






http://blog.csdn.net/pipisorry/article/details/43271429
ABSTRACT
主题模型的一个关键弱点是需要大量的数据(如上千的文档)才能学习得到一致性好的主题,否则学习到的主题非常poor,即使数据量大,还是会学到不好的主题。在实践中许多文献集合缺少大量文件,导致经典主题模型LDA产生非常不合理的主题。
而基于知识的主题模型knowledge-based topic models,可以利用用户或者自动学习到的先验领域知识来指导模型产生更好的主题。
本文中的AMC算法就是类似人类的终身学习,通过从过去学习到的结果中挖掘可靠的先验知识来帮助未来的学习,从而得到更合理的主题。
AMC算法挖掘两种类型的先验知识must-link(meaning that two words should be in the same topic) and cannot-link(meaning that two words should not be in the same topic).
同时AMC还解决了自动挖掘先验知识中的两个问题:wrong knowledge and knowledge transitivity.
Introduction
解决the key weakness of topic modeling的方法
1. Inventing better topic models: This approach may be effective if a large number of documents are available. How- ever, since topic models perform unsupervised learning, if the data is small, there is simply not enough information to provide reliable statistics to generate coherent topics. Some form of supervision or external information beyond the given documents is necessary.
2. Asking users to provide prior domain knowledge: An ob- vious form of external information is the prior knowledge of the domain from the user.For example, the user can input the knowledge in the form of must-link and cannot- link. A must-link states that two terms (or words) should belong to the same topic, e.g., price and cost. A cannot- link indicates that two terms should not be in the same topic, e.g., price and picture. Some existing knowledge- based topic models (e.g., [1, 2, 9, 10, 14, 15, 26, 28]) can exploit such prior domain knowledge to produce better topics. However, asking the user to provide prior do- main knowledge can be problematic in practice because the user may not know what knowledge to provide and wants the system to discover for him/her. It also makes the approach non-automatic.
3. Learning like humans (lifelong learning): We still use the knowledge-based approach but mine the prior knowledge automatically from the results of past learning. This ap- proach works like human learning. We humans always retain the results learned in the past and use them to help future learning. However, our approach is very di erent from existing life- long learning methods (see bellow).
Lifelong learning is possible in our context due to two key observations:(怎么去寻找must-link和cannot-link)
1. Although every domain is different, there is a fair amount of topic overlapping across domains. For example, every product review domain(手机,闹钟,笔记本等等) has the topic of price, most electronic products share the topic of battery and some also have the topic of screen. From the topics learned from these domains, we can mine frequently shared terms among the topics.For example, we may find price and cost frequently appear together in some topics, which indicates that they are likely to belong to the same topic and thus form amust-link. Note that we have the frequency requirement because we want reliable knowledge.
2. From the previously generated topics from many domains, it is also possible to find that picture and price should not be in the same topic (a cannot-link).This can be done by fi nding a set of topics that have picture as a top topical term, but the term price almost never appear at the top of this set of topics, i.e., they are negatively correlated.
proposed lifelong learning approach:AMC MODEL(终身学习方法)
阶段1Phrase 1 (Initialization): 给定n个先验文档集 D = fD1; : : : ;Dng, 并分别使用主题模型如LDA来产生对应的主题集,合并所有主题集得到先验主题集S = U Si prior topics (p-topics). 然后使用multiple minimum supports frequent itemset mining algorithm从S中挖掘must-links M。
阶段2Phase 2 (Lifelong learning): 给定新的文档集Dt, 使用knowledge-based topic model (KBTM) with the must-links M得到主题集At,基于At,KBTM算法可以找到一个set of cannot-links C. 这样KBTM继续在must-links M 和 cannot-links C的指导下生成最终的主题集At. We will explain why we mine cannot-links based on At in Sec- tion 4.2. To enable lifelong learning, At is incorporated into S, which is used to generate a new set of must-links M.
