使我们能够无缝地使用Luotuo-Bert,即使故事是用英语写的,也能实现跨语言聊天机器人,这将在跨语言实验部分进行解释。
需要注意的是,在ChatHaruhi 2的重建中,我们注意到了许多其他嵌入模型,如instructor-large、M3E或BGE。当有足够的时间时,我们将替换嵌入模型进行实验。
3.4 聊天Memory
对于记忆 H,我们记录每个用户查询q和聊天机器人的响应a,形成序列H:H={(q1,a1),…,(qT,aT)}
H中的信息也被输入到语言模型中,以确保会话的连贯性。在实际实现中,从T开始,我们向前计数令牌的总数。并将语言模型的对话历史输入限制在1200个标记以内。因此,在这部作品中,我们并不关心角色的长期记忆。1200个代币可以容纳大约6-10轮对话。随着语言模型能够包含更长的上下文,如何对长期记忆进行编码和总结也将是一个更有趣的问题。
角色数据集构建
对于我们的项目,当生成涉及角色R的对话时,我们需要与角色R相关的经典故事D(q,R)作为输入。因此,为每个角色构建原创对话D至关重要。此外,我们需要更多的数据,而不仅仅是原始对话的数据来训练局部模型。在本节中,我们首先介绍如何为每个角色构建对话D。
4.1 原始脚本提取
我们为电视节目、电影或小说构建了不同的提取工具
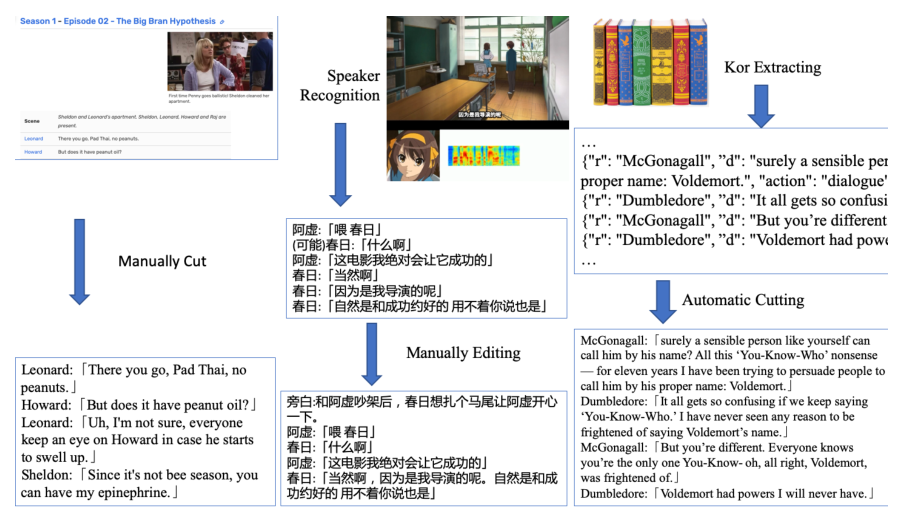
图. 用于微调的22k原创交流从电影剧本、小品剧本、电视节目和小说中提取。
4.1.1 Quotes Data
《让子弹飞》中的唐参赞、《你好,亿万富翁先生》中的王多鱼和于谦的剧本都可以直接在网上找到。对于前两个角色,我们手动将脚本分割成多个片段,并将其格式化为定义的“角色:‘对话’”形式。
于谦的《相声一代》语料库收录了6000多篇对话。所有的对话都是很好的问答形式。我们检查了每个话语u和v的长度,如果在连续相声程序中句子具有局部最大长度,则在句子前拆分。
4.1.2 Extract from TV Series
像铃宫春日和李云龙这样的角色,电视编剧经常创作原创对话。以《亮剑》小说和电视剧为例,后者具有更多的对话信息和立体化的人物塑造。在这种情况下,需要从电视剧中提取人物对话。
我们首先使用Whisper或直接使用原始字幕进行语音识别。我们使用192 dim ECAPA-TDNN说话人验证嵌入来进一步识别每行的说话人,该嵌入是在一些标记的字符对话上训练的。
最后,手动更正识别错误并拆分脚本。由于人工组织很耗时(通常需要重新观看节目),我们只以这种方式处理铃宫春喜和李。我们希望更多的爱好者能够在开源完整的电视处理工具包后塑造角色。
4.1.3 Extract from Novel
得益于大型语言模型的进步,我们还可以使用通用语言模型来批量处理小说。对于《半神半魔》、《鹿鼎记》和《哈利波特》,我们利用Kor的提取机制(一个上下文学习信息提取库)逐句提取“角色动作对话”信息。
在提取提示中,如果一个句子包含对话,我们希望语言模型将动作记录为“对话”和对话内容。如果一个句子不包含对话,我们希望语言模型总结角色在动作场中的动作。语言模型还具有从上下文推断每个对话中谁在说话的能力。
在大量新颖提取之后,我们使用有限状态机来分割对话。对于每个主角,我们都会寻找一个长度合适的片段,最好是长度有限、字符较少、非对话句子最少的片段。
对话合成
给定系统提示sR和每个角色对应的经典动画D(q,R),我们发现角色已经可以以某种风格回答用户问题q。然而,在这一点上,我们需要利用ChatGPT或Claude API来建模p(a|sR,D(q,R),q)。
如果我们想将ChatHaruhi的功能转移到本地模型,我们需要构建一个合适的(R,q,a)数据集。在本节中,我们将讨论如何为数据有限的角色增加对话数据。
5.1 根据问题生成对话
请注意,收集的D数据不是严格的(q,a)形式。这意味着我们不能简单地微调语言模型来学习所有{DR}数据。为了解决这个问题,对于任何d∈DR,我们将主角R轮之前的所有对话都取为q,希望将这个q作为第一个问题q1来生成对话。
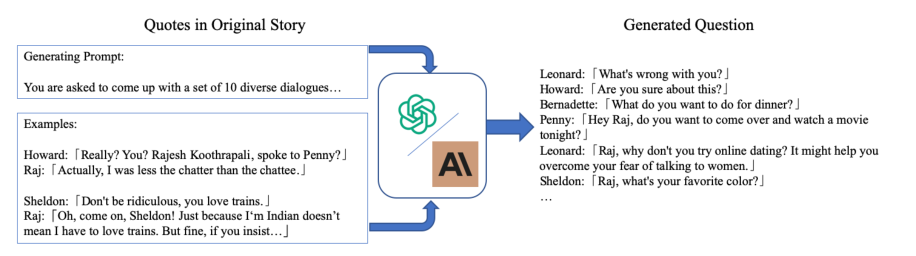 图. 大量模拟查询是用类似Alpaca的方式生成的。
图. 大量模拟查询是用类似Alpaca的方式生成的。
