









作者:jiaxin_12
来源 https://www.cnblogs.com/YangJiaXin/p/10933458.html
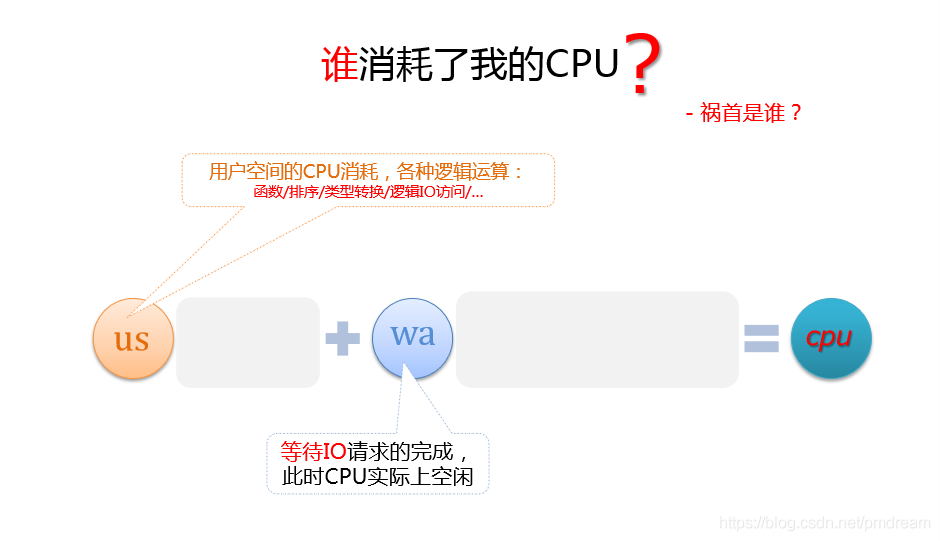
谁在消耗cpu?
祸首是谁?
-
用户
-
IO等待
