









一、SOCK_RAW 内幕
首先在讲SOCK_RAW 之前,先来看创建socket 的函数:
int socket(int domain, int type, int protocol);
domain :指定通信协议族(protocol family/address)
/usr/include/i386-linux-gnu/bits/socket.h
|
1
2 3 4 5 6 7 8 9 10 11 12 13 |
/* Supported address families. */
#define AF_UNSPEC 0 #define AF_UNIX 1 /* Unix domain sockets */ #define AF_LOCAL 1 /* POSIX name for AF_UNIX */ #define AF_INET 2 /* Internet IP Protocol */
#define
PF_PACKET
17
/* Packet family. */
/* ... */ /* Protocol families, same as address families. */ #define PF_UNSPEC AF_UNSPEC #define PF_UNIX AF_UNIX #define PF_LOCAL AF_LOCAL #define PF_INET AF_INET
#define AF_PACKET PF_PACKET
/* ... */ |
type:指定socket类型(type)
|
1
2 3 4 5 6 7 8 9 10 |
enum sock_type
{ SOCK_STREAM = 1, SOCK_DGRAM = 2, SOCK_RAW = 3, SOCK_RDM = 4, SOCK_SEQPACKET = 5, SOCK_DCCP = 6, SOCK_PACKET = 10, }; |
protocol :协议类型(protocol)
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
/* Standard well-defined IP protocols. */
enum { IPPROTO_IP = 0, /* Dummy protocol for TCP */ IPPROTO_ICMP = 1, /* Internet Control Message Protocol */ IPPROTO_IGMP = 2, /* Internet Group Management Protocol */ IPPROTO_IPIP = 4, /* IPIP tunnels (older KA9Q tunnels use 94) */ IPPROTO_TCP = 6, /* Transmission Control Protocol */ IPPROTO_EGP = 8, /* Exterior Gateway Protocol */ IPPROTO_PUP = 12, /* PUP protocol */ IPPROTO_UDP = 17, /* User Datagram Protocol */ IPPROTO_IDP = 22, /* XNS IDP protocol */ IPPROTO_DCCP = 33, /* Datagram Congestion Control Protocol */ IPPROTO_RSVP = 46, /* RSVP protocol */ IPPROTO_GRE = 47, /* Cisco GRE tunnels (rfc 1701,1702) */ IPPROTO_IPV6 = 41, /* IPv6-in-IPv4 tunnelling */ IPPROTO_ESP = 50, /* Encapsulation Security Payload protocol */ IPPROTO_AH = 51, /* Authentication Header protocol */ IPPROTO_BEETPH = 94, /* IP option pseudo header for BEET */ IPPROTO_PIM = 103, /* Protocol Independent Multicast */ IPPROTO_COMP = 108, /* Compression Header protocol */ IPPROTO_SCTP = 132, /* Stream Control Transport Protocol */ IPPROTO_UDPLITE = 136, /* UDP-Lite (RFC 3828) */ IPPROTO_RAW = 255, /* Raw IP packets */ IPPROTO_MAX }; |
你是否曾经有过这样的疑惑,当我们在Linux下这样调用 socket(AF_INET, SOCK_STREAM, 0); 时,第三个参数为0,内核是如何找到合适的协议如IPPROTO_TCP 的?实际上是调用 pffindtype 函数实现的。下面来看看FreeBSD的源码,linux 的实现差不多,有个小区别等会指出。
在freeBSD 上创建一个socket 会调用socreate() 函数:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
/* * socreate returns a socket with a ref count of 1. The socket should be * closed with soclose(). */ int socreate( int dom, struct socket **aso, int type, int proto, struct ucred *cred, struct thread *td) { struct protosw *prp; struct socket *so; int error; if (proto) prp = pffindproto(dom, proto, type); else prp = pffindtype(dom, type); /* .... */ } |
