 Spark SQL与Hive对比
Spark SQL与Hive对比





 本文探讨了Spark SQL与Hive的区别,包括它们在Spark生态系统中的角色、数据处理能力及兼容性。详细介绍了DataFrame、DataSet与RDD之间的差异,并展示了如何在Spark中进行数据的加载与保存。
本文探讨了Spark SQL与Hive的区别,包括它们在Spark生态系统中的角色、数据处理能力及兼容性。详细介绍了DataFrame、DataSet与RDD之间的差异,并展示了如何在Spark中进行数据的加载与保存。
Hive and SparkSQL的区别
Shark 是伯克利实验室 Spark 生态环境的组件之一,是基于 Hive 所开发的工具,它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在 Spark 引擎上
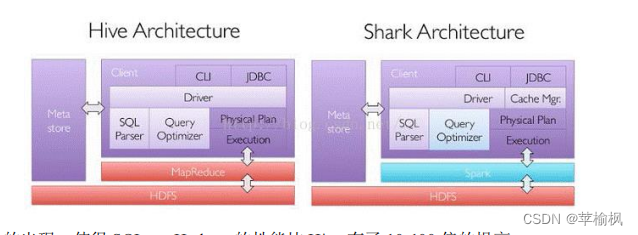
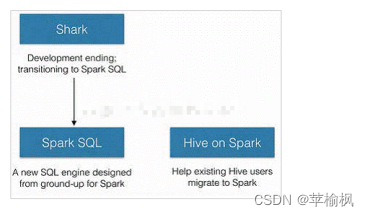
其中 SparkSQL 作为 Spark 生态的一员继续发展,而不再受限于 Hive,只是兼容 Hive;而Hive on Spark 是一个 Hive 的发展计划,该计划将 Spark 作为 Hive 的底层引擎之一,也就是说,Hive 将不再受限于一个引擎,可以采用 Map-Reduce、Tez、Spark 等引擎。
SparkSQL
Spark Core 中的 RDD
➢ DataFrame
➢ DataSet
Spark SQL 所提供的 DataFrame 和 DataSet 模型进行编程.
SparkSession 是 Spark 最新的 SQL 查询起始点,实质上是 SQLContext 和 HiveContext
的组合
RDD、DF、DS
区别
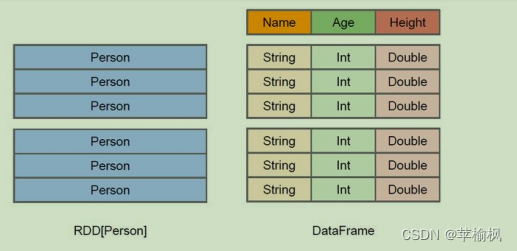
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格。
DataFrame 与 RDD 的主要区别在于,前者带有 schema 元信息,即 DataFrame所表示的二维表数据集的每一列都带有名称和类型。
左侧的 RDD[Person]虽然以 Person 为类型参数,但 Spark 框架本身不了解 Person 类的内部结构。而右侧的 DataFrame 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataSet 是分布式数据集合,是 DataFrame的一个扩展,提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark
SQL 优化执行引擎的优点。
用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到DataSet 中的字段名称;
- DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
- DataFrame 是 DataSet 的特例,DataFrame=DataSet[Row]
三者的共性
- RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数
据提供便利; - 三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到
Action 如 foreach 时,三者才会开始遍历运算; - 三者有许多共同的函数,如 filter,排序等;
- 在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:import spark.implicits._(在
创建好 SparkSession 对象后尽量直接导入) - 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会
内存溢出 - 三者都有 partition 的概念
- DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
三者的区别
- RDD
- RDD 一般和 spark mllib 同时使用
- RDD 不支持 sparksql 操作
- DataFrame
- 与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为 Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值
- DataFrame 与 DataSet 一般不与 spark mllib 同时使用
- DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能注册临时表/视窗,进行 sql 语句操作
- DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表头,这样每一列的字段名一目了然(后面专门讲解)
- DataSet
- Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
- DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共性中的第七条提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息。
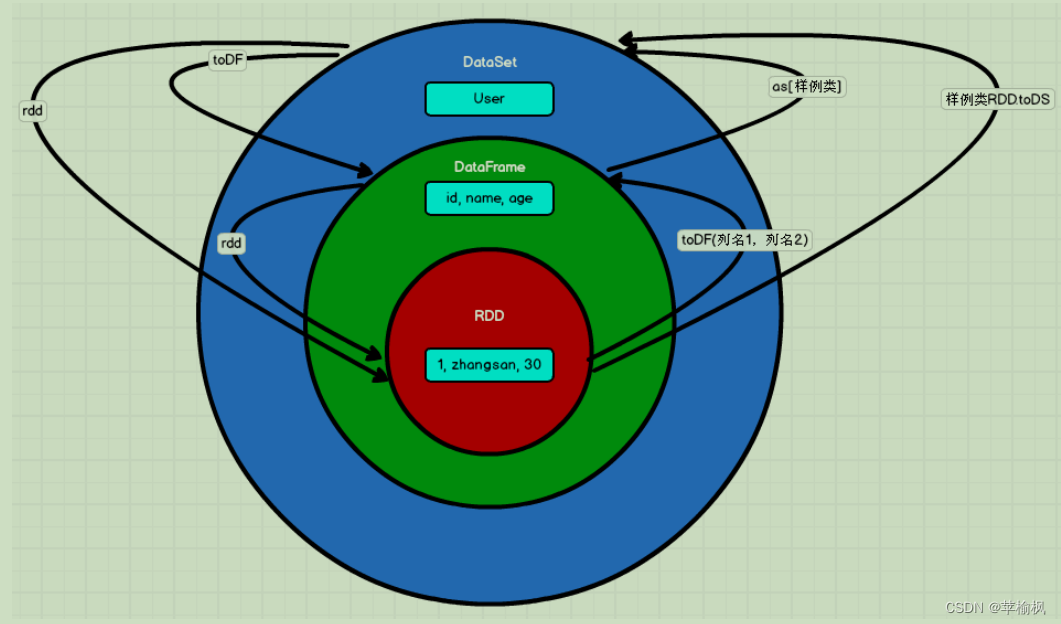