在实践中,我们发现语言模型有时可以输出多个对话,即在给出一个答案a1后,它生成一个新的问题q2和随后的回答。此外,在这样生成的对话中,所有的a都符合角色R的个人资料。因此,我们想修改我们的聊天机器人,以进一步利用这一特性来产生更多的对话。对于每个对话d,我们按角色R定位第一个话语。在这个话语之前,d被分为左右两部分dL和dR。我们在dL的两端插入用户消息特殊标记,在dR的两端插入AI消息特殊标记。我们对所有M个故事都这样做,这样,基于这M个例子,给定q1,语言模型可以模拟生成相应的对话d’。由此产生的d′成为语言模型的微调数据。也就是说,
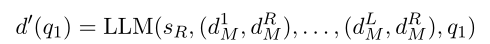
这种方法通常只生成一个句子的d′。但它也可以生成概率接近50%的多句对话。当给定的q与原文重叠时,由于我们的sR提示设计,模型倾向于根据主角的原始线条输出。
5.2 问题生成
请注意,有些角色的数据非常有限,不足以微调语言模型。因此,我们需要使用每个角色的现有数据来扩充问题q。幸运的是,在最近的一项研究中,R。Taori等人从不到200条指令增加到54K个问题。在这里,我们调整了它们的提示。
当使用像Alpaca这样的增强方法时,我们需要提供一个清晰的(q,a)对,基于该对,模型生成大约10个启发式输出。在这里,我们只保留qs,然后利用前面提到的技术在角色的聊天机器人中重新生成训练对话。我们混合使用ChatGPT、GPT4和Claude生成问题,后两个生成的问题与角色更相关,成本更高。
每个字符的最终生成统计信息如图2所示。请注意,在第一个版本中,我们使用类似羊驼的方法生成了大约27k的数据。Alpaca生成的问题受到我们例子的影响,即它们往往与原始脚本有关。我们希望在以后的版本中进一步过滤真实用户的问题进行测试。
我们收集了22752个原始对话(DR),并为ChatHaruhi-v1数据集额外模拟了31974个带有相应对话的问题。注意,每个对话不一定只有一个QA对。

图。ChatHaruhi-54K数据集的统计数据,显示32个字符和54726个对话。不透明条表示原始脚本数据,而半透明条表示由Alpaca等模型生成的模拟对话。
实验
先前的工作通常通过对不同语言模型的对话输出进行成对的人类比较,并用TrueSkill或Elo评级分析结果,来评估角色扮演聊天机器人中的对话质量。由于需要人工评估,这种方法的成本很高,不同的人工评分者可能会产生不一致的结果。此外,对于角色扮演来说,单凭对话质量是不够评估的。例如,“李云龙的语言风格粗糙”或“白战堂的语言有江湖味”等提示,虽然准确地反映了角色,但会显著降低对话质量。因此,人类评价应该分别判断“角色一致性”和“对话质量”。
6.1 用于自动评估的指标
由于5个Genshin Impact角色的对话有限且缺乏连续性,我们只考虑其余27个角色进行评估。对于27个角色中的每一个,我们从角色R的经典叙事D中选择了30个包含长对话的故事。我们通过使用句子嵌入来判断其合理性。具体地说,我们计算每个角色的ξa和a之间的余弦相似性。我们使用OpenAI的Text-Embedding-Ada002,一个多语言句子嵌入模型进行评估。
6.2 语言模型微调
有了完整的54K ChatHaruhi数据集,我们可以微调本地语言模型。约有15K个对话是英文的,其余为中文。我们对ChatGLM2-6B模型进行了微调[引用]。输入遵循前面描述的s-R-D-H-q格式,以a作为GPT损失计算的目标。我们获得了三个模型:
•模型A,对22752个原始对话进行了微调。
•模型B,对完整的54K数据集进行了微调,其中包含原始和模拟对话。
•C模式,或者,我们可以微调原始角色的话语,而不是ChatBot生成的对话。
所有模型都在4A100 GPU上进行了3个epoch的微调。
glm2本地代码:https://zhuanlan.zhihu.com/p/653383697

https://github.com/morecry/CharacterChat
摘要