从函数可以看出当proto 为0 则调用pffindtype() 函数,否则调用pffindproto() 函数,两个函数如下:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
struct protosw *
pffindtype( int family, int type) { struct domain *dp; struct protosw *pr; for (dp = domains; dp; dp = dp->dom_next) if (dp->dom_family == family) goto found; return ( 0); found: for (pr = dp->dom_protosw; pr < dp->dom_protoswNPROTOSW; pr++) if (pr->pr_type && pr->pr_type == type) return (pr); return ( 0); } struct protosw * pffindproto( int family, int protocol, int type) { struct domain *dp; struct protosw *pr; struct protosw *maybe = 0; if (family == 0) return ( 0); for (dp = domains; dp; dp = dp->dom_next) if (dp->dom_family == family) goto found; return ( 0); found: for (pr = dp->dom_protosw; pr < dp->dom_protoswNPROTOSW; pr++) { if ((pr->pr_protocol == protocol) && (pr->pr_type == type)) return (pr); if (type == SOCK_RAW && pr->pr_type == SOCK_RAW && pr->pr_protocol == 0 && maybe == ( struct protosw *) 0) maybe = pr; } return (maybe); } |
不要被它吓到了,其实不难理解,但理解之前需要知道的是struct protosw 是个结构体,里面有.pr_type(SOCK_XXX) 和.pr_protocol( IPPROTO_XXX )等成员,所有的struct protosw 结构体存储于一个 inetsw[] 数组中,此外有一个全局的domain 链表,其中一个节点inetdomain 的成员指针指向了inetsw[] 数组,大致图形如下(不是很准确):
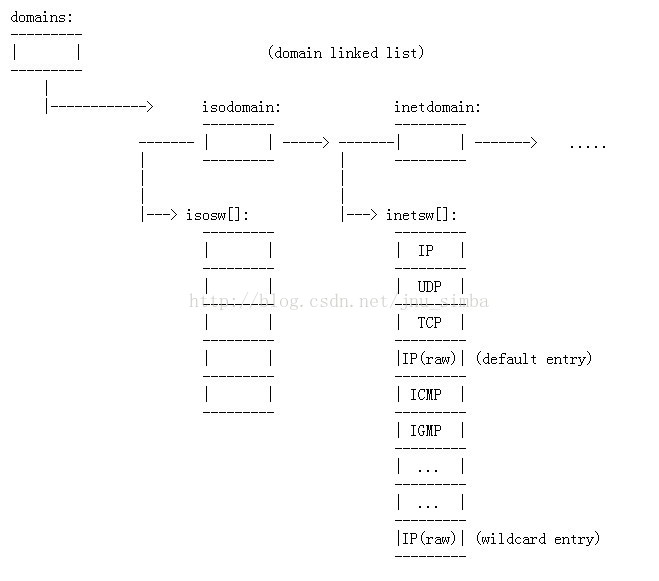
注意最后一个wildcare entry,它的.pr_protocol 没有赋值故为0,如下
|
1
2 3 4 5 6 7 8 9 10 11 |
/* raw wildcard */
{ .pr_type = SOCK_RAW,
.pr_domain = &inetdomain,
.pr_flags = PR_ATOMIC | PR_ADDR, .pr_input = rip_input, .pr_ctloutput = rip_ctloutput, .pr_init = rip_init, .pr_usrreqs = &rip_usrreqs }, }; /* end of inetsw[] */ |
回过头来看pffindtype 和 pffindproto:
pffindtype: 1. 通过"family" 参数找到对应的domain 节点
2. 返回inetsw [] 数组中匹配“type" 参数的第一个struct protosw 结构体指针
pffindproto: 1. 通过"family" 参数找到对应的domain 节点
2. 返回inetsw [] 数组中匹配“type" --”protocol“ 参数对的第一个struct protosw 结构体指针
3. 如果参数对不匹配而且”type" 为 SOCK_RAW,则返回wildcard entry 指针
假设现在这样调用 socket(AF_INET, SOCK_RAW, 30); 则使用pffindproto() 函数查找,但因为协议值30未在内核中定义,故返回wildcard_RAW entry。同理,你可能看见过别人这样写:socket(AF_INET, SOCK_RAW, IPPROTO_TCP); 实际上在FreeBSD 下 用pffindproto 找,SOCK_RAW 与 IPPROTO_TCP 也是不匹配的,返回wildcard_RAW entry 。
再者,在FreeBSD 上这样调用 socket(AF_INET, SOCK_RAW, 0/* IPPRORO_IP*/); 是可以的,使用pffindtype() 函数查找,返回的第一个是default entry;但在linux 上这样调用会出错,errno = EPROTONOSUPPORT,这就是前面提到的两个系统中不同点。为什么会出错,看linux 源码:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
