








深入浅出GNU X86-64 汇编
本文是我翻译自 Introduction to X86-64 Assembly for Compiler Writers. 因为之前在学校学的X86汇编都是32位的,而现在的PC机处理器基本都是64位的,我的Linux机器也是64位的,反汇编C语言时,生成的是64位汇编,所以翻译一下这篇文章。这篇文章深入浅出的描述了C和X86-64汇编的转换关系。
目录
概览
本文是X86-64汇编语言的简介,是写给使用GNU软件工具的编译器开发新手的。本文不是对体系结构的详尽描述,但它足以为您熟悉官方手册以及编写大部分本科课程的C编译器后端提供指导。X86-64是对X86 32-bit体系结构的64-bit扩展的通称。X64, AMD64, Intel-64, and EMT64和X86-64这些叫法其实是指同一个东西,但IA64是不同的。维基百科中的X86-64条目有对这些术语的历史和差异的很好的概述。
X86-64指令集在Intel-64 和 IA-32 体系结构软件开发手册中有完备的描述,手册可以在网上免费获取。你需要浏览这些手册并获取关键的细节。建议你把PDF文档下载到你的笔记本上,保证随时可用,然后阅读手册的以下章节:
Volume 1: Sections 2.1, 3.4, and 3.7
Volume 2: 根据需要阅读相关指令.
开源汇编工具
对于本文中的例子,我们都是使用GNU编译器(gcc)和汇编器(as 或者 gas)。一个快速了解汇编语言的方式就是去看编译器输出的汇编程序。使用gcc的-S选项来编译,编译器就会输出汇编而不是二进制程序。在类Unix系统上,汇编程序源文件以.s结尾。
(后缀 “s” 代表 “source” 文件, 而后缀 “a”表示 “archive” (library) 文件.) 所以, gcc -S hello.c :
#include <stdio.h>
int main( int argc, char *argv[] )
{
printf("hello %s\n","world");
return 0;
}会生成 hello.S,如下:
.file "test.c"
.data
.LC0:
.string "hello %s\n"
.LC1:
.string "world"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl %edi, -4(%rbp)
movq %rsi, -16(%rbp)
movl $.LC0, %eax
movl $.LC1, %esi
movq %rax, %rdi
movl $0, %eax
call printf
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 4.4.7 20120313 (Red Hat 4.4.7-11)"
.section .note.GNU-stack,"",@progbits注意汇编程序由三个不同的元素组成:
- 指示(Directives) 以点号开始,用来指示对编译器,连接器,调试器有用的结构信息。指示本身不是汇编指令。例如,.file 只是记录原始源文件名。.data表示数据段(section)的开始地址, 而 .text 表示实际程序代码的起始。.string 表示数据段中的字符串常量。 .globl main指明标签main是一个可以在其它模块的代码中被访问的全局符号 。至于其它的指示你可以忽略。
- 标签(Labels) 以冒号结尾,用来把标签名和标签出现的位置关联起来。例如,标签.LC0:表示紧接着的字符串的名称是 .LC0. 标签main:表示指令 pushq %rbp是main函数的第一个指令。按照惯例, 以点号开始的标签都是编译器生成的临时局部标签,其它标签则是用户可见的函数和全局变量名称。
