







LBS定位技术从方法上可分成三类:基于三角关系的定位技术、基于场景分析的定位技术、基于临近关系的定位技术(唐毅和杨博雄,2003)。
一、基于三角关系的定位方法
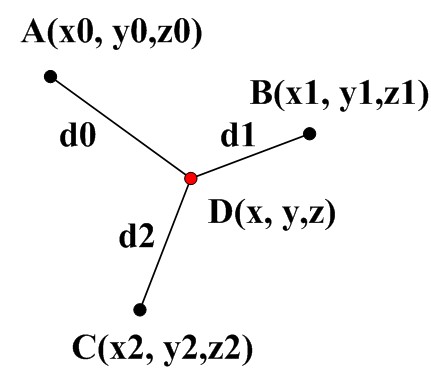
该技术的基本原理很简单,可以抽象成如下问题:已知A、B、C三个点的坐标,以及该三点至D点的距离(分别是d0,d1,d2),求D点的坐标。可以列出以下公式(式1),三个方程三个未知数,能求出唯一解。这种定位技术根据测量得出的数据,利用几何三角关系计算被测物体的位置,它是最主要的,也是应有最广的一种定位技术。

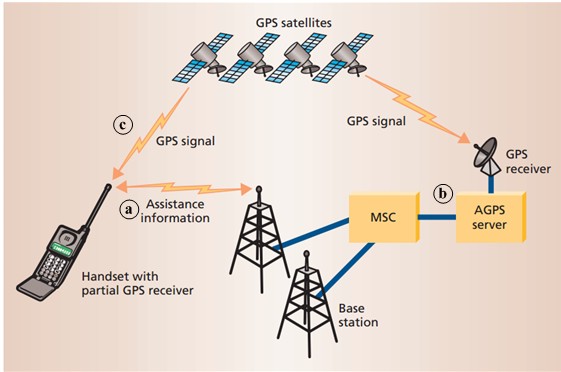
二、GPS

(1)为什么至少使用4颗卫星?
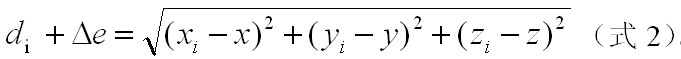
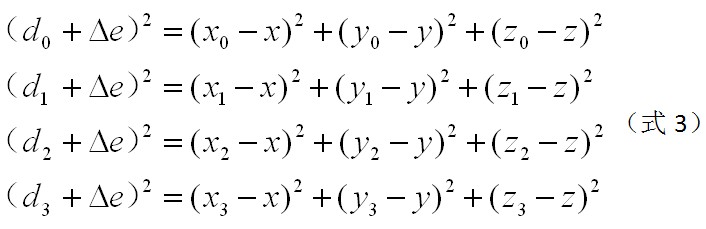
(2)当卫星数目大于4个的时候怎么办?
在野外开阔地区,可接收的卫星数目一般大于4颗,这时可以采用两种方法提高精度:1)挑选信号较强,并且并能保持良好定位解算精度的几何图形的4颗卫星数据进行计算,采用式3解方程即可算出结果;2)所有卫星数据都参与计算,使用最小二乘法进行求解。由于第二种方法能显著减小系统误差,因此被广泛使用。
一般的接收机在计算位置坐标时采用的是牛顿迭代法来求解非线性方程组,该法在计算时需要首先提供个初始坐标,然后在此基础上反复迭代计算,直到满足规定的限差为止。
(3)为什么GPS第一次定位慢?
前面讲过,GPS接收机计算时一般使用的是牛顿迭代法,该法需要给定初始位置,初始位置越精确,迭代收敛越快!由于是第一次启动,初始位置是上一次开机时保存的最后一次定位的坐标,往往与现在所处的真实位置偏差较大,由此使得计算的迭代次数显著增多,计算较慢。
当连续使用GPS时可以发现定位速度明显变快,因为此时初始位置与实际位置较为接近(初始位置为上次定位的位置),计算能很快收敛,一般只需迭代两三次。
(4)如何提高GPS定位速度?
一、问题
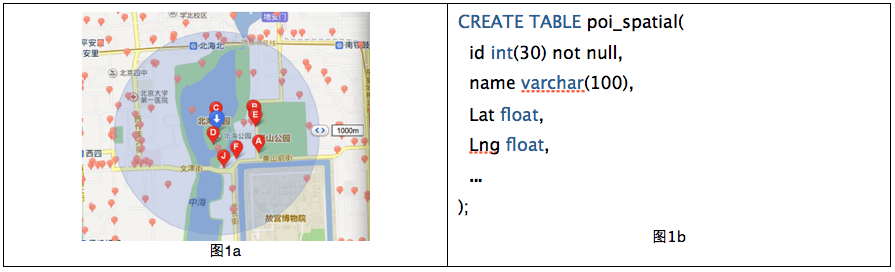
先思考个常见的问题:如何根据自己所在位置查询来查询附近50米的POI(point of interest,比如商家、景点等)呢(图1a)?
每个POI都有经纬度信息,我用图1b的SQL语句在mySQL中建立了POI_spatial的表,其中lat和lng两个字段来代表纬度和经度。为后续分析方便起见,我人造了40万个POI数据。
二、传统的解决思路
方法一:暴力方法
该方法的思路很直接:计算位置与所有POI的距离,并保留距离小于50米的POI。
插句题外话,计算经纬度之间的距离不能像求欧式距离那样平方开根号,因为地球是个不规整的球体(图2a),按最简单的完美球体假设,两点之间的距离函数应该如图2b所示。