lifelong learnning approach框图
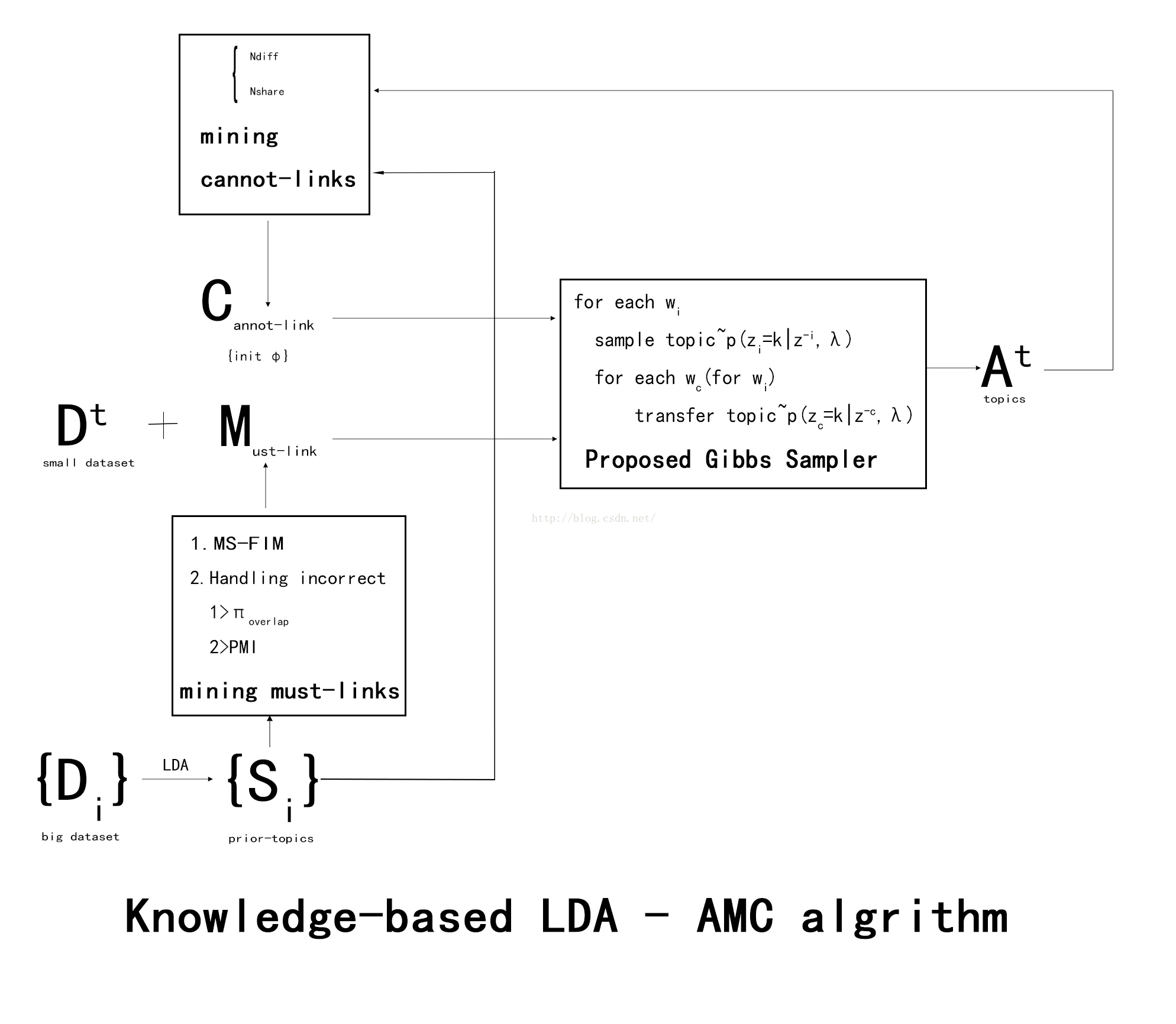
OVERALL ALGORITHM

先验知识挖掘
1.Mining Must-Link Knowledge
S集合中每个主题前15个词作为must-link候选集,通过多最小支持度-频繁项集挖掘算法(MS-FIM) 挖掘其中的must-links。
e.g. price, cost , we should expect to see price and cost as topical terms in the same topic across many domains.