指令(Instructions) 实际的汇编代码 (pushq %rbp), 一般都会缩进,以便和指示及标签区分开来。
运行gcc可以把这个汇编代码转换为可执行程序。gcc会推断出它是汇编程序,对它进行汇编并和标准库链接在一起:
% gcc hello.s -o hello
% ./hello
hello world把汇编代码编译成目标程序(obj), 然后使用nm工具来查看里面的符号也很有趣:
% gcc hello.s -c -o hello.o
% nm hello.o
0000000000000000 T main
U printf这显示出了连接器需要的信息。main在text(T) 段里,位于位置0x0000000000000000。 printf则是未定义(U)的,因此它必须从标准库获取。对于未定义为.globl的标签比如LC0,则不存在了。如果你想详细了解编译器生成的指令,利用GCC生成的汇编代码,你可以通过查找Intel的手册来一探究竟。
既然你已经知道需要用哪些工具了,那让我们开始来看看指令的细节吧。
小贴士: AT&T 语法和 Intel 语法
注意GNU工具使用传统的AT&T语法。类Unix操作系统上,AT&T语法被用在各种处理器上。Intel语法则一般用在DOS和Windows系统上。下面是AT&T语法的指令:
movl %esp, %ebp
movl是指令名称。%则表明esp和ebp是寄存器.在AT&T语法中, 第一个是源操作数,第二个是目的操作数。
在其他地方,例如interl手册,你会看到是没有%的intel语法, 它的操作数顺序刚好相反。下面是Intel语法:
MOVQ EBP, ESP
当在网页上阅读手册的时候,你可以根据是否有%来确定是AT&T 还是 Intel 语法。
寄存器和数据类型
x86-64有大约十六个通用64位整数寄存器:

我们说”大约十六个通用”是因为早期版本的处理器每个寄存器都有其特殊用途,并不是所有指令都可以应用到每一个寄存器。随着设计的进展,新的指令和寻址模式被添加进来,使得很多寄存器变成了等同的。少数留下来的指令,特别是和字符串处理相关的,要求使用%rsi 和%rdi。另外,两个寄存器被保留下来分别作为栈指针 (%rsp) 和基址指针 (%rbp)。最后的8个寄存器是编号的并且没有特殊限制。
多年来,体系结构从8位扩展到16位,32位,因此每个寄存器都有一些内部结构:
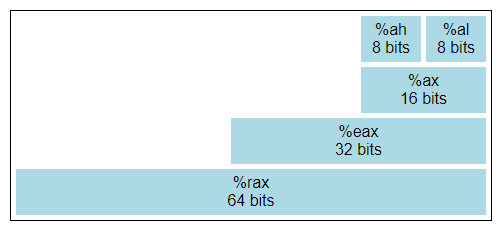
%rax的低8位是8位寄存器%al, 仅靠的8位是%ah。低16位是 %ax, 低32位是 %eax,整个64位是%rax。
寄存器%r8-%r15也有相同结构,但命名方式稍有不同:

为了简单点,我们只关注64位寄存器。不过大多数编译器产品混合使用32和64位模式。32位寄存器用来做整数计算,因为大多数程序不需要大于 2^32 的整数值。64位一般用来保存内存地址(指针),使得可以寻址到16EB虚拟内存。
寻址模式
你最先应该了解的是MOV指令,它在寄存器和内存之间移动数据。X86-64 使用复杂指令集 (CISC),所以MOV指令有很多不同的变种以便在不同的存储单元之间移动不同的数据类型。
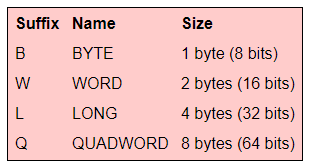
MOV和其他指令一样,有一个决定移动多大数据的单字母前缀:
不同数据有不同的寻址模式。全局值(全局变量和函数)的引用直接使用名字,例如x或者printf。
常数使用带有美元符号的立即数,例如$56。寄存器值的引用使用寄存器的名称,例如 %rbx.