-
产生影响
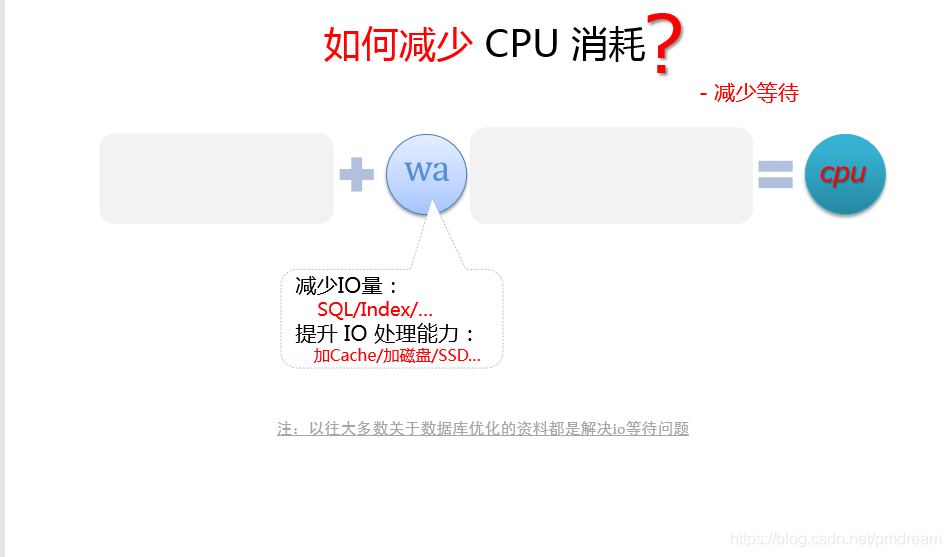
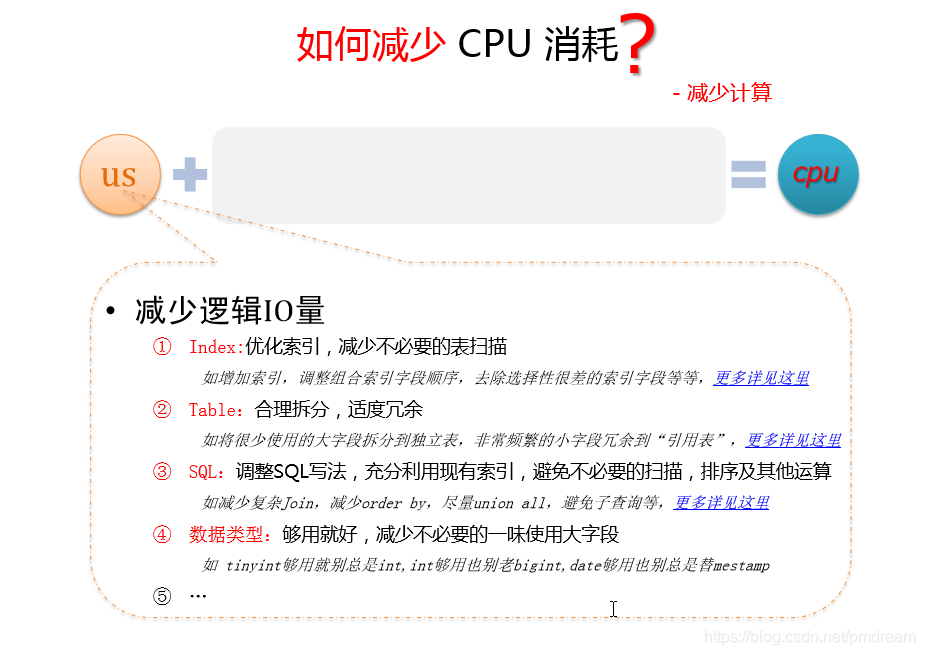
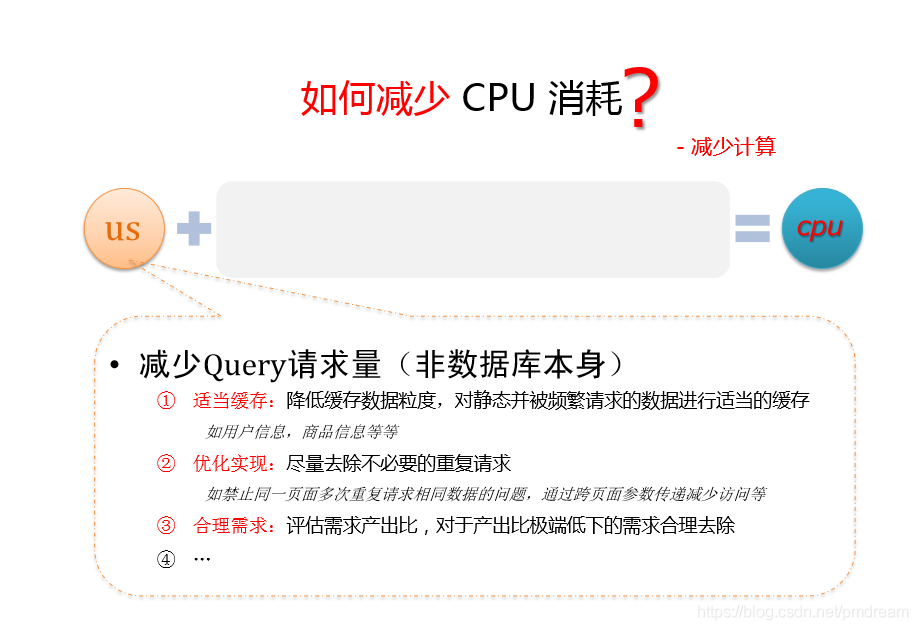
如何减少CPU消耗?