In practice, top terms under a topic are expected to represent some similar semantic meaning. The lower ranked terms usually have very low probabilities due to the smoothing effect of the Dirichlet hyper-parameters rather than true correlations within the topic, leading to their unreliability. Thus, only top 15 terms are employed to represent a topic.
Given a set of prior topics (p-topics) S, we nd sets of terms that appear together in multiple topics using the data mining technique frequent itemset mining (FIM).
But A single minimum support is not appropriate. di fferent topics may have very di erent frequencies in the data.called the rare item problem. thus use the multiple minimum supports frequent itemset mining (MS-FIM)
2. Mining Cannot-Link Knowledge
在测试集Dt中挖掘主题At,其中的主要词作为cannot-links的候选集,通过下面两个条件(shared少而diff多的两个词)选取cannot-links。
For a term w, there are usually only a few terms wm that share must-links with w while there are a huge number of terms wc that can form cannot-links with w.
However, for a new or test do- main Dt, most of these cannot-links are not useful because the vocabulary size of Dt is much smaller than V . Thus, we focus only on those terms that are relevant to Dt.
we extract cannot-links from each pair of top terms w1 and w2 in each c-topic At j ∈ At: cannot-link mining is targeted to each c-topic.
determine whether two terms form a cannot-link:
Let the number of prior domains that w1 and w2 appear in different p-topics be Ndiff and the number of prior domains that w1 and w2 share the same topic be Nshare. Ndiff should be much larger than Nshare.
We need to use two conditions or thresholds to control the formation of a cannot-link: {即shared少而diff多的两个词应该是cannot-link}
1. The ratio Ndiff =(Nshare +Ndiff ) (called the support ratio) is equal to or larger than a threshold πc. This condition is intuitive because p-topics may contain noise due to errors of topic models.
2. Ndiff is greater than a support threshold πdiff . This condition is needed because the above ratio can be 1, but Ndiff can be very small, which may not give reliable cannot-links.
{如screen和pad在p-topics都很少出现Ndiff小,但他们也没有交集Nshare=0,这样support ratio is 1}
handling incorrect knowledge
挖掘出的先验知识可能有少量错误需要纠正。The idea is that the semantic relationships reflected by correct must-links and cannot-links should also be reason- ably induced by the statistical information underlying the domain collection.
Dealing with Issues of Must-Links
1. 单词可能有多个不同含义multiple meanings 或者存在含义传递 senses transitivity 问题.
2. 不是所有的 must-link 对于某个领域都是合理合适的。
识别Multiple Senses
Given two must-links m1 and m2, if they share the same word sense, the p-topics that cover m1 should have some overlapping with the p-topics that cover m2.
For example, must-links flight, bright and flight, luminance should be mostly coming from the same set of p-topics related to the semantic meaning \something that makes things visible" of light.
m1 and m2 share the same sense if
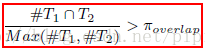
检测可能错误的先验知识
应用点互信息 Pointwise Mutual Information (PMI), PMI 是文本中词的相关性度量的常用方法 popular measure of word associations in text.
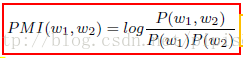
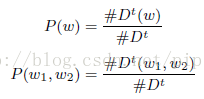
i.e.P(w1,w2) > P(w1)P(w2) => P(w1 | w2) > P(w1)
A positive PMI value implies a semantic correlation of terms, while a non-positive PMI value indicates little or no semantic correlation. Thus, we only consider the positive PMI values.
