









笛卡尔树[编辑]
笛卡尔树是一种特定的二叉树数据结构,可由数列构造,在范围最值查询、范围top k查询(range top k queries)等问题上有广泛应用。它具有堆的有序性,中序遍历可以输出原数列。笛卡尔树结构由Vuillmin(1980)[1]在解决范围搜索的几何数据结构问题时提出。从数列中构造一棵笛卡尔树可以线性时间完成,需要采用基于栈的算法来找到在该数列中的所有最近小数。
定义[编辑]
无相同元素的数列构造出的笛卡尔树具有下列性质:
- 结点一一对应于数列元素。即数列中的每个元素都对应于树中某个唯一结点,树结点也对应于数列中的某个唯一元素
- 中序遍历(in-order traverse)笛卡尔树即可得到原数列。即任意树结点的左子树结点所对应的数列元素下标比该结点所对应元素的下标小,右子树结点所对应数列元素下标比该结点所对应元素下标大。
- 树结构存在堆序性质,即任意树结点所对应数值大/小于其左、右子树内任意结点对应数值
根据堆序性质,笛卡尔树根结点为数列中的最大/小值,树本身也可以通过这一性质递归地定义:根结点为序列的最大/小值,左、右子树则对应于左右两个子序列,其结点同样为两个子序列的最大/小值。因此,上述三条性质唯一地定义了笛卡尔树。若数列中存在重复值,则可用其它排序原则为数列中相同元素排定序列,例如以下标较小的数为较小,便能为含重复值的数列构造笛卡尔树。
笛卡尔树应用[编辑]
范围最值查询与最低公共祖先[编辑]
笛卡尔树可以有效地处理范围最值查询(range minimum queries),通过将定义在数列上的RMQ问题转化为定义在树结构上的最低公共祖先(lowest common ancestor)问题。数列以线性时间构造出笛卡尔树,笛卡尔树则能以常数时间处理最低公共祖先查询,因此在线性时间的预处理后,范围最值查询能以常数时间完成。
Bender & Farach-Colton (2000)[2]则提出了RMQ与LCA问题的新联系,他们通过不基于树的算法处理RMQ问题从而有效地解决LCA问题。其使用欧拉路径的技巧将树结构转化为数列,此数列具有特定性质(相邻数值代表树中的相邻顶点,即在树中高度差为1的顶点),利用这一性质RMQ问题可以很高效地得到解决。通常的数列则不具备此性质,为了将一般的数列转化为具有上述性质的数列,需要应用到笛卡尔树,具体过程为在普通数列上构造笛卡尔树,在笛卡尔树上使用欧拉路径转化的方法将树转化为具有上述性质的新数列。
范围最值查询问题也可以解释为二维范围查询问题,或者三边范围查询问题(three sided range queries),笛卡尔平面上的有限点集可以用来构造笛卡尔树,首先将这些点按照x取值排序,然后将y值作为数列中元素的值,以此数列建立笛卡尔树。若 S 为有限点集中满足  条件的点集,设 p 是 S 中x值最小的点,q 是 S 中 x 值最大的点,则笛卡尔树中 p 与 q的最低公共祖先即为该点集中处于该x值范围内y值最高/低的点 b。三边范围查询问题,即给定条件
条件的点集,设 p 是 S 中x值最小的点,q 是 S 中 x 值最大的点,则笛卡尔树中 p 与 q的最低公共祖先即为该点集中处于该x值范围内y值最高/低的点 b。三边范围查询问题,即给定条件  ,取出所有满足条件的点。其解决是以笛卡尔树找到b 点,若b点的y 值满足条件,则递归地在 p, b 所约束的子树以及b, q 所约束的子树内重复这一过程,这一查询可以使每个被报告的点都在常数时间内找到,总体的时间复杂度为
,取出所有满足条件的点。其解决是以笛卡尔树找到b 点,若b点的y 值满足条件,则递归地在 p, b 所约束的子树以及b, q 所约束的子树内重复这一过程,这一查询可以使每个被报告的点都在常数时间内找到,总体的时间复杂度为  ,k即为满足条件的点数。
,k即为满足条件的点数。
笛卡尔树同样可以应用于以常数时间查询超度量空间内点对的距离。超度量空间内距离的定义与最宽路径问题中的权重相同。从最小生成树上可以构造一个笛卡尔树,根结点表示最小生成树中的权值最大的边,撤去此边会将最小生成树分割为两个子树,笛卡尔树递归地从这两棵子树上构造。笛卡尔树的叶结点表示度量空间内的点,两个叶结点的最低公共祖先则是这两个点在最小生成树中最重的边,代表这两点间的距离。获得了最小生成树及将边按照权值排序后,笛卡尔树即可在线性时间内构造出来。
treap[编辑]
笛卡尔树是二叉树,对于数列而言将其作为二叉搜索树是自然的。若将二叉搜索树结点关联上一个权值,并且保证此权值在树结构中遵循堆中的序关系,即父结点权值比子结点权值大,则此二叉搜索树又被称为Treap. 其名称来源于树与堆两英文词的组合(tree + heap -> treap)。Treap与笛卡尔树在结构上是相同的,只是两者的应用不同。
题目链接:http://poj.org/problem?id=2201
题目大意:
让你构造一棵笛卡尔树。
笛卡尔树的节点含有2个值,1个key,一个value,其中key是主键,value是辅键。一棵笛卡尔树就是:key升序,value升序或者降序。类似堆。
与treap的区别是:treap的value是随机值,是为了使树更加平衡引进的,而笛卡尔树的value是一个确定的值。
结构完全相同,功能不一样。理解这一点就知道什么时候用treap,什么时候用笛卡尔树了。
笛卡尔树相关链接:
http://zh.wikipedia.org/wiki/%E7%AC%9B%E5%8D%A1%E5%B0%94%E6%A0%91
http://en.wikipedia.org/wiki/Cartesian_tree
代码如下:
- #include<iostream>
- #include<cstring>
- #include<cstdio>
- #include<algorithm>
- #include<cmath>
- using namespace std;
- const int N = 50010;
- int stack[N];
- int pre[N], lson[N], rson[N];
- struct node{
- int key, value, id;
- }st[N];
- bool operator <(const node &a, const node &b){
- return a.key < b.key;
- }
- void init(int n)
- {
- memset(stack, -1, sizeof(stack));
- for(int i = 1; i <= n; ++i)
- pre[i] = lson[i] = rson[i] = 0;
- }
- void Build_Cartesian_Tree(int n)
- {
- int k, top = -1;
- for(int i = 0; i < n; ++i)
- {
- k = top;
- while(k >= 0 && st[stack[k] + 1].value > st[i + 1].value) //第一个小于i的位置
- --k;
- if(k != -1)
- {
- pre[st[i + 1].id] = st[stack[k] + 1].id;
- rson[st[stack[k] + 1].id] = st[i + 1].id;
- }
- if(k < top) //左旋
- {
- pre[st[stack[k + 1] + 1].id] = st[i + 1].id;
- lson[st[i + 1].id] = st[stack[k + 1] + 1].id;
- }
- stack[++k] = i;
- top = k;
- }
- pre[st[stack[0] + 1].id]= 0; //根节点
- }
- int main()
- {
- int num;
- while(scanf("%d", &num) != EOF)
- {
- init(num);
- for(int i = 1; i <= num; ++i)
- {
- scanf("%d%d", &st[i].key, &st[i].value);
- st[i].id = i;
- }
- sort(st + 1, st + num + 1); //按key排序
- Build_Cartesian_Tree(num);
- printf("YES\n");
- for(int i = 1; i <= num; ++i)
- printf("%d %d %d\n", pre[i], lson[i], rson[i]);
- }
- return 0;
- }
| Time Limit: 10000MS | Memory Limit: 65536K | |
| Total Submissions: 2950 | Accepted: 1122 | |
| Case Time Limit: 2000MS | ||
Description
That is, if we denote left subtree of the node x by L(x), its right subtree by R(x) and its key by kx then for each node x we have
- if y ∈ L(x) then ky < kx
- if z ∈ R(x) then kz > kx
The binary search tree is called cartesian if its every node x in addition to the main key kx also has an auxiliary key that we will denote by ax, and for these keys the heap condition is satisfied, that is
- if y is the parent of x then ay < ax
Thus a cartesian tree is a binary rooted ordered tree, such that each of its nodes has a pair of two keys (k, a) and three conditions described are satisfied.
Given a set of pairs, construct a cartesian tree out of them, or detect that it is not possible.
Input
Output
The input ensure these is only one possible tree.