间接寻址则是使用与寄存器中保存的地址值对应的内存中的值,例如,(%rsp) 表示%rsp指向的内存中的值。相对基址寻址,则是把一个常数加到寄存器值上,例如 -16(%rcx)表示把%rcx指向的地址前移16个字节后对应的内存值。寻址模式对于管理栈,局部变量,函数参数很重要。相对基址寻址有很多复杂变种,例如-16(%rbx,%rcx,8)表示-16+%rbx+%rcx*8对应的地址的内存值,这种寻址模式在访问元素大小特殊的数组时很有用。
如下是使用各种寻址模式加载一个64位值到%rax:

在大多数情况下,相同的寻址模式可用于将数据存储到寄存器和内存中。但是,并非所有模式都支持。例如,不可能对MOV的两个参数使用相对基址寻址:MOVQ -8(%rbx), -8(%rbx)。要查看是否支持寻址模式的组合,您需要阅读手册的相关说明。
基本算术
编译器会用到四个基本算术计算指令: 加ADD, 减SUB,乘 IMUL 和 除IDIV. ADD和SUB有两个操作数:
一个源操作数和一个目的操作数(会被改写).例如:
ADDQ %rbx, %rax把%rbx加到%rax,结果存在%rax中,会覆盖之前的值。所以你在使用寄存器的时候要小心,假设要翻译c = b*(b+a)(其中a和b是全局整数), 做加法时,需要小心不要把b的值破坏了。下面是一种翻译方式:
MOVQ a, %rax
MOVQ b, %rbx
ADDQ %rbx, %rax
IMULQ %rbx
MOVQ %rax, cIMUL 指令稍有不同:它把%rax的值乘以操作数,把结果的低64位存在%rax,高64位放在%rdx (两个64位值相乘的结果是128位)。IDIV则相反,把128bit值(低64位在 %rax ,高64位在%rdx)除以指令中的操作数(为了正确处理负数,用CDQO 指令把%rax符号扩展到%rdx),商存储在%rax,余数在%rdx。
MOVQ a, %rax # set the low 64 bits of the dividend
CDQO # sign-extend %rax into %rdx
IDIVQ $5 # divide %rdx:%rax by 5, leaving result in %eax很多编程语言中的取模指令只使用了%rdx中的余数。
INC和DEC会把寄存器的值破坏掉。例如,语句a = ++b 可以这样翻译:
MOVQ b, %rax
INCQ %rax
MOVQ %rax, a布尔操作的工作方式类似:AND, OR, 和XOR以及NOT也会破坏寄存器的值。像MOV指令一样,算术指令也可以使用多种寻址模式。对编译器来说,最方便的做法是用MOV把值加载到寄存器中,然后用寄存器来做算术运算。
小贴士: 浮点数
我们不讨论浮点数操作细节,只需要知道它们使用一套不同的指令和寄存器。在老式机器上,浮点指令是使用可选的外部8087 FPU处理的,所以被称作X87操作,虽然现在已经集成到了CPU里面。X87 FPU包含
8个排列在栈中的80位寄存器(R0-R7)。做浮点算术前,代码必须先把数据push到FPU栈,然后操作栈顶的数据,并回写到内存。内存中双精度浮点数是以64位的长度存储的。这种架构的一个奇怪的地方是,FPU的精度是80位,比内存中的存储方式精度高。结果,浮点计算的值会改变,取决于数据在内存和寄存器之间移动的具体顺序。
浮点数数学计算比它看上去要难懂,推荐阅读:
1. Intel 手册8-1章节。
2. 计算机科学家必知之浮点数
3. 程序员必知之浮点数
比较和跳转
使用JMP指令,我们可以构造一个无限循环,%eax 开始计数:
MOVQ $0, %rax
loop:
INCQ %rax
JMP loop为了定义更有用的结构,例如终结循环和if-then语句,我们需要根据变量值改变程序流程。在大多数汇编语言中,这使用两种不同的指令达到,即比较(compare)和跳转(jump)。
所有的比较都是使用CMP指令。CMP指令比较两个不同的寄存器中的值,设置EFLAGS寄存器的比特位,记录下结果(大于,小于还是等于)。使用带条件的跳转指令根据EFLAGS完成相应跳转:

下面是一个循环,%rax 从0累加到5:
MOVQ $0, %rax
loop:
INCQ %rax
CMPQ $5, %rax
JLE loop条件赋值:如果x大于0,全部变量y设置为10,否则,设置为20:
MOVQ x, %rax
CMPQ $0, %rax
JLE twenty
ten:
MOVQ $10, %rbx
JMP done
twenty:
MOVQ $20, %rbx
JMP done
done:
MOVQ %ebx, y注意,JMP指令需要编译器生成目标标签(LABEL)。标签必须唯一,并且是汇编文件内部私有,对外部不可见,除非有.globl指示。按C语言的说法,汇编中没有修饰的标签是static的,.globl修饰的标签是extern的。
栈 statck
栈是一个辅助的数据结构,主要用来记录函数的调用历史和相关的局部变量(没有放到寄存器的)。一般栈是从高地址到低地址向下生长的。%rsp是栈指针,指向栈最底部(其实是平常所说的栈顶)元素。所以,push %rax(8字节),会把%rsp减去8,并把%rax写到 %rsp指向的位置。
SUBQ $8, %rsp
MOVQ %rax, (%rsp)pop则刚好相反:
MOVQ (%rsp), %rax