这样就可以构建一个must-link graph G,每个节点就代表一个must-link,语义相关的must-links间就存在一条边。
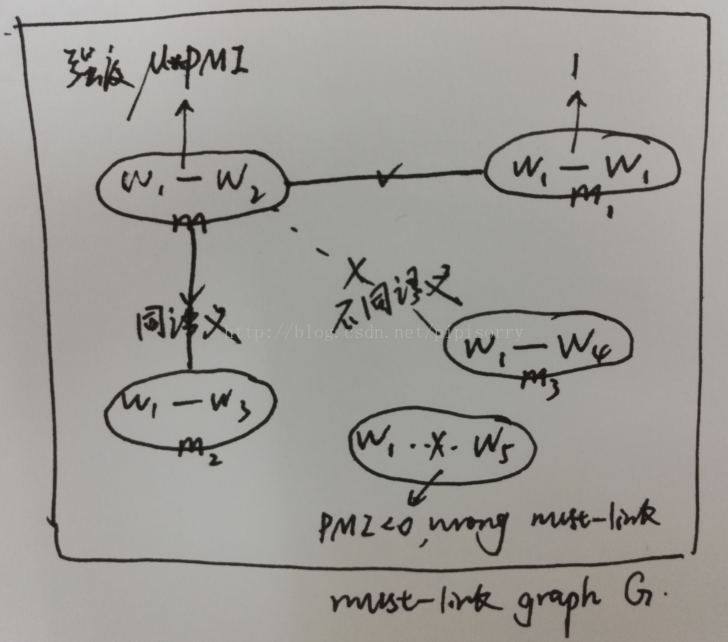
处理Cannot-Links的问题
two cases:
a) 错误的cannot-link或者说cannot-link有语义关联。A cannot-link contains terms that have semantic correlations. For example, battery, charger is not a correct cannot-link.
b) cannot-link对于特定领域不适配。A cannot- link does not fit for a particular domain.
we detect and balance cannot-links inside the sampling process. More specically, we extend Polya urn model to incorporate the cannot-link.
Proposed Gibbs Sampler
3种不同的Pólya罐子模型Pólya Urn Model
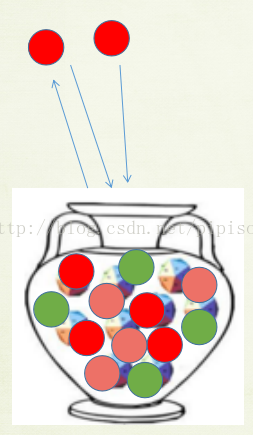
In the topic model context, a term can be seen as a ball of a certain color and a topic as an urn.
simple Polya urn (SPU) model :when a ball of a particular color is drawn from an urn, the ball is put back to the urn along with a new ball of the same color. The content of the urn changes over time, which gives a self-reinforcing property known as “the rich get richer". This process corresponds to assigning a topic to a term in Gibbs sampling.
The generalized Polya urn (GPU) model [22, 24] differs from SPU in that, when a ball of a certain color is drawn, two balls of that color are put back along with a certain number of balls of some other colors. These additional balls of some other colors added to the urn increase their proportions in the urn. This is the key technique for incorporating must- links as we will see below.
multi-generalized Polya urn
(M-GPU) model considers a set of urns in the sampling process simultaneously. M-GPU allows a ball to be transferred from one urn to another, enabling multi-urn interactions.
Thus, during sampling, the populations of several urns will evolve even if only one ball is drawn from one urn.
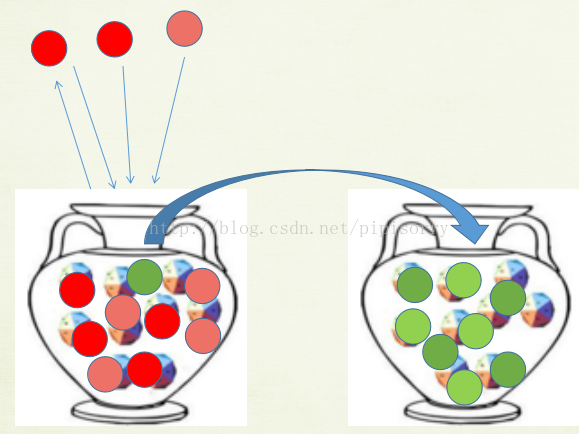
M-GPU就是采样到一个词的主题后,不仅将它自己加入到主题罐子k中,也将语义相似的must-link添加到罐子k中;不仅如此,还要将cannot-links从当前罐子k中移到那个词比例较高的另一个主题罐子中。
Proposed M-GPU Model
In M-GPU, when a term w is assigned to a topic k, each term w0 that shares a must-link with w is also assigned to topic k by a certain amount, which is decided by the matrix λw0;w (see Equation).