/* Upon startup we insert all the elements in inetsw_array[] into * the linked list inetsw. */ static struct inet_protosw inetsw_array[] = { { .type = SOCK_STREAM, .protocol = IPPROTO_TCP, .prot = &tcp_prot, .ops = &inet_stream_ops, .capability = - 1, .no_check = 0, .flags = INET_PROTOSW_PERMANENT | INET_PROTOSW_ICSK, }, { .type = SOCK_DGRAM, .protocol = IPPROTO_UDP, .prot = &udp_prot, .ops = &inet_dgram_ops, .capability = - 1, .no_check = UDP_CSUM_DEFAULT, .flags = INET_PROTOSW_PERMANENT, }, { .type = SOCK_RAW, .protocol = IPPROTO_IP, /* wild card */ .prot = &raw_prot, .ops = &inet_sockraw_ops, .capability = CAP_NET_RAW, .no_check = UDP_CSUM_DEFAULT, .flags = INET_PROTOSW_REUSE, } }; |
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
static
int inet_create(
struct net *net,
struct socket *sock,
int protocol)
{ /* ... */ /* Look for the requested type/protocol pair. */ answer = NULL; lookup_protocol: err = -ESOCKTNOSUPPORT; rcu_read_lock(); list_for_each_rcu(p, &inetsw[sock->type]) { answer = list_entry(p, struct inet_protosw, list); /* Check the non-wild match. */ if (protocol == answer->protocol) { if (protocol != IPPROTO_IP) break; } else { /* Check for the two wild cases. */ if (IPPROTO_IP == protocol) { protocol = answer->protocol; break; } if (IPPROTO_IP == answer->protocol) break; } err = -EPROTONOSUPPORT; answer = NULL; } /* ... */ } |
在这里提醒一下IPPROTO_IP = 0, 在inet_create()函数中,我们根据type的值,在全局数组struct inet_protosw inetsw[]里找到我们对应的协议转换开关。下面通过来分析几个调用来走一下上面的inet_create 函数(linux 下):
1) socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
protocol = 6
*answer = inetsw_array[0]
protocol == answer->protocol && protocol != IPPROTO_IP : TRUE
OK
2) socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP);
protocol = 17
*answer = inetsw_array[1]
protocol == answer->protocol && protocol != IPPROTO_IP : TRUE
OK
3) socket(AF_INET, SOCK_STREAM, 0);
protocol = 0
*answer = inetsw_array[0]
if (protocol == answer->protocol) : FALSE
check else :
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
: TRUE
note that protocol value 0 is substituted with the real value of IPPROTO_TCP in line:
protocol = answer->protocol;
OK
/* 上面例子(3)解释了文章最开始提出的疑问,现在protocol 已经被替换成了6 */
4) socket(AF_INET, SOCK_DGRAM, 0);
protocol = 0
*answer = inetsw_array[1]
if (protocol == answer->protocol) : FALSE
check else :
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
: TRUE
note that protocol value 0 is substituted with the real value of IPPROTO_UDP in line:
protocol = answer->protocol;
OK
5) socket(AF_INET, SOCK_RAW, 0);
protocol = 0
*answer = inetsw_array[2]
