







机器学习基本概念与定义
什么是机器学习
在《机器学习实战》书中,作者给出了两个定义,首先是笼统的定义:
机器学习研究如何让计算机不需要明确的程序也能具备学习能力
之后是更偏工程化的定义:
一个计算机程序在完成任务T之后,获得经验E,其表现效果为P,如果任务T的性能表现,也就是用以衡量的P,随着E的增加而增加,可以称其为学习
系统用来学习的这些示例,称为训练集,每一个训练示例称为训练实例或者训练样本。
机器学习优点
相比于传统的编程方法,使用机器学习解决问题的方式具有以下优点:
- 对于复杂的问题,机器学习的方式代码更加简短,易于维护,并且可能更加的准确。
- 可以自动适应问题中的一些变化因素和新的数据
- 机器学习可以帮助人类学习,通过检查机器学习到了什么可以给予我们新的思路。
机器学习的种类
机器学习可以分为许多类别,以是否在人类的监督下训练分:
- 监督式学习
- 无监督式学习
- 半监督式学习
- 强化学习
是否可以动态的增量学习:
- 在线学习
- 批量学习
是否将新的数据点和已知的数据点进行匹配,对训练数据进行模式检测,然后建立预测模型:
- 基于实例的学习
- 基于模型的学习
监督式学习与非监督式学习
监督式学习
在监督式学习中,所使用的数据集包含一个解决方案,成为标签或者标记。
这种分类方式的一个应用就是分类任务,另外一个则是预测变量。预测变量指的是一组给定的特征,比如书中提到的预测汽车的价格,这里的属性就可以是里程、使用年限等,要训练这样一个系统,需要使用大量的数据以及它们的标签(实际价格)。
另外需要注意的是,在机器学习中,属性是一种数据类型(如上面提到的里程),而特征则可以看做属性+对应的值,如里程=1500公里。
无监督学习
无监督式学习里面的数据都是未经过标记的。系统会在没有老师的情况下进行学习。它可以将相似的数据放在一组(尽管它不知道那一组具体是什么),称为聚类(与分类对应)。
无监督式学习还有一个任务就是降维,其目的就是在不丢失太多信息的前提下简化数据,方法之一就是降多个相关特征合并为一个(比如将汽车年限和里程数合并为磨损度),降维的过程称为特征提取。
另外一个任务就是异常检测,比如它可以在将另外一个机器学习实例需要的数据输入之前,检测过滤掉其中的异常值。
最后一个任务是关联规则学习,用于挖掘数据并发现属性之间的联系。
半监督式学习
其训练数据一般包括大量未标记的数据以及少量标记的数据,一般是无监督式学习以及监督式学习算法的结合。
强化学习
进行学习的过程中,不会给出数据的标签,学习过程中如果做出一种决策,则会获得回报或者惩罚,依次来自己进行学习。
批量学习和在线学习
批量学习
批量学习的特点是无法进行增量学习,通常情况下都是离线完成的。离线学习指的是先使用训练集在投入应用前进行训练,训练好后投入使用,使用的过程中无法学习新数据。如果想要学习新的数据,只能将其与旧数据混合在一起重新进行训练。
在线学习
在这种学习方法中,可以循序渐进的给系统提供训练数据,逐步积累成果(通常是离线完成的)。提供的数据可以是单独的,也可以采用**小批量(mini-batches)**的小组数据进行训练。新的数据一旦被学习,就可以丢弃掉,以节省大量空间。
对于超大的数据集,在线学习也同样适用(核外学习)。算法每次只加载部分数据,针对这部分数据进行训练,然后不断重复这个过程,知道完成所有数据的训练。
在线学习系统的一个重要参数是适应不断变化的数据的速度,学习率。如果学习率设置的很高,则系统会迅速适应新的数据,但同时也会很快忘记旧数据。如果学习率很低,则学习会非常缓慢,好处是会对数据中的噪声和非典型数据点不敏感。
基于实例的学习和基于模型的学习
另一种对机器学习系统进行分类的方法是看它们如何进行泛化。即通过在指定的训练集上进行训练,在面对未见过的数据集时也能给出期望的结果。泛化的方式有两种:基于实例的学习和基于模型的学习。
基于实例的学习
系统先完全记住学习示例,然后通过某种相似度度量方式将其泛化到新的实例。
基于模型的学习
指的是构建示例的模型,然后使用该模型进行预测。
一般我们使用效用函数来评价模型有多好,或者使用成本函数来衡量模型有多差。
机器学习主要面临的挑战
主要面临的两个挑战是“坏算法”和“坏数据”。
坏数据包含以下几点:
- 训练数据不足
- 训练数据不具备代表性
- 质量差的数据
- 无关的特征
坏算法则包含以下几点:
- 数据过度拟合
- 训练数据不足
测验与验证
