







本文属于学习笔记,依据(微信公众号:jack床长)的文章整理,在jack床长文章的启发下,里面也加入了自己的一些思考,非常感谢jack床长的无私分享。越分享才会越快乐、越无私才会越快乐,我也希望我的博客能够启发帮助到更多的人。
jack床长博客链接:http://blog.csdn.net/jiangjunshow
来判断自己的预测结果是否准确,这一步是至关重要的,因为只有知道自己预测结果是否准确,才能够对自身进行调整,好让结果越来越准确,这就是学习的过程。
我们人类学习也应该遵循这个道理,如果一个人一直不停的学,但是不验证自己的学习成果,那么有可能学的方向或学习方法都是错的,不停地学但是结果却都白学了。

jack床长的配图很不错。我相信很多经历过学生时代的人,都会有上图这位同学的困惑,“我有时候已经很努力了,为什么还是考不好?”。前段时间,一位家长给我讲了这样的一句话。他说,一个人能不能干成一件事情,在于他的努力程度和他纠正错误的习惯,重点、重点、重点,“纠正错误的习惯”。家长水平相当了得,这句话讲的是相当相当精辟 [点赞]
我们的神经网络正是因为在不断纠正自己的错误,所以它才变的越来越强大,例如阿尔法狗

哈哈~,很有意思吧,咱们接着来介绍神经网络是如何判断预测结果是否准确的,本篇文章介绍的损失函数(loss function)就是干这事的。
ŷ是预测的结果。上面的i角标指代某一个训练样本(本系列教程都会这样来指代某一个训练样本),例如,ŷ(i) 是对于训练样本x(i)的预测结果。
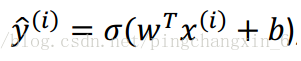
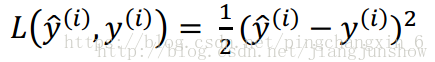
损失函数运算后得出的结果越大,那么预测就与实际结果的偏差越大,即预测精度越不高。理论上你可以用上面的公式作为损失函数——预测结果ŷ与实际结果y的平方差再乘以二分之一。但是在实践中人们通常不会用它,具体为什么,后面的文章再给大家讲解,现在讲了你们也理解不了。 实践中我们使用的损失函数的公式如下。
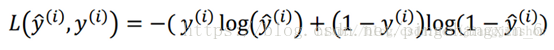
前面的平方差公式比较直接,就是ŷ越接近y,那么运算得出的结果就越小,那么就说明预测越准确,即损失越小。努力使损失函数的值越小就是努力让预测的结果越准确。其实这个新的损失函数的作用是一样的。具体数学上面的细节我就不讲解了,因为文章的目的是让大家明白人工智能的原理,学会如何实现人工智能。实现一个原理的具体数学公式是很多的,就像做菜,你明白了它的基本原理后,你可以用各种手段把菜做出来,你可以按照网上的教程做,你也可以自己创造新的做法。
上面对单个训练样本我们定义了损失函数。
下面的公式用于衡量预测算法对整个训练集的预测精度。其实就是对每个样本的“损失”进行累加,然后求平均值。这种针对于整个训练集的损失函数我们称它为成本函数(cost function)。它的计算结果越大,说明成本越大,即预测越不准确。
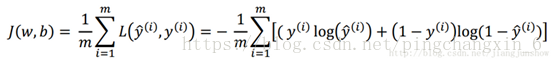
总的来说,神经网络是通过一个损失函数来求出预测结果和真实值之间的误差,来判断预测结果是否正确。误差越大说明预测结果越不准确。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









