







MySQL 为什么选择使用 B+ 树?
1.前言
无论是表中的数据(主键索引)还是辅助索引最终都会使用 B+ 树来存储数据,其中前者在表中会以 <id, row> 的方式存储,而后者会以 <index, id> 的方式进行存储
-
在主键索引中,
id是主键,我们能够通过id找到该行的全部列; -
在辅助索引中,索引中的几个列构成了键,我们能够通过索引中的列找到
id,如果有需要的话,可以再通过id找到当前数据行的全部内容;
2. 有两个方面让InnoDB选择了B+树
-
InnoDB 需要支持的场景和功能需要在特定查询上拥有较强的性能;
-
CPU 将磁盘上的数据加载到内存中需要花费大量的时间,这使得 B+ 树成为了非常好的选择;
3. 为什么不选Hash,Hash的缺点?
虽然哈希可能能达到o(1)的时间复杂度访问一条数据或者修改的时候。
但是使用hash作为主键的索引时候,处理范围查询和排序性能很差,只能进行全表扫描并判断是否满足条件。
使用 B+ 树其实能够保证数据按照键的顺序进行存储,也就是相邻的所有数据其实都是按照自然顺序排列的,使用哈希却无法达到这样的效果,因为哈希函数的目的就是让数据尽可能被分散到不同的桶中进行存储。
因为hash特点,所以很可能会面临全表扫描。
4.为什么不选B树而选择B+?
计算机在读写文件时会以页为单位将数据加载到内存中。页的大小可能会根据操作系统的不同而发生变化,不过在大多数的操作系统中,页的大小都是 4KB。
当我们需要在数据库中查询数据时,CPU 会发现当前数据位于磁盘而不是内存中,这时就会触发 I/O 操作将数据加载到内存中进行访问,数据的加载都是以页的维度进行加载的,然而将数据从磁盘读取到内存中所需要的成本是非常大的,普通磁盘(非 SSD)加载数据需要经过队列、寻道、旋转以及传输的这些过程,大概要花费 10ms 左右的时间。
(todo 加载数据的这些操作含义,操作系统)
减少随机I/O,才能提高性能。
B 树与 B+ 树的最大区别就是,B 树可以在非叶结点中存储数据,但是 B+ 树的所有数据其实都存储在叶子节点中,当一个表底层的数据结构是 B 树时,假设我们需要访问所有『大于 4,并且小于 9 的数据』
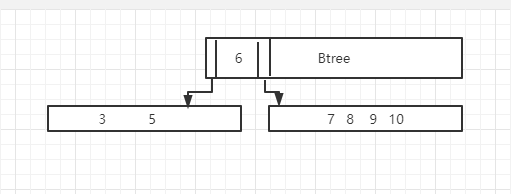
如果不考虑任何优化,在上面的简单 B 树中我们需要进行 4 次磁盘的随机 I/O 才能找到所有满足条件的数据行。
-
加载根节点所在的页,发现根节点的第一个元素是 6,大于 4;
-
通过根节点的指针加载左子节点所在的页,遍历页面中的数据,找到 5;
-
重新加载根节点所在的页,发现根节点不包含第二个元素;
-
通过根节点的指针加载右子节点所在的页,遍历页面中的数据,找到 7 和 8;
B树和B+的区别,在于B树的所有节点都可能包含了目标数据,所以我们总是要从根节点向下遍历子树查找满足条件的数据行,这样会带来大量的I/O,B树的最大性能问题。
B+ 树中就不存在这个问题了,因为所有的数据行都存储在叶节点中,而这些叶节点可以通过『指针』依次按顺序连接
所以在B+书的时候,当我们遍历数据的时候们可以在多个子节点质检进行跳转,子节点也是个链表,这样可以节省大量的磁盘I/O的时间,而且也不需要跟B树一样因为查出来的数据不在一个节点,还需要对结果做处理,拼接和排序!!
通过一个 B+ 树最左侧的叶子节点,我们可以像链表一样遍历整个树中的全部数据,我们也可以引入双向链表保证倒序遍历时的性能。
高度为 3 的 B+ 树就能够存储千万级别的数据,实践中 B+ 树的高度最多也就 4 或者 5,所以高度这并不是影响性能的根本问题。
转载:















 5424
5424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