ADDQ $8, %rsp要丢弃最后压入栈中的值,只需要修改%rsp的值即可:
ADDQ $8, %rsp 当然,由于压栈和出栈非常常见,所以这两个操作有两个专有指令,他们的行为和上面描述的完全相同:
PUSHQ %rax
POPQ %rax函数调用 Calling Functions
C标准库中的所有函数汇编语言程序都可以使用。函数的调用有标准的方式,称为”调用约定(calling convention)” ,这样用各种语言编写的程序可以链接在一起。
在大多数汇编程序中(X86-64不是),调用约定是简单的把每个参数都压栈,然后调用函数。被调用的函数从栈中获取参数,完成操作,把返回值保存到寄存器中并返回。调用方再把参数从栈pop出来(其实X86 32就是这样的)。
X86-64的调用方式有些不同,称作System V ABI。整个约定相当复杂,下面是简化版,但对我们来说足够了:
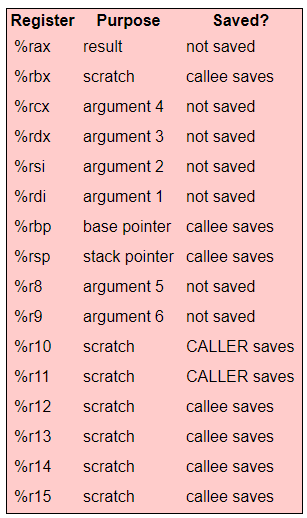
- 整数参数(包含指针)依次放在%rdi, %rsi, %rdx, %rcx, %r8, 和 %r9 寄存器中。
- 浮点参数依次放在寄存器%xmm0-%xmm7中。
- 寄存器不够用时,参数放到栈中。
- 可变参数哈函数(比如printf), 寄存器%eax需记录下浮点参数的个数。
- 被调用的函数可以使用任何寄存器,但它必须保证%rbx, %rbp, %rsp, and %r12-%r15恢复到原来的值(如果它改变了它们的值)。
- 返回值存储在 %eax中.
见下表:
调用函数前,先要把参数放到寄存器中。然后,调用方要把寄存器%r10 和%r11的值保存到栈中。之后,执行CALL指令,把IP指针的值保存到栈中,并跳到函数的起始地址执行。从函数返回后,恢复%r10 和%r11,并从%eax获取返回值。
例如对下面的C代码段:
long x=0;
long y=10;
int main()
{
x = printf("value: %d",y);
}可以如下翻译:
.data
x:
.quad 0
y:
.quad 10
str:
.string "value: %d\n"
.text
.globl main
main:
MOVQ $str, %rdi # first argument in %rdi: string pointer
MOVQ y, %rsi # second argument in %rsi: value of y
MOVQ $0, %rax # there are zero floating point args
PUSHQ %r10 # save the caller-saved registers
PUSHQ %r11
CALL printf # invoke printf
POPQ %r11 # restore the caller-saved registers
POPQ %r10
MOVQ %rax, x # save the result in x
RET # return from main function定义一个简单的叶子函数(不调用其它函数)
因为参数在寄存器中,编写简单的算术函数并返回值很难容易。例如,对于如下函数的代码:
long square( long x )
{
return x*x;
}汇编代码很简单:
.global square
square:
MOVQ %rdi, %rax # copy first argument to %rax
IMULQ %rdi, %rax # multiply it by itself
# result is already in %rax
RET # return to caller不过这只是针对不调用其他函数的叶子函数,他可以用传参的寄存器来完成它的操作。编译器产生的函数一般都需要使用栈来保存和恢复寄存器:
定义一个复杂函数
一个全功能的函数必须能够调用其它函数并计算各种复杂度的表达式,返回到调用方时,必须恢复到原来的状态。考虑如下函数,它有三个参数和两个局部变量:
.globl func
func:
pushq %rbp # save the base pointer
movq %rsp, %rbp # set new base pointer
pushq %rdi # save first argument on the stack
pushq %rsi # save second argument on the stack
pushq %rdx # save third argument on the stack
subq $16, %rsp # allocate two more local variables
pushq %rbx # save callee-saved registers
pushq %r12
pushq %r13
pushq %r14
pushq %r15
### body of function goes here ###
popq %r15 # restore callee-saved registers
popq %r14
popq %r13
popq %r12
popq %rbx
movq %rbp, %rsp # reset stack to previous base pointer
popq %rbp # recover previous base pointer