protocol == answer->protocol && protocol == IPPROTO_IP so : if (protocol != IPPROTO_IP) is FALSE
not OK -> EPROTONOSUPPORT
6) socket(AF_INET, SOCK_STREAM, 9); (where 9 can be any protocol except IPPROTO_TCP)
protocol = 9
*answer = inetsw_array[0]
if (protocol == answer->protocol) : FALSE
check else :
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
both are a FALSE
not OK -> EPROTONOSUPPORT
7) socket(AF_INET, SOCK_DGRAM, 9); (where 9 can be any protocol except IPPROTO_UDP)
same as above
not OK -> EPROTONOSUPPORT
8) socket(AF_INET, SOCK_RAW, 9); (where 9 can be *any* protocol except 0)
protocol = 9
*answer = inetsw_array[2]
if (protocol == answer->protocol) : FALSE
check else :
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
: FALSE
if (IPPROTO_IP == answer->protocol)
break;
: TRUE
OK
那raw socket 接收缓冲区的数据是什么呢?看下面这个图:
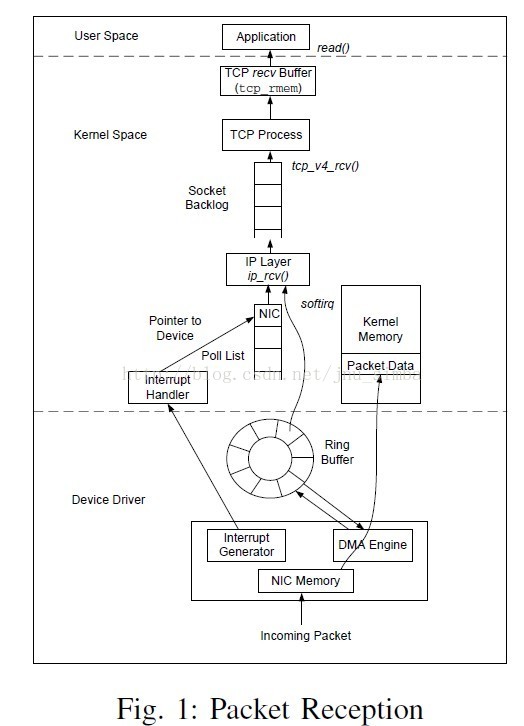
真正从网卡进来的数据是完整的以太网帧,底层用sk_buff 数据结构描述,最终进入接收缓冲区recv buffer,而我们应用层调用read / recv /recvfrom 从接收缓冲区拷贝数据到应用层提供的buffer,对一般的套接字,如SOCK_STREAM, SOCK_DGRAM 来说,此时缓冲区只有user data,其他各层的头部已经被去除,而对于SOCK_RAW 来说是IP head + IP payload,当然也可以是arp/rarp 包,甚至是完整的帧(加上MAC头)。
假设现在我们要通过SOCK_RAW 发送数据,则需要调用setsockopt 设置IP_HDRINCL 选项(如果protocol 设为IPPROTO_RAW 则默认设置了IP_HDRINCL),即告诉内核我们自己来封装IP头部,其实头部中某些元素是可以偷懒让内核填充的:

需要注意的是,如果我们自己来封装IP头部,那么数据包传递出去的时候IP 层就不会参与运作,即如果数据包大于接口的MTU,那么不会进行分片而直接丢弃。
二、SOCK_RAW 应用
1、packet sniffer
|
1
2 3 4 5 6 7 |
sock_raw = socket(AF_INET , SOCK_RAW , IPPROTO_TCP);
while( 1) { data_size = recvfrom(sock_raw , buffer , 65535 , 0 , &saddr , &saddr_size); //Now process the packet ProcessPacket(buffer , data_size); } |
上述程序只可以接收tcp 包,当然udp 和 icmp 可以这样写:
|
1
2 |
sock_raw = socket(AF_INET , SOCK_RAW , IPPROTO_UDP);
sock_raw = socket(AF_INET , SOCK_RAW , IPPROTO_ICMP); |
但是不能以为 sock_raw = socket(AF_INET , SOCK_RAW , IPPROTO_IP); 就能接收所有种类的IP包,如前所述,这是错误的。
上述程序只能监测到输入的数据包,而且读取的数据包中已经没有了以太网头部。
只需要稍稍改进一下:
|
1
|
sock_raw = socket( AF_PACKET , SOCK_RAW , htons(ETH_P_ALL)) ;
|
ETH_P_IP 0X0800只接收发往目的MAC是本机的IP类型的数据帧
ETH_P_ARP 0X0806只接收发往目的MAC是本机的ARP类型的数据帧
ETH_P_RARP 0X8035只接受发往目的MAC是本机的RARP类型的数据帧
ETH_P_ALL 0X0003接收发往目的MAC是本机的所有类型(ip,arp,rarp)的数据帧,同时还可以接收从本机发出去的所有数据帧。在混杂模式打开的情况下,还会接收到发往目的MAC为非本地硬件地址的数据帧。
注意family 是AF_PACKET,这样就能监测所有输入和输出的数据包,而且不仅限于IP包(tcp/udp/icmp),如arp/rarp 包也可以监测,并且数据包还包含以太网头部。最后提一点,packet sniffer 也可以使用libpcap 库实现,著名的tcpdump 就使用了此库。
2、Tcp syn port scan
TCP 三次握手就不说了,端口扫描过程如下:
1. Send a Syn packet to a port A
2. Wait for a reply of Syn+Ack till timeout.
3. Syn+Ack reply means the port is open , Rst packet means port is closed , and otherwise it might be inaccessible or in a filtered state.