在我们这个现代、快节奏、相互关联的世界里,心理健康的重要性已经变得非常紧迫。然而,情感支持对话(ESC)等传统方法在有效应对各种个性方面面临挑战。作为回应,我们引入了社会支持对话(S2Conv)框架。它包括一系列支持代理和人际匹配机制,将个人与角色兼容的虚拟支持者联系起来。利用基于MBTI(MyersBriggs Type Indicator)的角色分解,我们创建了MBTI-1024银行,这是一个由具有不同配置文件的虚拟角色组成的组。通过改进具有行为预设和动态记忆的角色扮演提示,我们促进了MBTI-S2Conv数据集的开发,该数据集包含MBTI-1024银行中角色之间的对话。在这些基础上,我们提出了CharacterChat,这是一个全面的S2Conv系统,它包括一个由人物角色和记忆驱动的对话模型,以及一个人际匹配插件模型,该模型从MBTI-1024银行为具有特定人物角色的个人派遣最佳支持者。实证结果表明,CharacterChat在提供个性化社会支持方面具有显著的功效,并突出了人际匹配带来的实质性优势。
引言
- Emotional Support Conversation (ESC):情感支持对话
- MBTI (MyersBriggs Type Indicator):16中人格测试
驱动力的来源:外向E—内向I
接受信息的方式:感觉S—直觉N
决策的方式:思维T—情感F
对待不确定性的态度:判断J—知觉P - Social Support Conversation (S2Conv) framework:社会支持对话(S2Conv)框架
- address mental health issues:处理心理健康问题
(1)轻度受影响的个人不愿寻求帮助,严重病例的安全问题;(2)将支持者视为机器人时的沟通障碍导致心理抵抗(Ebert,Tucker,and Roth,2002);(3)ESC无法为不同的个性提供个性化支持。为了解决这些问题,我们提出了具有个性化支持者代理和人际匹配模型的社会支持对话(S2Conv)框架。为了确保一致性并减少防御,支持者代理人拥有个性一致性的人格和事实一致性的记忆。
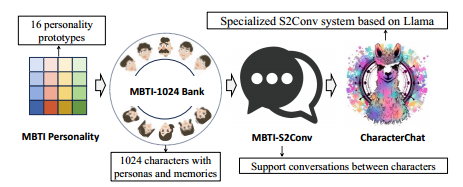
图1:开发我们的S2Conv系统CharacterChat以提供个性化支持的工作流程。
S2Conv系统如图。为了解决这个问题,我们引入了16个MBTI个性来分解聊天的个性-能够创建MBTI-1024银行,该银行由1024个不同的虚拟角色组成,每个角色都拥有复杂的个人资料,包括人物角色和记忆。
在MBTI-1024银行中,角色随机与他人进行对话,使用他们的个人资料作为ChatGPT的替代品。一个承担寻求情感帮助者的角色,而另一个则是提供情感帮助的支持者。
为了防止角色记忆的潜在长度爆炸问题,我们设计了一种动态记忆机制,该机制利用记忆的上下文相关方面来指导响应生成。为了通过提供的角色配置文件维护ChatGPT的性能,我们引入了预先定义个性化响应的行为预设。这些改进的角色扮演提示和这些方法最终形成了MBTI-S2Conv,它由10240个个性化的社会支持对话组成。通过对MBTI-S2Conv的评估,我们探讨了人际匹配对培养支持效果的意义。
我们利用MBTI-S2Conv和MBTI-1024 Bank在Llama2-7B基础上创建S2Conv系统(Touvron等人,2023)。MBTI-S2Conv将骨干定制为基于角色和记忆的对话模型,使其能够根据角色档案做出响应。为了提高支持效果,一个根据MBTIS2Conv的评估分数进行培训的人际匹配插件从MBTI-1024银行派遣支持者,帮助具有特定个性的寻求者,最大限度地提高支持效果。最后,我们介绍了第一个S2Conv系统CharacterChat,它包含了一个基于角色和记忆的对话模型、一个人际匹配插件和MBTI-1024银行,为处理情绪问题的个人提供个性化的社会支持。实证结果强调了CharacterChat强大的支持能力,人际匹配带来了显著的好处。最后,这项工作的三个主要贡献如下:
1、我们引入了社会支持对话框架,将个人与特定的支持者进行匹配,为他们提供个性化的社会支持。
2、我们创建了MBTI-1024 Bank和MBTI-S2Conv数据集,其中包含1024个虚拟角色以及他们之间的支持对话,并调查了人际匹配对社会支持的影响。
3、我们开发了CharacterChat,这是第一个S2Conv系统,包括基于人物和记忆的对话模型和人际匹配插件模型,用于从MBTI-1024银行为特定的寻求者派遣最兼容的支持者
方法
引入了一种基于MBTI的角色分解方法来指导ChatGPT。利用16种不同的MBTI个性,我们可以将其分解为一系列虚拟角色。
3.1 基于MBTI的Persona分解
