









python实现Logmmse声音降噪算法
1.所需环境
pip install logmmse
pip install wave
pip install numpy
2.具体代码
import logmmse
import wave
import numpy as np
if __name__ == '__main__':
# out = logmmse.logmmse_from_file('test.wav')
# print(out)
# 读取音频
path = 'test.wav'
f = wave.open(path, "r")
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
print("nchannels:", nchannels, "sampwidth:", sampwidth, "framerate:", framerate, "nframes:", nframes)
data = f.readframes(nframes)
f.close()
data = np.fromstring(data, dtype=np.short)
# 降噪
data = logmmse.logmmse(data=data, sampling_rate=framerate)
# 保存音频
file_save = 'process.wav'
nframes = len(data)
f = wave.open(file_save, 'w')
f.setparams((1, 2, framerate, nframes, 'NONE', 'NONE')) # 声道,字节数,采样频率,*,*
# print(data)
f.writeframes(data) # outData
f.close()
3.实现效果
降噪前
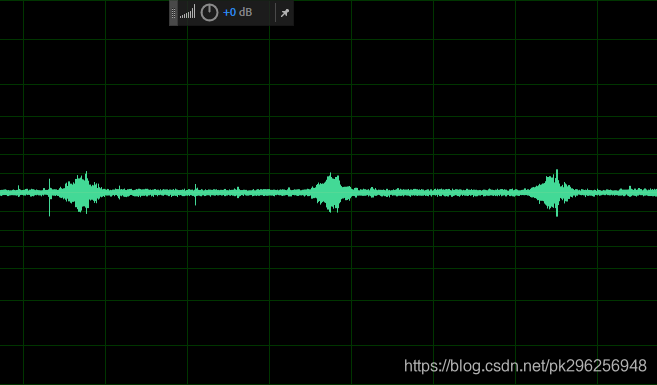
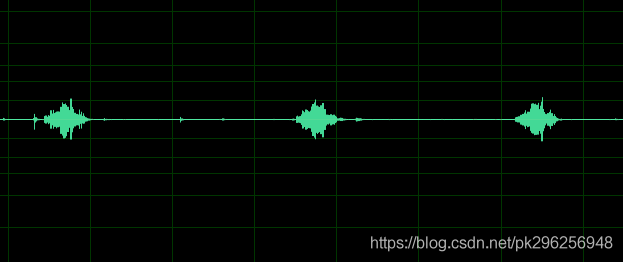
降噪后














 5009
5009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