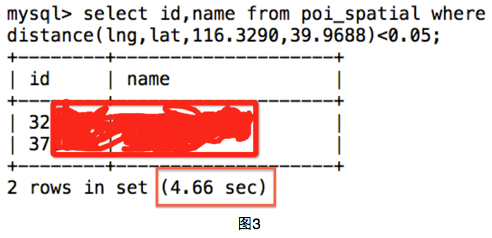
该方法的复杂度为:40万*距离函数。我们将球体距离函数写为mysql存储过程distance,之后我们执行查询操作(图3),发现花费了4.66秒。
该方法耗时的原因显而易见,执行了40万次复杂的距离计算函数。
方法二:矩形过滤方法
该方法分为两部:
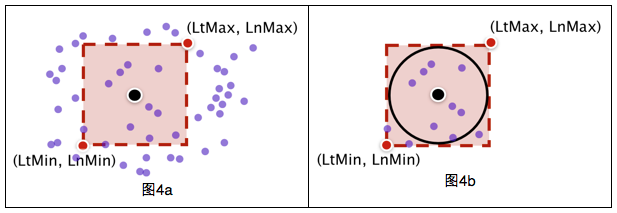
a)先用矩形框过滤(图4a),判断一个点在矩形框内很简单,只要进行两次判断(LtMin<lat<LtMax; LnMin<lng<LnMax),落在矩形框内的POI个数为n(n<<40万);
b)用球面距离公式计算位置与矩形框内n个POI的距离(图4b),并保留距离小于50米的POI
矩形过滤方法的复杂度为:40万*矩形过滤函数 + n*距离函数(n<<40万)。
根据这个思路我们执行SQl查询(图5)(注: 经度或纬度每隔0.001度,距离相差约100米,由此推算出矩形左下角和右上角坐标),发现过滤后正好剩下两个POI。
此查询花费了0.36秒,相比于方法一查询时间大大降低,但是对于一次查询来说还是很长。时间长的原因在于遍历了40万次。

方法三:B树对经度或纬度建立索引
方法二耗时的原因在于执行了遍历操作,为了不进行遍历,我们自然想到了索引。我们对纬度进行了B树索引。

此方法包括三个步骤:
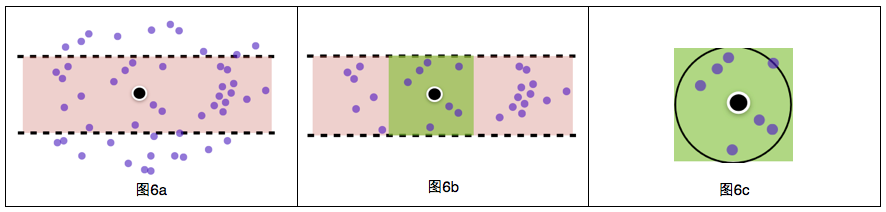
a)通过B树快速找到某纬度范围的POI(图6a),个数为m(m<40万),复杂度为Log(40万)*过滤函数;
b)在步骤a过滤得到的m个POI中查找某经度范围的POI(图6b),个数为n(n<m),复杂度为m*过滤函数;
c) 用球面距离公式计算位置与步骤b得到的n个POI的距离(图6c),并保留距离小于50米的POI
执行SQL查询(图7),发现时间已经大大降低,从方法2的0.36秒下降到0.01秒。