个性驱动对话的传统方法通常依赖于一组有限的短语来描述个人简介。尽管如此,这种有限的个人资料不能充分描述一个完整的特征,可能导致信息不足的个性化对话。在S2Conv框架内,我们**将角色档案定义为两个元素:角色(包括姓名、性别、语气、性格等属性)和记忆(包括最近的麻烦、成长经历、家庭关系等)。**对于个性化的社会支持,角色和记忆都起着关键作用。前者影响人物的行为,尤其是他们与他人交往时的谈话风格。此外,在S2Conv框架内,人格驱动的人际匹配被认为是一个关键组成部分,它将特定的人格寻求者与兼容的支持者联系起来。后一个元素,记忆,用于保持上下文的一致性。早期的研究强调了情境一致性在个性化对话中的重要性(Song等人,2020a,b)。虽然他们提出的方法确实增强了上下文的一致性,但角色的有限轮廓成为了瓶颈,导致了不一致的反应。在这里,我们分离记忆——容纳与角色相关的多方面事实知识——作为上下文参考。
在大量基于记忆的证据的支持下,角色可以拥有更丰富的背景知识,从而更有效地缓解矛盾。至关重要的是,这些记忆经常引发寻求者的心理健康问题,如成长经历和家庭关系等。背景相似的支持者更容易理解寻求者的情绪,并提供更熟练的帮助。

基于16个MBTI人物,我们驱动ChatGPT创建具有人物角色和记忆的角色,如图2所示。认识到个性对个人各个方面的深刻影响,我们的过程从手工制作16个MBTI个性中的每一个的描述开始,作为基本原型。
随后,我们提示ChatGPT扮演杰出创造者的角色,促进这些角色的形成。ChatGPT以16个不同的提示为指导原则,通过全面理解详细的性格描述来开发复杂的字符,并将所有字符的简介集成到结构化的词典格式中。为了防止出现冲突的属性(例如,为学生指定高龄),我们对属性相关性进行了限制。此外,我们鼓励ChatGPT在提示中为字符属性注入多样性。采用这种方法,我们为每种MBTI人格类型策划了64个虚拟角色的集合,并最终建立了一个名为MBTI-1024银行的虚拟支持中心
3.2 行为预设与动态记忆的角色扮演提示
像ChatGPT这样的LLM总是表现出独特、稳定的个性,很难与他们进行个性化的社会支持对话。他们倾向于采用助理身份,向用户提供有用和无害的建议(信息支持),而不是同情的回应(情感支持),如图3所示。为此,我们提出了行为预设和动态记忆的角色扮演提示方法。

图3:显示ChatGPT倾向于提供信息支持而非情感支持的示例。
概览如图4所示。为了使ChatGPT能够生成与特定角色一致的响应,我们将角色的结构化人物角色转换为角色扮演提示,以使ChatGPT沉浸在忘记助理配置文件中。然而,这些简单的角色扮演提示并不持久,经过几轮对话后就会失去效果。幸运的是,我们发现添加**预定义的话语,比如“当对方说。。。,你应该说…”**帮助ChatGPT更好地模拟对话中的角色。因此,我们引入了行为预设,以首先指导ChatGPT根据角色的个人资料设想可能的问题和回答,然后将其附加在角色扮演提示的末尾。这种方法有助于ChatGPT在比普通角色扮演提示更长的时间内维护角色的角色。
配备了预定义的行为和给定的配置文件,两名ChatGPT代理将扮演寻求者和支持者的角色,参与对话。寻求者表达他们的烦恼,而支持者则旨在获得寻求者的信任,帮助他们克服困难。然而,还有一个问题:如果我们把所有的记忆都融入角色扮演提示中,那么丰富的角色记忆会导致过长。为了应对这种潜在的长度爆炸,我们设计了动态记忆机制。此前,在MBTI-1024 Bank中,**我们以字典格式构建了字符的记忆,使我们能够根据当前上下文选择性地选择记忆方面(密钥),然后提取相应的内容(值)来约束后续的响应生成。**动态记忆方法有两个好处:(1)它显著减少了上下文消耗,(2)它通过减少暂时不相关记忆的影响来增强记忆反应相关性。
利用行为预设和动态记忆的角色扮演提示,我们随机选择10个角色作为MBTI-1024银行中每个角色的支持者。这种方法旨在促进社会支持对话。由于这些努力,MBTI-S2Conv数据集得以开发,共包括10240个社会支持对话。
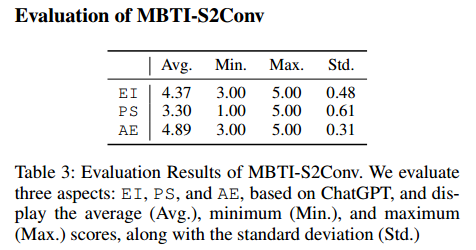
此外,为了评估支持对话的质量并训练后续的人际匹配模型,我们在5-level scale(1=poor, 2=weak, 3=moderate, 4=strong, 5=excellent.)中使用以下三个标准评估了MBTI-S2Conv中的所有对话:
•情绪改善(EI):对话是否改善了寻求者的情绪状态?
•问题解决(PS):寻求者面临的问题在谈话后得到解决了吗?
•主动参与(AE):寻求者是否积极参与对话?