Sample Input
7 5 4 2 2 3 9 0 5 1 3 6 6 4 11
Sample Output
YES 2 3 6 0 5 1 1 0 7 5 0 0 2 4 0 1 0 0 3 0 0
Source
- #include <iostream>
- #include<cstdio>
- #include<cstring>
- #include<algorithm>
- using namespace std;
- const int N = 50005;
- struct node
- {
- int key,val;
- int l,r,pa,id;
- }lcm[N];
- int pp[N],ll[N],rr[N];
- int n;
- int stack[N];
- int cmp(struct node a,struct node b)
- {
- return a.key < b.key;
- }
- int cmp2(struct node a,struct node b)
- {
- return a.id < b.id;
- }
- void build()
- {
- int i,j,top;
- top = -1;
- for(i = 1;i <= n;i ++)
- {
- j = top;
- while(j >= 0 && lcm[stack[j]].val > lcm[i].val)
- {
- j --;
- }
- if(j != -1)
- {
- pp[lcm[i].id] = lcm[stack[j]].id;
- rr[lcm[stack[j]].id] = lcm[i].id;
- }
- if(j < top)
- {
- pp[lcm[stack[j + 1]].id] = lcm[i].id;
- ll[lcm[i].id] = lcm[stack[j + 1]].id;
- }
- stack[++ j] = i;
- top = j;
- }
- }
- int main()
- {
- int i;
- while(scanf("%d",&n) != EOF)
- {
- for(i = 1;i <= n;i ++)
- {
- scanf("%d%d",&lcm[i].key,&lcm[i].val);
- lcm[i].l = lcm[i].r = lcm[i].pa = 0;
- lcm[i].id = i;
- }
- lcm[0].id = 0;
- sort(lcm + 1,lcm + 1 + n,cmp);
- memset(pp,0,sizeof(pp));
- memset(ll,0,sizeof(ll));
- memset(rr,0,sizeof(rr));
- build();
- printf("YES\n");
- for(i = 1;i <= n;i ++)
- printf("%d %d %d\n",pp[i],ll[i],rr[i]);
- }
- return 0;
- }
- //2124K 1016MS
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 12205 | Accepted: 3957 |
Description
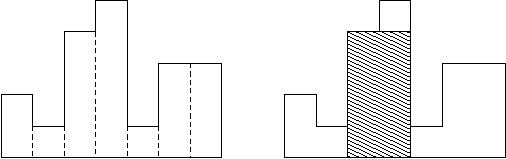
Usually, histograms are used to represent discrete distributions, e.g., the frequencies of characters in texts. Note that the order of the rectangles, i.e., their heights, is important. Calculate the area of the largest rectangle in a histogram that is aligned at the common base line, too. The figure on the right shows the largest aligned rectangle for the depicted histogram.
Input
Output
Sample Input
7 2 1 4 5 1 3 3 4 1000 1000 1000 1000 0
Sample Output
8 4000
Hint
Source
- #include <iostream>
- #include<cstdio>
- #include<cstring>
- using namespace std;
- const int N = 100005;
- typedef __int64 ll;
- ll ans;
- struct node
- {
- ll val;
- int l,r,pa;
- }lcm[N];
- int n;
- int stack[N];
- int nextint()
- {
- char c;
- int ret;
- while(isspace(c = getchar()))
- ;
- ret = c - '0';
- while((c = getchar()) >= '0' && c <= '9')
- ret = ret * 10 + c - '0';
- return ret;
- }
- int build()
- {
- int i,j,top;
- top = -1;
- for(i = 1;i <= n;i ++)
- {
- j = top;
- while(j >= 0 && lcm[stack[j]].val > lcm[i].val)
- j --;
- if(j != -1)
- {
- lcm[i].pa = stack[j];
- lcm[stack[j]].r = i;
- }
- if(j < top)
- {
- lcm[stack[j + 1]].pa = i;
- lcm[i].l = stack[j + 1];
- }
- stack[++ j] = i;
- top = j;
- }
- return stack[0];
- }
- int dfs(int cur)
- {
- if(cur == -1)
- return 0;
- int num = dfs(lcm[cur].l) + dfs(lcm[cur].r) + 1;
- //printf("%I64d:%d\n",lcm[cur].val,num);
- ll tmp = num * lcm[cur].val;
- if(tmp > ans)
- ans = tmp;
- return num;
- }
- void print(int cur)
- {
- if(cur == -1)
- return;
- printf("%d\n",lcm[cur].val);
- print(lcm[cur].l);
- print(lcm[cur].r);
- }
- int main()
- {
- int i;
- while(n = nextint(),n)
- {
- for(i = 1;i <= n;i ++)
- {
- lcm[i].val = (ll)nextint();
- lcm[i].l = lcm[i].r = lcm[i].pa = -1;
- }
- int root = build();
- //print(root);
- ans = 0;
- dfs(root);
- printf("%I64d\n",ans);
- }
- return 0;
- }
- //poj:6216K 47MS
- //zoj:70ms 2532k
- //hdu:31MS 3548K















 4469
4469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