通过sampling distribution从must-link graph G中采样w的一个must-link set然后promote.
deal with multiple senses problem in M-GPU
If a term w does not have must-links, then we do not have the multiple sense problem caused by must-links. If w has must-links, the rationale here is to sample a must-link (say m) that contains w to be used to represent the likely word sense from the must-link graph G The sampling distribution will be given in Section 5.3.3. Then, the must-links that share the same word sense with m, including m, are used to promote the related terms of w.
deal with possible wrong must-links
parameter factor to control how much the M-GPU model should trust the word relationship indicated by PMI.
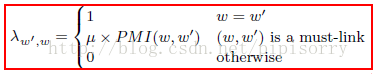
deal with cannot-links
M-GPU允许 multi-urn 交互, when sampling a ball representing term w from a term urn UW k , we want to transfer the balls representing the cannot-terms of w, say wc (sharing cannot-links with w) to other urns , i.e., decreasing the probabilities of those cannot-terms under this topic while increasing their corresponding probabilities under some other topic. In order to correctly transfer a ball that represents term wc, it should be transferred to an urn which has a higher proportion of wc.
the M-GPU sampling scheme

采样分布
For each term wi in each document d:
Phase 1 (Steps 1-4 in M-GPU): 计算词wi采样主题的条件分布。
a) 从must-link graph G中采样包含wi的must-link mi
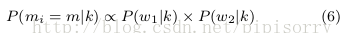
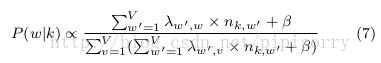
b) create a set of must-links {m0} where m0 is either mi or a neighbor of mi in the must-link graph G.
c) 给词wi赋予主题k的条件概率定义如下:
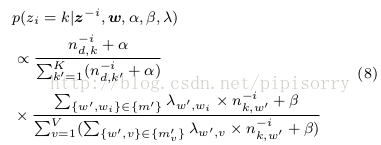
where ni is the count excluding the current assignment of zi, i.e., zi. w refers to all the terms in all documents in the document collection Dt and wi is the current term to be sampled with a topic denoted by zi. nd;k denotes the number of times that topic k is assigned to terms in document d. nk;w refers to the number of times that term w appears under topic k. and are prede ned Dirichlet hyper-parameters. K is the number of topics, and V is the vocabulary size. fm0 vg is the set of must- links sampled for each term v following Phase 1 a) and b), which is recorded during the iterations.
Phase 2 (Step 5 in M-GPU)deals with cannot-links.
抽出wi的一个cannot-link wc,对wc的主题重新采样,i.e. transfer wc's topic到wc比例较高的另一个主题中.
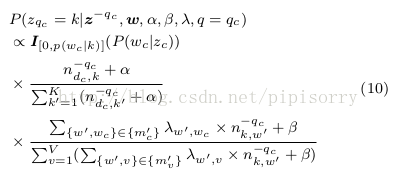
I() is an indicator function, which restricts the ball to be transferred only to an urn that contains a higher proportion of term wc. If there is no topic k has a higher proportion of wc than zc, then keep the original topic assignment, i.e.,assign zc to wc.
from:http://blog.csdn.net/pipisorry/article/details/43271429
ref:KDD2014-Zhiyuan(Brett)Chen-Mining Topics in Documents














 1386
1386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