为了了解我们训练好的模型的泛化能力,我们需要对其进行测试。一般常用的手段是将数据集分为测试集和训练集。我们使用训练集中的数据来训练模型,然后使用测试集的数据测试训练好的模型。应对新场景的误差率称为泛化误差,
如果训练误差很低但是泛化误差很高,则说明模型存在过度拟合的问题。另外,一般情况下使用80%的数据进行训练,剩下的20%数据用于测试。
超参数的选取
一般情况下我们通过正则化来避免对数据的过度拟合,即约束模型来避免其过度复杂,那么在解决问题的时候,我们就不可避免的要考虑选取合适的正则化参数(称为超参数)。
一个常见的解决方式是将数据集再单独分离出来一个集合,称为验证集。在训练集上,使用不同的超参数来训练模型,然后在验证集上测试,选择最好的那个模型和对应的超参数,如果结果满意则进一步在测试集上获取泛化误差。
为了避免验证集消耗过多数据,常常使用交叉验证的方法:将训练集分为若干个互补的子集,然后每个模型通过这些子集的不同组合来进行训练,其余子集用于验证,之后将得到的合适的超参数和模型使用测试集得到泛化误差。
一个简单的拟合例子
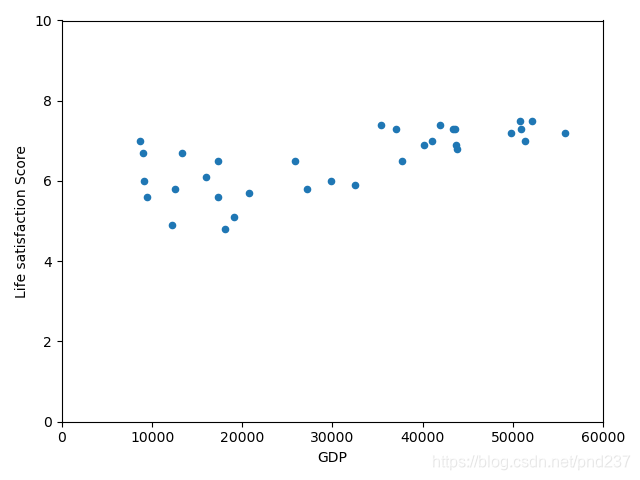
在书中,作者给出了一个简单的拟合例子,用于拟合国家人均GDP和幸福指数的关系,在这里我对部分代码进行了修改使其能正常运行。里面使用了pandas的部分功能,更具体的使用方法见我写的其他博客,使用的数据集见本文章的附件。
程序如下:
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import numpy as np
oecd_bli = pd.read_csv("datasets\lifesat\oecd_bli_2015.csv",thousands=",")
gdp_per_capita = pd.read_csv("datasets/lifesat/gdp_per_capita.csv",thousands=",",
delimiter="\t",encoding="latin1",na_values="n/a")
#读取原始的数据集
gdp_per_capita = gdp_per_capita.rename(columns={"2015":"GDP"})
oecd_bli = oecd_bli.rename(columns={"Value":"Life satisfaction Score"})
#修改一下列名
oecd_bli = oecd_bli[oecd_bli.Indicator == "Life satisfaction"][oecd_bli.Inequality == "Total"]
#选择合适指标(幸福指数)
df = pd.merge(oecd_bli,gdp_per_capita,how="inner",on="Country")
#将两个数据集进行合并
df.plot(kind="scatter",x="GDP",y="Life satisfaction Score",xlim=[0,60000],ylim=[0,10])
#合并后的的数据集中2015这一列代表GDP,Value这一列代表幸福指数
plt.show()
X = np.array(df["GDP"].values).reshape(-1,1)
y = np.array(df["Life satisfaction Score"].values).reshape(-1,1)
#将数据以numpy数组的形式提取
lin_reg_model = sklearn.linear_model.LinearRegression()
#选择一个模型
lin_reg_model.fit(X,y)
#训练模型
X_new = [[22587]]
#需要预测的值 [[6.28653637]]
print(lin_reg_model.predict(X_new))
#输出预测结果
散点图如下:
我们也可以使用k近邻算法,只需要将
lin_reg_model = sklearn.linear_model.LinearRegression()
替换为
lin_reg_model = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
即可














 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