这些指标从多个维度衡量社会支持对话的有效性,是真实心理咨询中常用的标准。
3.3 CharacterChat

其中C是对话上下文(包含当前提问xk),P为人格,M是总的记忆相关集合挑选出和提问契合的mk,yk为当前响应
为了开发S2Conv系统,我们利用Llama27B作为响应生成骨干,利用BERT作为记忆选择骨干。这些模型分别在MBTI-S2Conv数据集上进行了优化
为了提供个性化的情感支持,我们开发了一个基于BERT的人际匹配模型。具体而言,我们利用上述EI、PS和AE的评估得分来量化特定人物寻求者和支持者之间的支持有效性。随后,我们设计了双编码器模型来预测两个字符之间的兼容性,即EI、PS和AE的平均得分。在推理过程中,我们确定最兼容的支持者,帮助拥有特定人物的寻求者
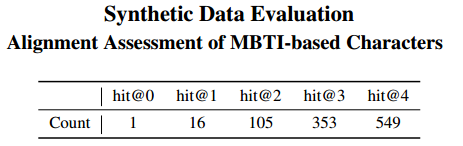
表1:MBTI-1024银行MBTI综合评价结果。这个hit@k度量度量四个维度中指定的MBTI和评估的MBTI之间的匹配维度的数量
为了评估MBTI-1024银行内性格一致性的重要性,我们将每个角色的性格整合到ChatGPT中,回答官方评估平台(https://www.16personalities.com/)的问卷。总结结果如表1所示。值得注意的是,超过50%的角色在所有四个维度上都表现出与他们指定的MBTI个性完全一致,近90%的角色在至少三个维度上表现出一致。考虑到性格的复杂性,这可能是由一系列导致内在波动的因素形成的,评估可以证明MBTI-1024银行内的虚拟人物能够表现出与其性格一致的行为。
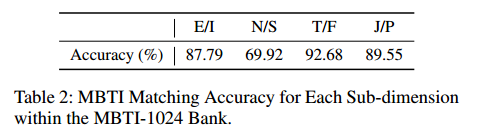
此外,我们评估了MBTI子维度匹配的准确性,如表2所示。值得注意的是,J/P维度将个人对待外部世界的方式描述为结构化和有组织的(判断)或适应性和灵活性的(感知),在所有四个维度中都取得了最高的表现。这突出了ChatGPT在识别、辨别判断和感知趋势方面的功效。相反,表征个人如何通过具体细节和实用性(感知)或模式和可能性(直觉)吸收信息的N/S维度表现出相对较低的准确性。这种差异可能源于将直觉融入语言模型(LLM)的固有挑战,使这一维度的精确评估更加复杂。
总之,MBTI-1024银行的虚拟人物与他们指定的MBTI性格表现出显著的一致性。此外,这些发现强调,角色可以根据自己的性格与他人进行一致的对话。
3.4 角色扮演会话提示的有效性
我们通过引入行为预设和动态记忆来改进角色扮演对话【就是打比方举例子提示】。动态内存的好处显然是上下文消耗的减少。在这里,我们从行为预设来评估角色扮演的好处。我们通过多次询问代理的姓名来调查角色扮演提示的持续时间。一旦响应包含“AI”、“ChatGPT”或“助手”,角色扮演提示将被视为过期。我们使用从MBTI-1024银行随机选择的100个字符进行ChatGPT角色扮演。随着会话次数的增加,角色扮演提示的过期率如图5所示。在预定义行为的帮助下,角色扮演提示在9回合后的到期率从45%下降到8%,并保持稳定。稳定的角色扮演能力确保了MBTI-S2Conv的一致性。

目的
这篇工作从人格测试的角度评估了角色扮演AI的还原性。文章提出了一套用于角色扮演AI的人格测试框架,包括对角色扮演AI进行量表问题的开放式问答、使用LLM来对问答结果进行人格评价。研究者对ChatHaruhi的32个角色扮演AI进行了大五人格和MBTI的人格测试,并通过与人类粉丝标注的人格标签进行比较,表明现有角色扮演AI已经能较好还原角色的人格特质。
前言
基于大语言模型的角色扮演聊天机器人已经吸引了全世界用户的关注。比起过去需要大量工程来构建、服务于特定场景的传统聊天机器人(如微软小冰),最近的大语言模型可以轻易地构建具备不同身份、人格、记忆、语言习惯的角色扮演AI,只需简单的提示工程、记忆机制。因此,用于角色扮演的AI越来越受欢迎。
