









工作队列
- python pika
- 循环调度
默认来说,RabbitMQ会按顺序得把消息发送给每个消费者(consumer)。平均每个消费者都会收到同等数量得消息。这种发送消息得方式叫做——轮询(round-robin) - 消息确认
为了防止消息丢失,RabbitMQ提供了消息响应(acknowledgments)。消费者会通过一个ack(响应),告诉RabbitMQ已经收到并处理了某条消息,然后RabbitMQ就会释放并删除这条消息。
如果消费者(consumer)挂掉了,没有发送响应,RabbitMQ就会认为消息没有被完全处理,然后重新发送给其他消费者(consumer)。这样,及时工作者(workers)偶尔的挂掉,也不会丢失消息。
通过设置no_ack=True将默认消息响应关闭 - 消息持久化
为了确保信息不会丢失,有两个事情是需要注意的:我们必须把“队列”和“消息”设为持久化。
# 队列声明为持久化(durable)
channel.queue_declare(queue='hello', durable=True)
# 消息也要设为持久化——将delivery_mode的属性设为2
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
- 公平调度
RabbitMQ只管分发进入队列的消息,不会关心有多少消费者(consumer)没有作出响应
解决:可以使用basic.qos方法,并设置prefetch_count=1。这样是告诉RabbitMQ,再同一时刻,不要发送超过1条消息给一个工作者(worker),直到它已经处理了上一条消息并且作出了响应。这样,RabbitMQ就会把消息分发给下一个空闲的工作者(worker)。
channel.basic_qos(prefetch_count=1)
发布/订阅
交换机(Exchange)
- 发布者(producer)只需要把消息发送给一个交换机(exchange)。
- 交换机非常简单,它一边从发布者方接收消息,一边处理它接收到的消息。是应该推送到指定的队列还是是多个队列,或者是直接忽略消息。这些规则是通过交换机类型(exchange type)来定义的。
直连交换机(direct), 主题交换机(topic), (头交换机)headers和 扇型交换机(fanout)
临时队列
创建临时队列:调用queue_declare方法的时候,不提供queue参数(生成随机队列名)
result = channel.queue_declare()
当与消费者(consumer)断开连接的时候,这个队列应当被立即删除。exclusive标识符即可达到此目的。
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs',
queue=queue_name)
不允许发布消息到不存在的交换器。
如果没有绑定队列到交换器,消息将会丢失。
如果没有消费者监听,那么消息就会被忽略。
路由(Routing)
如何只订阅消息的一个字集?
绑定(Bindings)
创建一个带绑定键的绑定:
channel.queue_bind(exchange=exchange_name,
queue=queue_name,
routing_key='black')
绑定键的意义取决于交换机(exchange)的类型。我们之前使用过的扇型交换机(fanout exchanges)会忽略这个值。
直连交换机(Direct exchange)
扇型交换机(fanout exchange)没有足够的灵活性 —— 它能做的仅仅是广播。
直连交换机(Direct exchange):交换机将会对绑定键(binding key)和路由键(routing key)进行精确匹配,从而确定消息该分发到哪个队列。
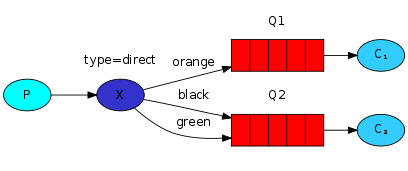
多个绑定(Multiple bindings)
模拟扇型交换机的行为,将消息广播到所有匹配的队列
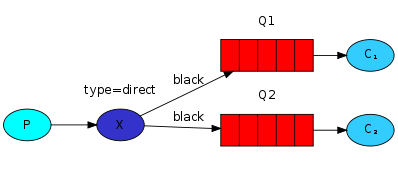
多个队列使用相同的绑定键是合法的
代码整合:
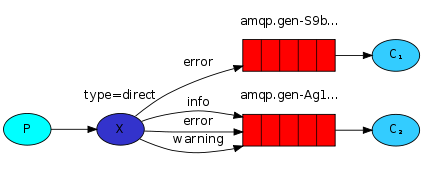
emit_log_direct.py
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print " [x] Sent %r:%r" % (severity, message)
connection.close()
receive_logs_direct.py
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
print >> sys.stderr, "Usage: %s [info] [warning] [error]" % \
(sys.argv[0],)
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
print ' [*] Waiting for logs. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] %r:%r" % (method.routing_key, body,)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
主题交换机
如何基于多个标准执行路由操作?
定义
发送到主题交换机(topic exchange)的消息不可以携带随意什么样子的路由键(routing_key),它的路由键必须是一个由.分隔开的词语列表。词语的个数可以随意,但是不要超过255字节。
绑定键和路由键有两个特殊应用方式:
* (星号) 用来表示一个单词.
# (井号) 用来表示任意数量(零个或多个)单词。
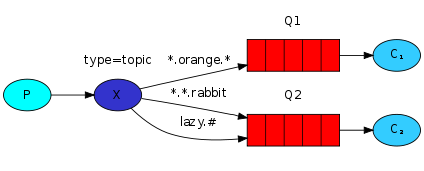
这三个绑定键被可以总结为:
Q1 对所有的桔黄色动物都感兴趣。
Q2 则是对所有的兔子和所有懒惰的动物感兴趣。
当一个队列的绑定键为 “#”(井号) 的时候,这个队列将会无视消息的路由键,接收所有的消息。
当 * (星号) 和 # (井号) 这两个特殊字符都未在绑定键中出现的时候,此时主题交换机就拥有的直连交换机的行为。
emit_log_topic.py
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print " [x] Sent %r:%r" % (routing_key, message)
connection.close()
receive_logs_topic.py
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
print >> sys.stderr, "Usage: %s [binding_key]..." % (sys.argv[0],)
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print ' [*] Waiting for logs. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] %r:%r" % (method.routing_key, body,)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
执行下边命令 接收所有日志:
python receive_logs_topic.py “#”
执行下边命令 接收来自”kern“设备的日志:
python receive_logs_topic.py “kern.*”
执行下边命令 只接收严重程度为”critical“的日志:
python receive_logs_topic.py “*.critical”
执行下边命令 建立多个绑定:
python receive_logs_topic.py “kern." ".critical”
执行下边命令 发送路由键为 “kern.critical” 的日志:
python emit_log_topic.py “kern.critical” “A critical kernel error”
踩坑记
阿里云部署消费者发现一两天内就会把cpu占满,开始以为是ffmpeg的的原因,于是设置-threads 1,但是发现并不能解决问题,于是怀疑是rabbitmq的原因,遍查网络最终确定是旧版本pika的bug,将其更新就ok了?
遇到这种情况建议进行cpu使用分析
TODO
RabbitMQ vs. ZeroMQ















 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