-
减少等待
-
减少计算
-
升级cpu
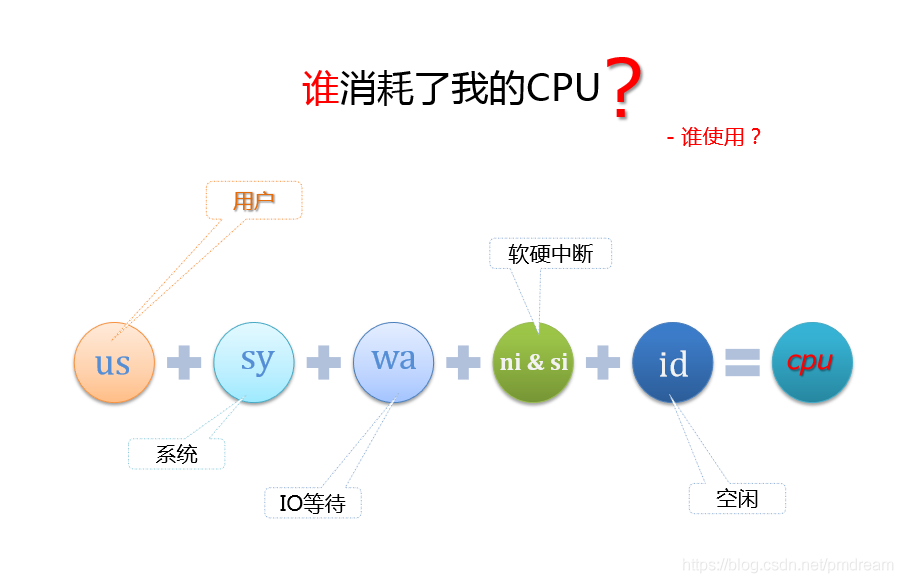
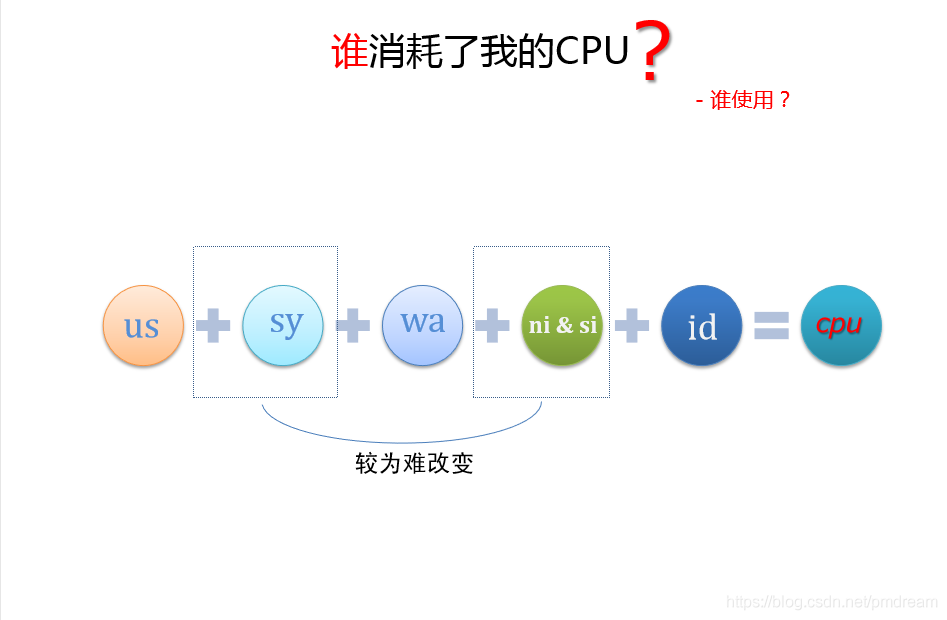
罪魁祸首是谁?
用户
用户空间CPU消耗,各种逻辑运算
注意:TPS:TPS:是Transactions Per Second的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。
用户空间消耗大量cpu,产生的系统调用是什么?那些函数使用了cpu周期?
IO等待
等待IO请求的完成,但是实际上此时CPU空闲
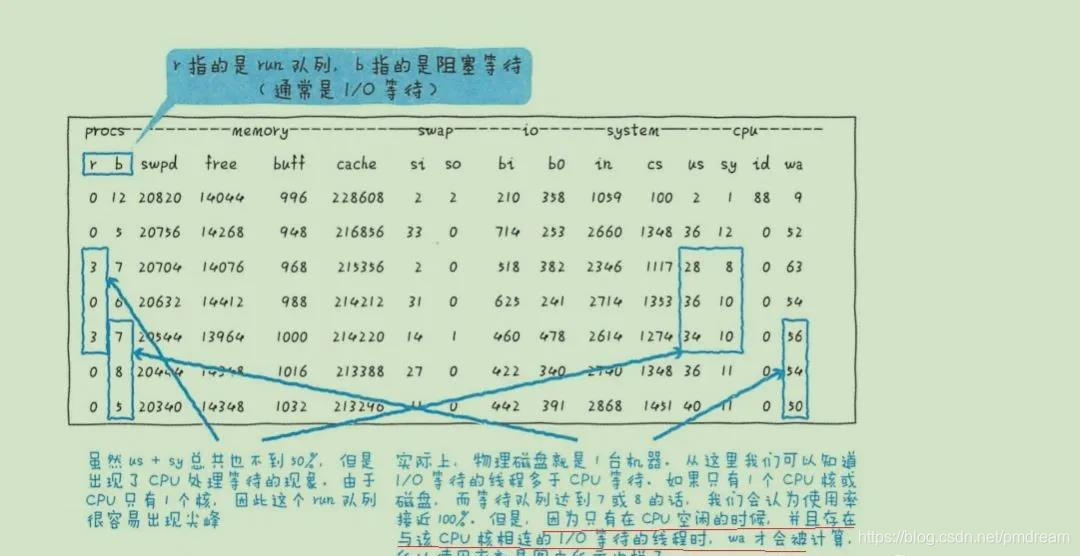
如vmstat中的wa 很高。但IO等待增加,wa也不一定会上升(请求I/O后等待响应,但进程从核上移开了)
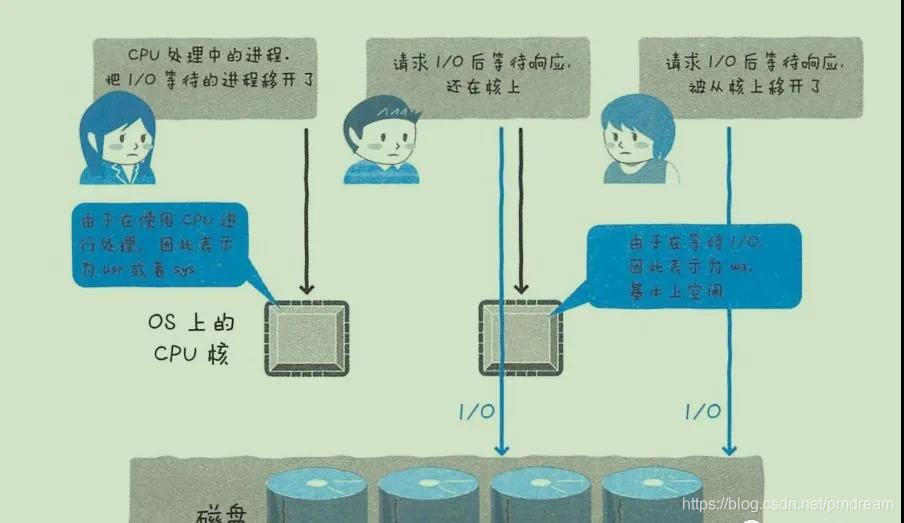
产生影响
用户和IO等待消耗了大部分cpu
吞吐量下降(tps)
查询响应时间增加
慢查询数增加
对mysql的并发陡增,也会产生上述影响
如何减少CPU消耗?
减少等待
减少IO量
SQL/index,使用合适的索引减少扫描的行数(需平衡索引的正收益和维护开销,空间换时间)
提升IO处理能力
加cache/加磁盘/SSD
减少计算
减少逻辑运算量
- 避免使用函数,将运算转移至易扩展的应用服务器中
如substr等字符运算,dateadd/datesub等日期运算,abs等数学函数- 减少排序,利用索引取得有序数据或避免不必要排序