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
//Create a raw socket int s = socket (AF_INET, SOCK_RAW , IPPROTO_TCP); if (setsockopt (s, IPPROTO_IP, IP_HDRINCL, val, sizeof (one)) < 0) { printf ( "Error setting IP_HDRINCL. Error number : %d . Error message : %s \n" , errno , strerror(errno)); exit( 0); } for(port = 1 ; port < 100 ; port++) { //Send the packet if ( sendto (s, datagram , sizeof( struct iphdr) + sizeof( struct tcphdr) , 0 , ( struct sockaddr *) &dest, sizeof (dest)) < 0) { printf ( "Error sending syn packet. Error number : %d . Error message : %s \n" , errno , strerror(errno)); exit( 0); } } |
创建一个原始套接字s,开启IP_HDRINCL 选项(这两步可以直接用 int s = socket (AF_INET, SOCK_RAW, IPPROTO_RAW); ),自己封装IP 头部和tcp 头部,主要是标志位syn 置为1,然后循环端口进行发送数据包。另开一个线程创建另一个原始套接字,仿照packet sniffer 进行数据包的接收,分解tcp 头部看是否syn == 1 && ack == 1 && dest_addr == src_addr,如果是则表明端口是打开的。如果不追求效率,很简单的做法是直接用普通的套接字,循环端口去connect,成功就表明端口是打开的,只是三次握手完整了一回。
3、SYN Flood DOS Attack
仿照上面端口扫描程序,自己封装头部,主要是syn 置为1,然后在一个死循环中死命地对某个地址发送数据包。不过现在的网站一般有防火墙,我们这种小儿科程序对他们来说,跟玩一样。
4、ICMP ping flood
实际上跟SYN flood 类似的道理,不过发送的是icmp 包,即自己封装icmp 头部
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
//Raw socket - if you use IPPROTO_ICMP, then kernel will fill in the correct ICMP header checksum, if IPPROTO_RAW, then it won't int sockfd = socket (AF_INET, SOCK_RAW, IPPROTO_RAW); if (sockfd < 0) { perror( "could not create socket"); return ( 0); } int on = 1; // We shall provide IP headers if (setsockopt (sockfd, IPPROTO_IP, IP_HDRINCL, ( const char *)&on, sizeof (on)) == - 1) { perror( "setsockopt"); return ( 0); } //allow socket to send datagrams to broadcast addresses if (setsockopt (sockfd, SOL_SOCKET, SO_BROADCAST, ( const char *)&on, sizeof (on)) == - 1) { perror( "setsockopt"); return ( 0); } while ( 1) { if ( (sent_size = sendto(sockfd, packet, packet_size, 0, ( struct sockaddr *) &servaddr, sizeof (servaddr))) < 1) { perror( "send failed\n"); break; } usleep( 10000); //microseconds } |
附录:
1、相关头文件
#include<netinet/ip_icmp.h> //Provides declarations for icmp header
#include<netinet/udp.h> //Provides declarations for udp header
#include<netinet/tcp.h> //Provides declarations for tcp header
#include<netinet/ip.h> //Provides declarations for ip header
#include<netinet/if_ether.h> //For ETH_P_ALL
#include<net/ethernet.h> //For ether_header
2、计算校验和的函数
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
/* Function calculate checksum */ unsigned short in_cksum( unsigned short *ptr, int nbytes) { register long sum; u_short oddbyte; register u_short answer; sum = 0; while (nbytes > 1) { sum += *ptr++; nbytes -= 2; } if (nbytes == 1) { oddbyte = 0; *((u_char *) & oddbyte) = *(u_char *) ptr; sum += oddbyte; } sum = (sum >> 16) + (sum & 0xffff); sum += (sum >> 16); answer = ~sum; return (answer); } |
注意,IP头部中的校验和只校验ip头部的大小,而tcp 头部的校验和需要校验tcp头部和数据,按照封包原则,封装到TCP层的时候,ip信息还没有封装上去,但是校验值却需要马上进行计算,所以必须手工构造一个伪头部来表示ip层的信息,可以使用下面的结构体:
|
1
2 3 4 5 6 7 8 9 10 11 |
struct pseudo_header
//needed for checksum calculation { unsigned int source_address; unsigned int dest_address; unsigned char placeholder; // 0 unsigned char protocol; unsigned short tcp_length; struct tcphdr tcp; //tcp head }; |
将pseduo_header 和 use_data 都拷贝到同个缓冲区,传递给in_cksum 的ptr 为缓冲区起始地址,bytes 为总共的大小。
参考:http://www.binarytides.com/
TCP Implementation in Linux: A Brief Tutorial.pdf
《UNP》
《TCP/IP 协议详解 卷一》















 3442
3442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









