







关键字:Linux CentOS Java Scala Hive On Spark
版本号:CentOS7 JDK1.8 Scala2.11.8 Hive2.1.1 Spark-1.6.3-with-out-hive Hadoop2.8.0
概述
Hive默认的执行引擎是Hadoop提供的MapReduce,而MapReduce的缺点是读写磁盘太多,为了提高Hive执行某些SQL的效率,有必要将Hive的执行引擎替换为Spark,这就是Hive On Spark。不过Hive On Spark的环境搭建的确是有点麻烦,主要是因为Hive和Spark的版本不能随意搭配,首先Spark必须是without-hive版本才可以(编译时用特殊命令申明排除掉某些jar包)。要拥有这样的Spark的版本,你可以自己编译,但是要自己编译还得做很多准备工作,也是较为麻烦和费时的。其次拥有了without-hive版本的Spark,还得选择合适的Hive版本才可以,也就是说Hive和Spark必须使用恰当的版本,才能搭建Hive On Spark环境。
自己编译without-hive版本的Spark这里暂时不讲了,留在后面的博文中在说,本文先使用官方发布的without-hive版的Spark和官方发布的Hive版本来搭建Hive On Spark环境。
1 各个机器安装概况
3台机器是master、slave1、slave2,使用的操作系统是CentOS7(使用Ubuntu也可以,用为用的是压缩包,所以安装方法都一样),3台机器的信息如下表:
|
|
master |
slave1 |
slave2 |
| 内存 |
2G(越大越好) |
2G(越大越好) |
2G(越大越好) |
| IP地址 |
192.168.27.141 |
192.168.27.142 |
192.168.27.143 |
| 节点类型 |
Hadoop的namenode节点 Spark的master节点 |
Hadoop的datanode节点 Spark的slave节点 |
Hadoop的datanode节点 Spark的slave节点 |
| JAVA_HOME |
/opt/java/jdk1.8.0_121 |
/opt/java/jdk1.8.0_121 |
/opt/java/jdk1.8.0_121 |
| SCALA_HOME |
/opt/scala/scala-2.11.8 |
/opt/scala/scala-2.11.8 |
/opt/scala/scala-2.11.8 |
| HADOOP_HOME |
/opt/hadoop/hadoop-2.8.0 |
/opt/hadoop/hadoop-2.8.0 |
/opt/hadoop/hadoop-2.8.0 |
| SPARK_HOME |
/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive |
/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive |
opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive |
| HIVE_HOME |
/opt/hive/apache-hive-2.1.1-bin |
无需安装 |
无需安装 |
说明:在此强调一下,这里的Spark是spark-1.6.3-bin-hadoop2.4-without-hive而不是spark-1.6.3-bin-hadoop2.4,否则无法成功。Hadoop的版本倒是无所谓,用2.x基本上都可以的,我这里用的是2.8.0。
2 下载和解压缩各种包
3台机器分别需要安装什么东西,上面的表格已经很明确,下载、解压缩、配置即可,这里不详细讲怎么安装,只列出下载地址。
JDK的下载地址这里就不说了,Oracle这个流氓公司,还要求注册才能下载。
Scala-2.11.8的下载地址:
https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
Hadoop-2.8.0下载地址:
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
spark-1.6.3-bin-hadoop2.4-without-hive下载地址是:
http://mirror.bit.edu.cn/apache/spark/spark-1.6.3/spark-1.6.3-bin-hadoop2.4-without-hive.tgz
hive-2.1.1的下载地址是:
http://mirror.bit.edu.cn/apache/hive/stable-2/apache-hive-2.1.1-bin.tar.gz
JDK、SCALA、Hadoop、Spark、Hive的安装方法跟之前博文讲到的没什么不同,只是在Spark和Hive的配置上有一些不同,配置相关的东西,本博文下面会讲到,安装方法的话这里不细述了,有需要的可以参考下面列出的这些博文。
JDK安装参考(Ubuntu和CentOS都可以参考下面的博文):
http://blog.csdn.net/pucao_cug/article/details/68948639
Hadoop安装参考:
http://blog.csdn.net/pucao_cug/article/details/71698903
SCALA 和Spark的安装参考:
http://blog.csdn.net/pucao_cug/article/details/72353701
Hive的安装参考:
http://blog.csdn.net/pucao_cug/article/details/71773665
请分别按照上面提供的参考博文,将这几样东西都安装成功后,在参考下文提供的配置步骤来修改配置文件,然后运行Hive On Spark。
3 配置环境变量
编辑/etc/profile文件,编辑完成后执行source /etc/profile命令。
在master机器上添加:
export JAVA_HOME=/opt/java/jdk1.8.0_121
export SCALA_HOME=/opt/scala/scala-2.11.8
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export SPARK_HOME=/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive
export CLASSPATH=.:${JAVA_HOME}/lib:${SCALA_HOME}/lib:${HIVE_HOME}/lib:$CLASSPATH
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${HIVE_HOME}/bin:$PATH在slave机器上添加:
export JAVA_HOME=/opt/java/jdk1.8.0_121
export SCALA_HOME=/opt/scala/scala-2.11.8
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SPARK_HOME=/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive
export CLASSPATH=.:${JAVA_HOME}/lib:${SCALA_HOME}/lib:${HIVE_HOME}/lib:$CLASSPATH
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:$PATH4 修改hostname文件
4.1 在3台机器上执行hostname命令
分别编辑3太机器上的/etc/houstname文件,
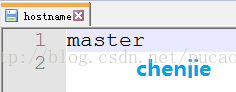
master机器上将该文件内容修改为master
如图:
在slave1机器上修改为slave1:
如图&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









