







1. 结构
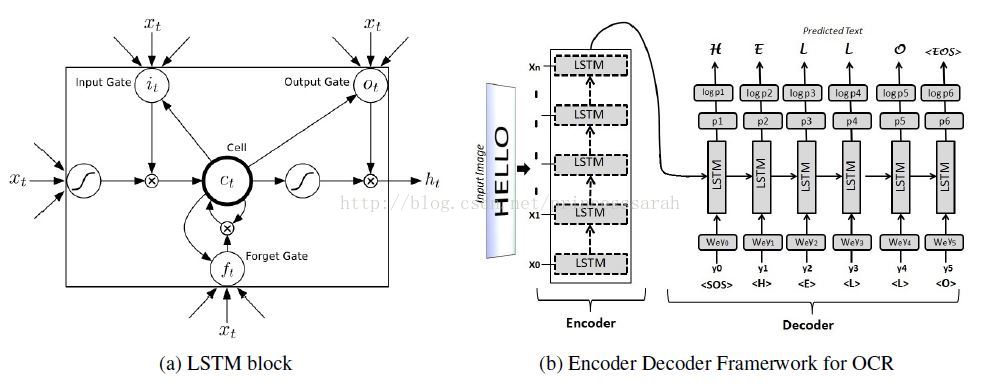
2. Encoder
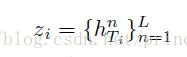 作为Decoder的状态初始值
作为Decoder的状态初始值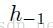 ,其中n为layer层,N为总层数。
,其中n为layer层,N为总层数。
即,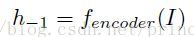 。
。
。
3. Decoder
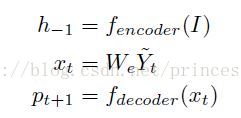
(1)编码由t=0时刻输入marker <SOS>开始;(SOS means start of sequence)
(2)t=-1时,状态初始值由zi给出;
(3)第一个字符的预测:
输入——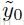 =<SOS>,
=<SOS>,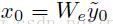
输入——
=<SOS>,
输出——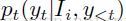
第t个字符预测:
输入——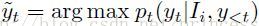 ,xt
,xt
,xt
输出——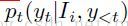
(4)一直迭代到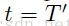 ,
, ,
,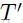 虽然先验未知,但又<EOS>可以表明的长度。
虽然先验未知,但又<EOS>可以表明的长度。
,,虽然先验未知,但又<EOS>可以表明的长度。
补充:decoder在t时刻的输入是t-1时刻输出的嵌入式,即乘以We后的x。
4. Training
(1)Loss
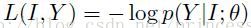
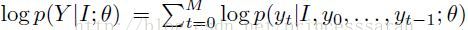
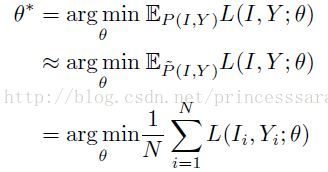
虽然P(I,Y)不清楚,但可以有经验获得一个经验分布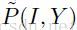 。
。
。
5. Implementation Details
(1) resize the images to height of 30 pixels;
(2)The resized binary images are then used as an input to the two layer LSTM encoder-decoder architecture. Use embedding size of 25;
(3)The dinmensionality of output layer in decoder is equal to number of unique symbols in the dataset.
(4) RMS prop with step size of 0.0001;
momentum of 0.99 is used to potimize the loss.














 5791
5791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