如union all代替 union,order by 索引字段等- 禁止类型转换,使用合适类型并保证传入参数类型与数据库字段类型绝对一致
如数字用tiny/int/bigint等,必需转换的在传入数据库之前在应用中转好- 简单类型,尽量避免复杂类型,降低由于复杂类型带来的附加运算。更小的数据类型占用更少的磁盘、内存、cpu缓存和cpu周期
- ....
减少逻辑IO量
index,优化索引,减少不必要的表扫描
如增加索引,调整组合索引字段顺序,去除选择性很差的索引字段等等- table,合理拆分,适度冗余
如将很少使用的大字段拆分到独立表,非常频繁的小字段冗余到“引用表”- SQL,调整SQL写法,充分利用现有索引,避免不必要的扫描,排序及其他操作
如减少复杂join,减少order by,尽量union all,避免子查询等- 数据类型,够用就好,减少不必要使用大字段
如tinyint够用就别总是int,int够用也别老bigint,date够用也别总是timestamp....
减少query请求量(非数据库本身)
- 适当缓存,降低缓存数据粒度,对静态并被频繁请求的数据进行适当的缓存
如用户信息,商品信息等- 优化实现,尽量去除不必要的重复请求
如禁止同一页面多次重复请求相同数据的问题,通过跨页面参数传递减少访问等- 合理需求,评估需求产出比,对产出比极端底下的需求合理去除
- ....
升级cpu
- 若经过减少计算和减少等待后还不能满足需求,cpu利用率还高T_T
-
是时候拿出最后的杀手锏了,升级cpu,是选择更快的cpu还是更多的cpu了?