三、B树能索引空间数据吗?
这时候有人会说了:“方法三效果如此好,能够满足我们附近POI查询问题啊,看来B树用来索引空间数据也是可以的嘛!”
那么B树真的能够索引空间数据吗?
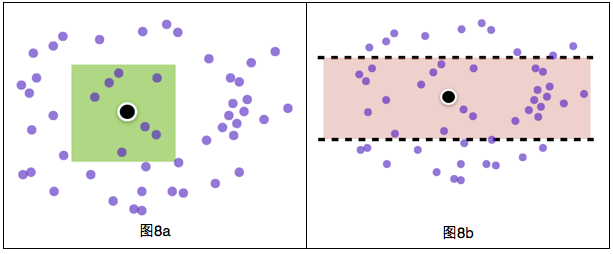
1)只能对经度或纬度索引(一维索引),与期望的不符
我们期待的是快速找出落在某一空间范围的POI(如矩形)(图8a),而不是快速找出落在某纬度或经度范围的POI(图8b),想象一下,我要查询北京某区的POI,但是B树索引不仅给我找出了北京的,还有与北京同一维度的天津、大同、甚至国外城市的POI,当数据量很大时,效率很低。
2)当数据是多维,比如三维(x,y,z),B树怎么索引?
比如z可能是高程值,也可能是时间。有人会说B树其实可以对多个字段进行索引,但这时需要指定优先级,形成一个组合字段,而空间数据在各个维度方向上不存在优先级,我们不能说纬度比经度更重要,也不能说纬度比高程更重要。
3)当空间数据不是点,而是线(道路、地铁、河流等),面(行政区边界、建筑物等),B树怎么索引?
对于面来说,它由一系列首尾相连的经纬度坐标点组成,一个面可能有成百上千个坐标,这时数据库怎么存储,B树怎么索引,这些都是问题。
既然传统的索引不能很好的索引空间数据,我们自然需要一种方法能对空间数据进行索引,即空间索引。
下节将对空间索引分类体系、原理、优缺点及数据库支持情况进行阐述。
第一篇讲到了传统的索引如B树不能很好的支持空间数据,比如点(POI等)、线(道路、河流等)、面(行政边界、住宅区等)。本篇将对空间索引进行简单分类,然后介绍网格索引。(深入浅出空间索引1:http://blog.csdn.net/zhanlijun/article/details/13171539)
一、空间索引有哪几种?
传统索引使用哈希和树这两类最基本的数据结构。空间索引虽然更为复杂,但仍然发展于这两种数据结构。因此可以将空间索引划分为两大类:1)基于哈希思想,如网格索引等;2)基于树思想,有四叉树、R树等。

二、网格索引
哈希是通过一个哈希函数将关键字映射到内存或外存的数据结构,如何扩展到空间数据呢?
2.1. 网格索引原理
扩展方法:对地理空间进行网格划分,划分成大小相同的网格,每个网格对应着一块存储空间,索引项登记上落入该网格的空间对象。
举个例子,我们将地理空间进行网格划分,并进行编号。该空间范围内有三个空间对象,分别是id=5的街道,23的河流和11的商圈。这时候我们可以按照哈希的数据结构存储,每个网格对应着一个存储桶,而桶里放着空间对象,比如对2号网格,里面存储着id=5的空间对象,对35号网格,桶里放着id=5和id=23的空间对象。

假如我们要查询某一空间范围内有哪些空间对象,比如下面的红框就表示空间范围,我们可以很快根据红框的空间范围算出它与35号和36号网格相交,然后分别到35号和36号网格中查找空间对象,最终找出id=5和id=23的空间对象。

2.2. 网格索引缺点
1)索引数据冗余
网格与对象之间多对多关系在空间对象数量多、大小不均时造成索引数据冗余。比如11号商圈这个空间对象在68,69,100,101这4个网格都有存储,浪费了大量空间。
2)网格的大小难以确定
网格的划分大小难以确定。网格划分得越密,需要的存储空间越多,网格划分的越粗,查找效率可能会降低。对于图a,这个查询需要查询4个网格,由于4个网格覆盖了整个空间,因此这个查找其实是将空间范围内所有的点数据都遍历一遍,失去了索引的意义。

3)很多网格没有数据
空间数据具有明显的聚集性,比如POI只在几个热点商贸区聚集,在郊区等地方很稀疏,这将导致很多网格内没有任何空间数据。

下一节将介绍四叉树。















 4153
4153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