相互转换
RDD 转换为 DataFrame
.toDF
DataFrame 转换为 RDD、DataSet 转换为 RDD
.rdd
RDD 转换为 DataSet
.toDS
DataFrame 和 DataSet 转换
val ds = df.as[User]
val df = ds.toDF
数据的加载和保存
加载数据
spark.read.load
csv format jdbc json load option options orc parquet schema table text textFile
df.write.save
csv jdbc json orc parquet textFile MySQL
mysql
导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
#读取数据
val conf: SparkConf = new
SparkConf().setMaster("local[*]").setAppName("SparkSQL")
//创建 SparkSession 对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
//方式 1:通用的 load 方法读取
spark.read.format("jdbc")
.option("url", "jdbc:mysql://linux1:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123123")
.option("dbtable", "user")
.load().show
//方式 2:通用的 load 方法读取 参数另一种形式
spark.read.format("jdbc")
.options(Map("url"->"jdbc:mysql://linux1:3306/spark-sql?user=root&password=
123123",
"dbtable"->"user","driver"->"com.mysql.jdbc.Driver")).load().show
//方式 3:使用 jdbc 方法读取
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123123")
val df: DataFrame = spark.read.jdbc("jdbc:mysql://linux1:3306/spark-sql",
"user", props)
df.show
//释放资源
spark.stop()
# 写入数据
case class User2(name: String, age: Long)
。。。
val conf: SparkConf = new
SparkConf().setMaster("local[*]").setAppName("SparkSQL")
//创建 SparkSession 对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val rdd: RDD[User2] = spark.sparkContext.makeRDD(List(User2("lisi", 20),
User2("zs", 30)))
val ds: Dataset[User2] = rdd.toDS
//方式 1:通用的方式 format 指定写出类型
ds.write
.format("jdbc")
.option("url", "jdbc:mysql://linux1:3306/spark-sql")
.option("user", "root")
.option("password", "123123")
.option("dbtable", "user")
.mode(SaveMode.Append)
.save()
//方式 2:通过 jdbc 方法
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123123")
ds.write.mode(SaveMode.Append).jdbc("jdbc:mysql://linux1:3306/spark-sql",
"user", props)
//释放资源
spark.stop()
Hive
导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
#此处的 root 改为你们自己的 hadoop 用户名称
System.setProperty("HADOOP_USER_NAME", "root")
# 在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址:
config("spark.sql.warehouse.dir", "hdfs://linux1:8020/user/hive/warehouse")
# 将 hive-site.xml 文件拷贝到项目的 resources 目录中,代码实现
//创建 SparkSession
val spark: SparkSession = SparkSession
.builder()
.enableHiveSupport()
.master("local[*]")
.appName("sql")
.getOrCreate()


















 4279
4279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