- 低延迟(快速响应),需要更快的cpu(每个查询只能使用一个cpu)
- 高吞吐,同时运行很多查询语句,能从多个cpu处理查询中收益
原作者参考
《高性能MySQL》
《图解性能优化》
大部分整理自《MySQL Tuning For CPU Bottleneck》
个人总结:
这是一篇很深度的好文,有些不懂得地方。比如这些us wa什么的概念是什么意思。
但是我个人猜测IO waiting 是wa的意思。
sy = system
us = user
ni & si 是软硬中断
id = idle 空闲的
系统和软硬中断感觉很底层,很难去改变。我们对数据库进行优化的时候,减少CPU消耗最主要是减少I/O次数。
所以感觉减少Mysql的压力,能不在mysql做的计算,排序和函数就不要用mysql去做,虽然mysql也有着各种求和算平均等等函数,少用类型转换。
因为等待I/O的完成,CPU是空闲的。
因为我们很难去改变mysql的服务器的性能,增加核心和使用更大更快的SSD,加入cache等等都是钱啊,不现实。
那么我们还是通过代码的角度来优化它。
1.避免使用函数
2. 减少排序,应该直接利用索引获取到有序的数据,如union all代替 union
3. 数字使用tiny/int/bigint等等 4.避免使用复杂的类型,更小的数据类型占用更少的磁盘 内存和CPU缓存和CPU周期
5.索引要选好,减少全表索引
6.合理拆分数据库,适度的冗余(尽量减少连表查询) 如将很少使用的大字段拆分到独立表,非常频繁的小字段冗余到“引用表”
7.如tinyint够用就别总是int,int够用也别老bigint,date(yyyymmdd)够用也别总是timestamp
8.对于静态数据要进行适当地缓存,比如频繁请求的但是又不会经常更改的
比如用户信息,商品信息等等。我们系统中的产品类型都加到缓存里面
Q:date与timestamp和datetime的区别?
DATETIME类型用在你需要同时包含日期和时间信息的值时。MySQL检索并且以'YYYY-MM-DD HH:MM:SS'格式显示DATETIME值,支持的范围是'1000-01-01 00:00:00'到'9999-12-31 23:59:59'。
DATE类型用在你仅需要日期值时,没有时间部分。MySQL检索并且以'YYYY-MM-DD'格式显示DATE值,支持的范围是'1000-01-01'到'9999-12-31'。
在MySQL检索并且显示TIMESTAMP值取决于显示尺寸的格式如下表。"完整"TIMESTAMP格式是14位,但是TIMESTAMP列可以用更短的显示尺寸创造:
列类型 显示格式
TIMESTAMP(14) YYYYMMDDHHMMSS
TIMESTAMP(12) YYMMDDHHMMSS
TIMESTAMP(10) YYMMDDHHMM
TIMESTAMP(8) YYYYMMDD
TIMESTAMP(6) YYMMDD
TIMESTAMP(4) YYMM
TIMESTAMP(2) YY
然后在设计数据库的时候,Timestamp和DateTime怎么选呢?
从存储限制上来说,虽然Datetime字段类型多占用了1些存储空间,但是却可以存储足够大的时间范围,适应性和可控性都Timestamp要强。
然而Timestamp字段类型的存储,几乎就等于是Int(有符号)类型的存储,而且还只用了Int(有符号)类型的2个字节的存储空间。这种情况下,如果有时间戳的存储需求,完全可以使用Unsigned Int(无符号Int)或者Bigint类型来进行时间戳的存储处理,这样它不但可以充分利用Int类型的存储空间来存储更长的时间,同时也能够进行插入赋于CURRENT_TIMESTAMP的能力,从而弥补Timestamp字段类型的不足。
从存储行为上来说,Timestamp的自动插入能力,Datetime也是支持的(在数据库中CURRENT_TIMESTAMP),所以Timestamp的额外亮点,就是在于具备自动更新的能力。但是这个能力,还要看设计者的评估,是否适合放在MySQL数据库这里进行更新。
所以我们存储时间戳,一般使用bigint来存时间戳,因为如果使用数据库中的timestamp的来存时间戳的话,就只能到2038年
所以这个是缺陷,但是使用bigint来村时间戳就解决了这个问题。
但是所以说使用时间戳的好处主要在于时区问题:不同地区时区不一样,如果你存个2016-10-14 9:40:32,在另外的时区就不对了。存成unix时间戳,容易转换成不同时区的时间。
时间戳还有一个好处就是,使用时间戳会比datetime类型在大量数据的时候会快一点。
所以还是用bigint吧~
参考:https://www.jianshu.com/p/83ffccc5215e (大佬贴)














 1569
1569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