ret # return to the caller
有很多东西要跟踪: 函数参数,返回值,局部计算使用的空间。因此,我们使用基址指针%rbp。 %rsp总是指向栈末端,新数据压栈的地方。%rbp则指向函数使用的栈空间的起始位置。%rbp 和 %rsp之间的空间称为函数的”栈帧(stack frame)” 或 “活动记录”。
还有一个问题:每个函数都需要一些寄存器来完成计算,可是,如果一个函数是在另外一个函数中被调用会怎么样呢?调用方(caller )的寄存器不能被被调用方(callee)破坏,所以,每个函数都要保存和恢复被它使用的寄存器的值,即:在调用前把寄存器压栈,调用返回后出栈。根据 System V ABI, 每个函数执行完毕后都要保护好%rsp, %rbp, %rbx, 和%r12-%r15 。
让我们看看函数func的栈内存布局:

%rbp指明了栈帧的开始。在函数体内,我们可以用%rbp基址相对寻址方式来引用参数和局部变量。参数0在 -8(%rbp)位置,参数1在 -16(%rbp),以此类推。 -32(%rbp) 对应局部变量,-48(%rbp)对应保存的寄存器。%rsp指向栈中最后一个元素。如果栈还要另作他用,则需要向更低地址的区域压栈。(注意:我们假设所有参数和变量都是8字节长度, 实际上不同的类型的长度不一样,对应的偏移也不一样)。
下面给个全面的例子。假设你有一个如下定义的C函数:
int func( int a, int b, int c )
{
int x, y;
x = a+b+c;
y = x*5;
return y;
}如下是一个保守的翻译:
.globl func
func:
##################### preamble of function sets up stack
pushq %rbp # save the base pointer
movq %rsp, %rbp # set new base pointer to esp
pushq %rdi # save first argument (a) on the stack
pushq %rsi # save second argument (b) on the stack
pushq %rdx # save third argument (c) on the stack
subq $16, %rsp # allocate two more local variables
pushq %rbx # save callee-saved registers
pushq %r12
pushq %r13
pushq %r14
pushq %r15
######################## body of function starts here
movq -8(%rbp), %rbx # load each arg into a scratch register
movq -16(%rbp), %rcx
movq -24(%rbp), %rdx
addq %rdx, %rcx # add the args together
addq %rcx, %rbx
movq %rbx, -32(%rbp) # store the result into local 0 (x)
movq -32(%rbp), %rbx # load local 0 (x) into a scratch register.
imulq $5, %rbx # multiply it by 5
movl %rbx, -40(%ebp) # store the result in local 1 (y)
movl -20(%ebp), %eax # move local 1 (y) into the result register
#################### epilogue of function restores the stack
popq %r15 # restore callee-saved registers
popq %r14
popq %r13
popq %r12
popq %rbx
movq %rbp, %rsp # reset stack to base pointer.
popq %rbp # restore the old base pointer
ret # return to caller编译优化
返回去看,上面例子都有很多方式进行优化。比如,特定的代码不使用 %rbx-%r15的时候,就不需要保存。可以把参数保留在寄存器中,而不是压栈。返回值可以直接使用%eax计算,而不是保存到局部变量。手工写代码时,完成这些优化很容易,但是对编译器来说就不这么简单了。
第一次尝试构建编译器时,生成的代码不会很高效,因为每个语句都是独立翻译的。函数先是把所有寄存器都保存起来,因为它不能预先知道哪些寄存器会被使用。语句的计算值会被保存到局部变量,因为不能预先知道这个局部变量会被当作返回值。
智能的编译器可以可以大大提高效率。用gcc编译C源代码时,用或者不用-O选项。仔细的检查生成的汇编代码,看看它是如何优化的。以后会讨论编译器的优化策略,现在,先确保你的编译器能生成保守但正确的代码,不用关注效率。














 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