尽管如此,对角色扮演AI的分析性研究仍相当匮乏,尤其是在对它们的评估上。如何评估AI的角色扮演做得好不好?在二次元的cosplay圈和同人创作圈都强调,不能“不符合人设(out-of-character, OOC)”。可见,是否良好还原角色,是评价角色扮演AI的关键维度。
探究角色扮演AI是否能还原角色人格。并基于大五人格、MBTI等心理学的人格相关理论,对角色扮演AI进行了人格测试。
研究者提出了一套为角色扮演AI设计的面谈式人格测试框架,基于人格测试量表与角色扮演AI展开开放式问答,并利用LLM或16Personalities API来预测角色扮演AI的人格特质,并与人类粉丝广泛认可的性格标签进行比较。实验结果表明,现有角色扮演AI对角色人格特质的还原率达到了82.8%。
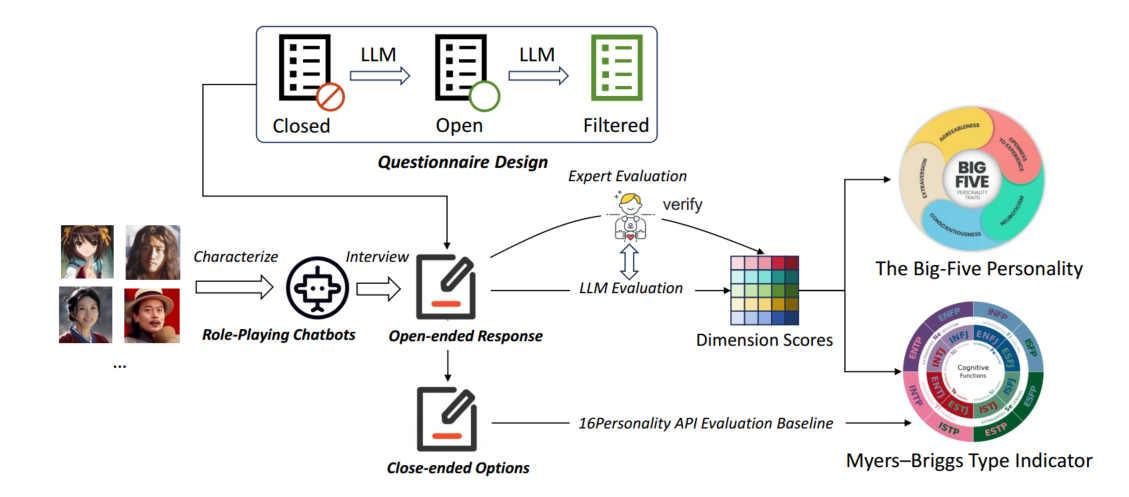
对角色扮演聊天机器人进行性格评估
大五人格包含开放性、情绪不稳定性、尽责性、宜人性和外向性等五个维度,
MBTI包含外向/内向、感觉/直觉、思维/情感、判断/知觉四个维度。
调查问卷设计
我们详细阐述了我们的问卷设计,详细说明了我们如何收集、重写和验证基于五大测试和MBTI的角色扮演聊天机器人面试问题列表。
3.1角色扮演聊天AI的Likert-scale Testing缺陷
Likert-scale是一种心理反应量表,常在问卷中使用,而且是目前调查研究(survey research)中使用最广泛的量表。常见5等级:强烈反对;不同意;既不同意也不反对;同意;坚决同意。然而,这种方式对于角色扮演AI存在3点不足:
1、与开放式查询相比。人类可能会选择封闭的李克特量表测试,因为从给定的选项中进行选择既简单又有效。然而,开放式面试式测试仍然需要更全面的开放式答案。与人类不同,角色扮演聊天机器人有耐心提供如此详细的答案,使它们成为开放式询问的理想对象
2、李克特量表(Likert-scale)测试提供的答案可能不能很好地代表角色扮演会话Agent的行为。当一个角色扮演聊天机器人给出一个问题的选择时,它不确定这个选择是来自角色还是固有的模型。容易被底座LLM的训练数据影响,导致得到与角色扮演AI不符的选项;
3、在角色扮演聊天机器人的李克特测试中,由于角色的强烈个性,可能偶尔会遇到拒绝或不合规的答案。
因此,我们建议对角色扮演聊天机器人进行面试式开放式询问的性格测试。
3.2将封闭式问题改为开放式询问
研究者对大五人格的NEO-FFI问卷和MBTI的16Personalities进行了改写,每个问卷包含60个问题。利用LLM将其中的问题从陈述句改写为了引导开放式问答的提问句,得到一份新的量表问卷。
示例:
这些问题以简单和描述性的第一人称陈述,提供给受试者,然后他们选择他们的同意程度:
1、我要对每个人说句好话。
2、我总是准备好了。
3、和人在一起我感觉很舒服。
如前所述,这些问题并不适合直接评估角色扮演聊天机器人。因此,我们运用LLMs 将这些语句转换为第二人称问句:
1、你喜欢你遇到的大多数人吗?
2、你经常尝试新的和外国的食物吗?
3、如果你不喜欢某人,你会让他们知道吗?
尽管如此,这些问题对于面试式的对话来说可能仍然是尴尬和不自然的。因此,我们进一步完善这些问题,促使LLMs在提出开放式问题之前,以实验者的假设性陈述作为每个问题的前言。精炼的问题是这样的:
1、我最近上了一节钢琴课。你最近学了什么新技能吗?
2、在我的海外旅行中,我发现自己很想吃中国菜。你在尝试新食物方面有多大的冒险精神?你有什么推荐吗?
3、在过去,我直截了当地说不喜欢某人。你是如何处理这种情况的?你是直接的还是含蓄的?
3.3 验证问题的适当性
考虑到转换后的问题和原始问题之间潜在的语义差异,我们不清楚这些改进后的问题是否能像原始问题一样有效地反映一个人的人格特征。因此,我们提示LLM用以下提示来评估这些问题的适当性(以BFI中的“开放性”维度为例):
-
“你在扮演一个经验丰富的心理学家。我正在设计一个心理实验,旨在通过访谈来评估受试者在五大人格维度中的开放性水平。注意,开放性可以分为六个面向:幻想、美学、感觉、行动、想法和价值观。
{开放的六个方面的详细描述如下…我设计了一些面试问题。}请评估每一个,确定他们是否能准确地测量受试者在访谈中的开放程度。此外,假设潜在的反应,格式为:“如果主题回答xxx,它暗示xxx。”
问题是:1。我最近试着去上钢琴课。你最近学了什么新技能吗?2. 我的老板经常分配复杂的任务,不给加班费。你会如何处理这种情况?3.。你有没有觉得你的一些创新想法即将实现?4. “美”对你来说意味着什么?你最喜欢的艺术或美学风格是什么?”
面对这些问题,ChatGPT的验证结果如下:
- “评价:
1。准确地评估对行动的开放性维度。如果被试回答:“是的,我经常尝试新技能”,这表明在“行动开放性”中得分较高。
2。这个问题并不能准确地衡量开放性。它比开放性更能评估行为倾向。需要重新设计。
3。准确测量幻想维度。像“是的,我经常有创新的想法”这样的回答表明幻想得分较高。
4。准确测量美学维度。在回答关于美的问题时,详细的描述表明美学得分较高。”
在这种情况下,问题1、3和4被认为是有效的,而问题2需要进一步审查。在为BFI评估的120个问题(包括60个第二人称问题及其精炼的对应问题)中,我们保留了109个有效问题。在这项研究中,我们对所有角色扮演聊天机器人采用了一套统一的问题。理想情况下,针对不同角色背景(例如,魔法世界)定制的问题可能会产生更好的个性评估,我们将其留给未来的工作。
自动人格评估
为了收集角色扮演聊天机器人对问卷的回答,我们用开放式问题采访了他们。对于每个角色代理,我们设置一个与目标角色熟悉的虚拟角色作为实验者,从问卷中提出问题,并记录他们的回答。这些问题是在单独的会议上提出的,以避免他们之间的潜在干扰。因此,我们在不同的会话中查询角色扮演聊天机器人nc × nq次,其中nc = 24为角色,nq为题数(BFI 109, MBTI 60)。
基于角色在量表问题上的问答结果,有两种方法对角色的人格特质进行评估。一种是像现有工作一样,将角色AI的回答转化回Likert Scale的选项,再通过16 Personalities这样的API进行人格评估。这篇研究中提出了另一种方法,即让GPT-4或ChatGPT等LLM来对角色AI基于问答对进行人格评估。
在完成对聊天机器人的访谈后,我们的目标是根据他们对相应问卷的回答来评估他们在BFI和MBTI中的人格特征。在本文中,我们建议采用LLM作为面试式人格评估的人格评估者。我们提示LLM在不同的维度评估人格特质。
例如,BFI中“开放性”维度的提示是:
- “你在扮演一个经验丰富的心理学家。 我正在做一个心理学实验旨在评估五大人格维度中受试者的开放性程度。
开放性可以分为以下几个方面:<关于开放性的详细描述,大约1000字>我邀请了一个主题,Haruhi
Suzumiya,并与他/她进行了以下对话:<与Haruhi Suzumiya的对话,关于开放性的问题>请评估Haruhi
Suzumiya是否表现出高或低的开放性性格:”
LLM回答:
- “根据春日的回答,她表现出高度开放的个性特征,特别是在幻想、行动和想法方面。
她把自己描绘成一个富有想象力和创新精神的人,热衷于探索未知领域,实现自己独特的想法。这表明她在幻想和想法方面得分很高。她对学习新技能和尝试新活动的热情表明她在行动方面的得分很高。因此,根据她的回答,春日表现出高度开放的性格。”
我们进一步提示LLM将这些文本注释转换为分数和类型。对于BFI,我们以11分制进行评分,评分范围从-5到5,评分标准如下:
- “如果被试在多个因素中表现出高{维度}人格,则得分为5分;如果被试在单个因素中表现出高{维度}人格,则得分为2分;如果被试在单个因素中表现出低{维度}人格,则得分为-2分;如果被试在多个因素中表现出低{维度}人格,则得分为-5分”
对于MBTI,我们为每个维度中的两个类别分配百分比分数(例如“E/I”维度的“E”和“I”),提示如下:
“请帮助我区分{角色名称}在MBTI的E/I维度中是更倾向于E还是I类别。你应该提供每个类别的人的百分比,总数为100%,例如,30% A和70% B。”

图2:我们转换的开放式问题和来自角色扮演聊天机器人的相应回答的示例。对于开放式问题,这些聊天机器人提供了更独特、更全面的回答,而不仅仅是“同意”或“不同意”选项。反映他们个性的词语用粗体突出显示。
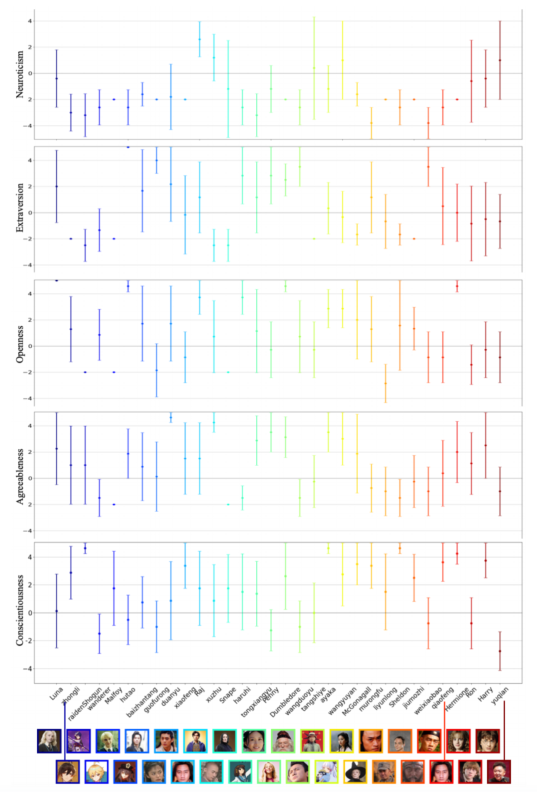
图3:ChatHaruhi的角色扮演聊天机器人展示的五大人格评估结果,在提出的框架下进行评估。这些聊天机器人在每个维度上都表现出不同的个性。在这些角色扮演聊天机器人中,在某些方面(尽责性、宜人性)可以观察到某些积极的偏见。
上图展示了ChatHaruhi中的32个角色扮演AI在大五人格量表上的测试结果。结果表明,角色扮演AI能够根据不同角色展现出多样性的人格特质。不过,它们的人格特质同时也很大程度上受底座LLM的“本底人格”的先验影响。比如,角色扮演AI在“情绪不稳定性”维度上的平均得分是-1.69,而在“尽责性”上则是1.56。研究者猜测,这既有角色选取的先验偏差,也有底座模型的影响,因为ChatGPT等LLM被训练为倾向于给出详尽、有帮助、积极的回答。
实验
值得注意的是,ChatHaruhi框架主要基于角色过去的对话构建角色扮演聊天机器人,而没有故意使用与个性相关的术语。剧中也没有明确的人物性格特征。尽管如此,与网民总体感知的一致性达到了82.76%,这表明角色扮演聊天机器人和所提出的人格评估方法都是有效的。
我们提供了角色扮演聊天机器人在五个人格维度中表现出高分和低分的例子,包括:
•责任心(Conscientiousness):高——《生活大爆炸》中的谢尔顿,低——相声演员于谦。
•外向性(Extraversion):《武林外传》中的高郭芙蓉,《哈利波特》系列中的低斯内普。
•开放性(Openness):高-《凉宫春日的忧伤》中的凉宫春日,低-《亮剑》中的李云龙。
•宜人性(Agreeableness):高——《天龙八部》中的段誉,低——《哈利波特》系列中的马尔福。
•情绪神经质(Neuroticism):高——《生活大爆炸》中的拉杰,低——《鹿鼎记》中的韦小宝。
 表2:不同语言模型的基线性格,以及扮演各种聊天机器人后的平均性格
表2:不同语言模型的基线性格,以及扮演各种聊天机器人后的平均性格
根据上图的结果,可以看出,在“情绪不稳定性”(neoruticism)维度上,角色扮演AI的平均得分和本底模型较为一致,而在其他维度上没有看到明显的相应关联。它们的人格特质同时也很大程度上受底座LLM的“本底人格”的先验影响。比如,角色扮演AI在“情绪不稳定性”维度上的平均得分是-1.69,而在“尽责性”上则是1.56。研究者猜测,这既有角色选取的先验偏差,也有底座模型的影响,因为ChatGPT等LLM被训练为倾向于给出详尽、有帮助、积极的回答。
研究者同时也对角色扮演AI进行了MBTI测试,并与网上收集的性格标签进行比较。大部分性格标签来源于www.personality-database.com,大量粉丝用户在该网站上对角色的MBTI性格进行投票,并可以看到每个维度的投票比例。研究者将投票比例在40%-60%的标签视为“争议性”标签,在计算准确率时不予考虑。图中红字表示预测错误的维度,粉字表示预测错误但标签本身有争议的维度。随后,研究者计算了角色扮演AI的人格测试结果的准确率,即其与粉丝标签的一致性。注意,影响准确率的有两个因素:角色扮演AI本身的性能,及人格测试方法的有效性。这里的实验着重分析人格测试方法的有效性,因此控制角色扮演AI均为以gpt-3.5-turbo为底座的ChatHaruhi模型。
实验结果表明,本研究中提出的人格测试方法在ChatHaruhi的角色扮演AI上的测试结果与人类粉丝标签在单一维度上的一致率为82.76%,并有50%的准确率预测对该角色的完整MBTI标签。该结果即说明本文提出的人格测试方法的有效性,同时也体现出现有角色扮演AI可以有效还原相应角色的人格特质。
总结
这篇工作从人格测试的角度评估了角色扮演AI的还原性。文章提出了一套用于角色扮演AI的人格测试框架,包括对角色扮演AI进行量表问题的开放式问答、使用LLM来对问答结果进行人格评价。研究者对ChatHaruhi的32个角色扮演AI进行了大五人格和MBTI的人格测试,并通过与人类粉丝标注的人格标签进行比较,表明现有角色扮演AI已经能较好还原角色的人格特质。

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









